Elasticsearch分布式一致性原理剖析(三)-Data篇
本文首发于云栖社区(Elasticsearch分布式一致性原理剖析(三)-Data篇-博客-云栖社区-阿里云),由原作者转载。
前言
“Elasticsearch分布式一致性原理剖析”系列将会对Elasticsearch的分布式一致性原理进行详细的剖析,介绍其实现方式、原理以及其存在的问题等(基于6.2版本)。前两篇文章介绍了ES中集群如何组成,master选举算法,master更新meta的流程等,并分析了选举、Meta更新中的一致性问题。本文会分析ES中的数据流,包括其写入流程、算法模型PacificA、SequenceNumber与Checkpoint等,并比较ES的实现与标准PacificA算法的异同。目录如下:
- 问题背景
- 数据写入流程
- PacificA算法
- SequenceNumber、Checkpoint与故障恢复
- ES与PacificA的比较
- 小结
问题背景
用过ES的同学都知道,ES中每个Index会划分为多个Shard,Shard分布在不同的Node上,以此来实现分布式的存储和查询,支撑大规模的数据集。对于每个Shard,又会有多个Shard的副本,其中一个为Primary,其余的一个或多个为Replica。数据在写入时,会先写入Primary,由Primary将数据再同步给Replica。在读取时,为了提高读取能力,Primary和Replica都会接受读请求。
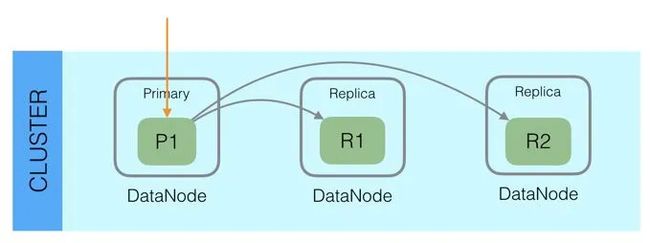
在这种模型下,我们能够感受到ES具有这样的一些特性,比如:
- 数据高可靠:数据具有多个副本。
- 服务高可用:Primary挂掉之后,可以从Replica中选出新的Primary提供服务。
- 读能力扩展:Primary和Replica都可以承担读请求。
- 故障恢复能力:Primary或Replica挂掉都会导致副本数不足,此时可以由新的Primary通过复制数据产生新的副本。
另外,我们也可以想到一些问题,比如:
- 数据怎么从Primary复制到Replica?
- 一次写入要求所有副本都成功吗?
- Primary挂掉会丢数据吗?
- 数据从Replica读,总是能读到最新数据吗?
- 故障恢复时,需要拷贝Shard下的全部数据吗?
可以看到,对于ES中的数据一致性,虽然我们可以很容易的了解到其大概原理,但是对其细节我们还有很多的困惑。那么本文就从ES的写入流程,采用的一致性算法,SequenceId和Checkpoint的设计等方面来介绍ES如何工作,进而回答上述这些问题。需要注意的是,本文基于ES6.2版本进行分析,可能很多内容并不适用于ES之前的版本,比如2.X的版本等。
数据写入流程
首先我们来看一下数据的写入流程,读者也可以阅读这篇文章来详细了解:Elasticsearch内核解析 - 写入篇 - 知乎。
Replication角度: Primary -> Replica
我们从大的角度来看,ES写入流程为先写入Primary,再并发写入Replica,最后应答客户端,流程如下:
- 检查Active的Shard数。
final String activeShardCountFailure = checkActiveShardCount();- 写入Primary。
primaryResult = primary.perform(request);- 并发的向所有Replicate发起写入请求
performOnReplicas(replicaRequest, globalCheckpoint, replicationGroup.getRoutingTable());- 等所有Replicate返回或者失败后,返回给Client。
private void decPendingAndFinishIfNeeded() {
assert pendingActions.get() > 0 : "pending action count goes below 0 for request [" + request + "]";
if (pendingActions.decrementAndGet() == 0) {
finish();
}
}上述过程在ReplicationOperation类的execute函数中,完整代码如下:
public void execute() throws Exception {
final String activeShardCountFailure = checkActiveShardCount();
final ShardRouting primaryRouting = primary.routingEntry();
final ShardId primaryId = primaryRouting.shardId();
if (activeShardCountFailure != null) {
finishAsFailed(new UnavailableShardsException(primaryId,
"{} Timeout: [{}], request: [{}]", activeShardCountFailure, request.timeout(), request));
return;
}
totalShards.incrementAndGet();
pendingActions.incrementAndGet(); // increase by 1 until we finish all primary coordination
primaryResult = primary.perform(request);
primary.updateLocalCheckpointForShard(primaryRouting.allocationId().getId(), primary.localCheckpoint());
final ReplicaRequest replicaRequest = primaryResult.replicaRequest();
if (replicaRequest != null) {
if (logger.isTraceEnabled()) {
logger.trace("[{}] op [{}] completed on primary for request [{}]", primaryId, opType, request);
}
// we have to get the replication group after successfully indexing into the primary in order to honour recovery semantics.
// we have to make sure that every operation indexed into the primary after recovery start will also be replicated
// to the recovery target. If we used an old replication group, we may miss a recovery that has started since then.
// we also have to make sure to get the global checkpoint before the replication group, to ensure that the global checkpoint
// is valid for this replication group. If we would sample in the reverse, the global checkpoint might be based on a subset
// of the sampled replication group, and advanced further than what the given replication group would allow it to.
// This would entail that some shards could learn about a global checkpoint that would be higher than its local checkpoint.
final long globalCheckpoint = primary.globalCheckpoint();
final ReplicationGroup replicationGroup = primary.getReplicationGroup();
markUnavailableShardsAsStale(replicaRequest, replicationGroup.getInSyncAllocationIds(), replicationGroup.getRoutingTable());
performOnReplicas(replicaRequest, globalCheckpoint, replicationGroup.getRoutingTable());
}
successfulShards.incrementAndGet(); // mark primary as successful
decPendingAndFinishIfNeeded();
}下面我们针对这个流程,来分析几个问题:
1. 为什么第一步要检查Active的Shard数?
ES中有一个参数,叫做waitforactiveshards,这个参数是Index的一个setting,也可以在请求中带上这个参数。这个参数的含义是,在每次写入前,该shard至少具有的active副本数。假设我们有一个Index,其每个Shard有3个Replica,加上Primary则总共有4个副本。如果配置waitforactiveshards为3,那么允许最多有一个Replica挂掉,如果有两个Replica挂掉,则Active的副本数不足3,此时不允许写入。
这个参数默认是1,即只要Primary在就可以写入,起不到什么作用。如果配置大于1,可以起到一种保护的作用,保证写入的数据具有更高的可靠性。但是这个参数只在写入前检查,并不保证数据一定在至少这些个副本上写入成功,所以并不是严格保证了最少写入了多少个副本。关于这一点,可参考以下官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-index_.html
...It is important to note that this setting greatly reduces the chances of the write operation not writing to the requisite number of shard copies, but it does not completely eliminate the possibility, because this check occurs before the write operation commences. Once the write operation is underway, it is still possible for replication to fail on any number of shard copies but still succeed on the primary. The _shards section of the write operation’s response reveals the number of shard copies on which replication succeeded/failed.2. 写入Primary完成后,为何要等待所有Replica响应(或连接失败)后返回
在更早的ES版本,Primary和Replica之间是允许异步复制的,即写入Primary成功即可返回。但是这种模式下,如果Primary挂掉,就有丢数据的风险,而且从Replica读数据也很难保证能读到最新的数据。所以后来ES就取消异步模式了,改成Primary等Replica返回后再返回给客户端。
因为Primary要等所有Replica返回才能返回给客户端,那么延迟就会受到最慢的Replica的影响,这确实是目前ES架构的一个弊端。之前曾误认为这里是等waitforactive_shards个副本写入成功即可返回,但是后来读源码发现是等所有Replica返回的。
https://github.com/elastic/elasticsearch/blob/master/docs/reference/docs/data-replication.asciidoc
... Once all replicas have successfully performed the operation and responded to the primary, the primary acknowledges the successful completion of the request to the client.如果Replica写入失败,ES会执行一些重试逻辑等,但最终并不强求一定要在多少个节点写入成功。在返回的结果中,会包含数据在多少个shard中写入成功了,多少个失败了:
{
"_shards" : {
"total" : 2,
"failed" : 0,
"successful" : 2
}
}3. 如果某个Replica持续写失败,用户是否会经常查到旧数据?
这个问题是说,假如一个Replica持续写入失败,那么这个Replica上的数据可能落后Primary很多。我们知道ES中Replica也是可以承担读请求的,那么用户是否会读到这个Replica上的旧数据呢?
答案是如果一个Replica写失败了,Primary会将这个信息报告给Master,然后Master会在Meta中更新这个Index的InSyncAllocations配置,将这个Replica从中移除,移除后它就不再承担读请求。在Meta更新到各个Node之前,用户可能还会读到这个Replica的数据,但是更新了Meta之后就不会了。所以这个方案并不是非常的严格,考虑到ES本身就是一个近实时系统,数据写入后需要refresh才可见,所以一般情况下,在短期内读到旧数据应该也是可接受的。
ReplicationOperation.java,写入Replica失败的OnFailure函数:
public void onFailure(Exception replicaException) {
logger.trace(
(org.apache.logging.log4j.util.Supplier) () -> new ParameterizedMessage(
"[{}] failure while performing [{}] on replica {}, request [{}]",
shard.shardId(),
opType,
shard,
replicaRequest),
replicaException);
if (TransportActions.isShardNotAvailableException(replicaException)) {
decPendingAndFinishIfNeeded();
} else {
RestStatus restStatus = ExceptionsHelper.status(replicaException);
shardReplicaFailures.add(new ReplicationResponse.ShardInfo.Failure(
shard.shardId(), shard.currentNodeId(), replicaException, restStatus, false));
String message = String.format(Locale.ROOT, "failed to perform %s on replica %s", opType, shard);
replicasProxy.failShardIfNeeded(shard, message,
replicaException, ReplicationOperation.this::decPendingAndFinishIfNeeded,
ReplicationOperation.this::onPrimaryDemoted, throwable -> decPendingAndFinishIfNeeded());
}
}
调用failShardIfNeeded:
public void failShardIfNeeded(ShardRouting replica, String message, Exception exception,
Runnable onSuccess, Consumer onPrimaryDemoted, Consumer onIgnoredFailure) {
logger.warn((org.apache.logging.log4j.util.Supplier)
() -> new ParameterizedMessage("[{}] {}", replica.shardId(), message), exception);
shardStateAction.remoteShardFailed(replica.shardId(), replica.allocationId().getId(), primaryTerm, message, exception,
createListener(onSuccess, onPrimaryDemoted, onIgnoredFailure));
}
shardStateAction.remoteShardFailed向Master发送请求,执行该Replica的ShardFailed逻辑,将Shard从InSyncAllocation中移除。
public void shardFailed(ShardRouting failedShard, UnassignedInfo unassignedInfo) {
if (failedShard.active() && unassignedInfo.getReason() != UnassignedInfo.Reason.NODE_LEFT) {
removeAllocationId(failedShard);
if (failedShard.primary()) {
Updates updates = changes(failedShard.shardId());
if (updates.firstFailedPrimary == null) {
// more than one primary can be failed (because of batching, primary can be failed, replica promoted and then failed...)
updates.firstFailedPrimary = failedShard;
}
}
}
if (failedShard.active() && failedShard.primary()) {
increasePrimaryTerm(failedShard.shardId());
}
} ES中维护InSyncAllocation的做法,是遵循的PacificA算法,下一节会详述。
Primary自身角度
从Primary自身的角度,一次写入请求会先写入Lucene,然后写入translog。具体流程可以看这篇文章:Elasticsearch内核解析 - 写入篇 - 知乎 。
1. 为什么要写translog?
translog类似于数据库中的commitlog,或者binlog。只要translog写入成功并flush,那么这笔数据就落盘了,数据安全性有了保证,Segment就可以晚一点落盘。因为translog是append方式写入,写入性能也会比随机写更高。
另一方面是,translog记录了每一笔数据更改,以及数据更改的顺序,所以translog也可以用于数据恢复。数据恢复包含两方面,一方面是节点重启后,从translog中恢复重启前还未落盘的Segment数据,另一方面是用于Primary和新的Replica之间的数据同步,即Replica逐步追上Primary数据的过程。
2. 为什么先写Lucene,再写translog?
写Lucene是写入内存,写入后在内存中refresh即可读到,写translog是落盘,为了数据持久化以及恢复。正常来讲,分布式系统中是先写commitLog进行数据持久化,再在内存中apply这次更改,那么ES为什么要反其道而行之呢?主要原因大概是写入Lucene时,Lucene会再对数据进行一些检查,有可能出现写入Lucene失败的情况。如果先写translog,那么就要处理写入translog成功但是写入Lucene一直失败的问题,所以ES采用了先写Lucene的方式。
PacificA算法
PacificA是微软亚洲研究院提出的一种用于日志复制系统的分布式一致性算法,论文发表于2008年(PacificA paper)。ES官方明确提出了其Replication模型基于该算法:
https://github.com/elastic/elasticsearch/blob/master/docs/reference/docs/data-replication.asciidoc
Elasticsearch’s data replication model is based on the primary-backup model and is described very well in the PacificA paper of Microsoft Research. That model is based on having a single copy from the replication group that acts as the primary shard. The other copies are called replica shards. The primary serves as the main entry point for all indexing operations. It is in charge of validating them and making sure they are correct. Once an index operation has been accepted by the primary, the primary is also responsible for replicating the operation to the other copies.网上讲解这个算法的文章较少,因此本文根据PacificA的论文,简单介绍一下这个算法。该算法具有以下几个特点:
- 强一致性。
- 单Primary向多Secondary的数据同步模式。
- 使用额外的一致性组件维护Configuration。
- 少数派Replica可用时仍可写入。
一些名词
首先我们介绍一下算法中的一些名词:
- Replica Group:一个互为副本的数据集合叫做Replica Group,每个副本是一个Replica。一个Replica Group中只有一个副本是Primary,其余为Secondary。
- Configuration:一个Replica Group的Configuration描述了这个Replica Group包含哪些副本,其中Primary是谁等。
- Configuration Version:Configuration的版本号,每次Configuration发生变更时加1。
- Configuration Manager: 管理Configuration的全局组件,其保证Configuration数据的一致性。Configuration变更会由某个Replica发起,带着Version发送给Configuration Manager,Configuration Manager会检查Version是否正确,如果不正确则拒绝更改。
- Query & Update:对一个Replica Group的操作分为两种,Query和Update,Query不会改变数据,Update会更改数据。
- Serial Number(sn):代表每个Update操作执行的顺序,每次Update操作加1,为连续的数字。
- Prepared List:Update操作的准备序列。
- Committed List:Update操作的提交序列,提交序列中的操作一定不会丢失(除非全部副本挂掉)。在同一个Replica上,Committed List一定是Prepared List的前缀。
Primary Invariant
在PacificA算法中,要求采用某种错误检测机制来满足以下不变式:
Primary Invariant: 任何时候,当一个Replica认为自己是Primary时,Configuration Manager中维护的Configuration也认为其是当前的Primary。任何时候,最多只有一个Replica认为自己是这个Replica Group的Primary。
Primary Invariant保证了当一个节点认为自己是Primary时,其肯定是当前的Primary。如果不能满足Primary Invariant,那么Query请求就可能发送给Old Primary,读到旧的数据。
怎么保证满足Primary Invariant呢?论文给出的一种方法是通过Lease机制,这也是分布式系统中常用的一种方式。具体来说,Primary会定期获取一个Lease,获取之后认为某段时间内自己肯定是Primary,一旦超过这个时间还未获取到新的Lease就退出Primary状态。只要各个机器的CPU不出现较大的时钟漂移,那么就能够保证Lease机制的有效性。
论文中实现Lease机制的方式是,Primary定期向所有Secondary发送心跳来获取Lease,而不是所有节点都向某个中心化组件获取Lease。这样的好处是分散了压力,不会出现中心化组件故障而导致所有节点失去Lease的情况。
Query
Query流程比较简单,Query只能发送给Primary,Primary根据最新commit的数据,返回对应的值。由于算法要求满足Primary Invariant,所以Query总是能读到最新commit的数据。
Update
Update流程如下:
- Primary分配一个Serial Number(简称sn)给一个UpdateRequest。
- Primary将这个UpdateRequest加入自己的Prepared List,同时向所有Secondary发送Prepare请求,要求将这个UpdateRequest加入Prepared List。
- 当所有Replica都完成了Prepare,即所有Replica的Prepared List中都包含了该Update请求时,Primary开始Commit这个请求,即将这个UpdateRequest放入Committed List中,同时Apply这个Update。需要注意的是,同一个Replica上,Committed List永远是Prepared List的前缀,所以Primary实际上是提高Committed Point,把这个Update Request包含进来。
- 返回客户端,Update操作成功。
当下一次Primary向Secondary发送请求时,会带上Primary当前的Committed Point,此时Secondary才会提高自己的Committed Point。
从Update流程我们可以得出以下不变式:
Commited Invariant
我们把某一个Secondary的Committed List记为SecondaryCommittedList,其Prepared List记为SecondaryPreparedList,把Primary的Committed List记为PrimaryCommittedList。
Commited Invariant:SecondaryCommittedList一定是PrimaryCommittedList的前缀,PrimaryCommittedList一定是SecondaryPreparedList的前缀。
Reconfiguration:Secondary故障,Primary故障,新加节点
1. Secondary故障
当一个Secondary故障时,Primary向Configuration Manager发起Reconfiguration,将故障节点从Replica Group中删除。一旦移除这个Replica,它就不属于这个Replica Group了,所有请求都不会再发给它。
假设某个Primary和Secondary发生了网络分区,但是都可以连接Configuration Manager。这时候Primary会检测到Secondary没有响应了,Secondary也会检测到Primary没有响应。此时两者都会试图发起Reconfiguration,将对方从Replica Group中移除,这里的策略是First Win的原则,谁先到Configuration Manager中更改成功,谁就留在Replica Group里,而另外一个已经不属于Replica Group了,也就无法再更新Configuration了。由于Primary会向Secondary请求一个Lease,在Lease有效期内Secondary不会执行Reconfiguration,而Primary的探测间隔必然是小于Lease时间的,所以我认为这种情况下总是倾向于Primary先进行Reconfiguration,将Secondary剔除。
2. Primary故障
当一个Primary故障时,Secondary会收不到Primary的心跳,如果超过Lease的时间,那么Secondary就会发起Reconfiguration,将Primary剔除,这里也是First Win的原则,哪个Secondary先成功,就会变成Primary。
当一个Secondary变成Primary后,需要先经过一个叫做Reconciliation的阶段才能提供服务。由于上述的Commited Invariant,所以原先的Primary的Committed List一定是新的Primary的Prepared List的前缀,那么我们将新的Primary的Prepared List中的内容与当前Replica Group中的其他节点对齐,相当于把该节点上未Commit的记录在所有节点上再Commit一次,那么就一定包含之前所有的Commit记录。即以下不变式:
Reconfiguration Invariant:当一个新的Primary在T时刻完成Reconciliation时,那么T时刻之前任何节点(包括原Primary)的Commited List都是新Primary当前Commited List的前缀。
Reconfiguration Invariant表明了已经Commit的数据在Reconfiguration过程中不会丢。
3. 新加节点
新加的节点需要先成为Secondary Candidate,这时候Primary就开始向其发送Prepare请求,此时这个节点还会追之前未同步过来的记录,一旦追平,就申请成为一个Secondary,然后Primary向Configuration Manager发起配置变更,将这个节点加入Replica Group。
还有一种情况时,如果一个节点曾经在Replica Group中,由于临时发生故障被移除,现在需要重新加回来。此时这个节点上的Commited List中的数据肯定是已经被Commit的了,但是Prepared List中的数据未必被Commit,所以应该将未Commit的数据移除,从Committed Point开始向Primary请求数据。
算法总结
PacificA是一个读写都满足强一致性的算法,它把数据的一致性与配置(Configuration)的一致性分开,使用额外的一致性组件(Configuration Manager)维护配置的一致性,在数据的可用副本数少于半数时,仍可以写入新数据并保证强一致性。
ES在设计上参考了PacificA算法,其通过Master维护Index的Meta,类似于论文中的Configuration Manager维护Configuration。其IndexMeta中的InSyncAllocationIds代表了当前可用的Shard,类似于论文中维护Replica Group。下一节我们会介绍ES中的SequenceNumber和Checkpoint,这两个类似于PacificA算法中的Serial Number和Committed Point,在这一节之后,会再有一节来比较ES的实现与PacificA的异同。
SequenceNumber、Checkpoint与故障恢复
上面介绍了ES的一致性算法模型PacificA,该算法很重要的一点是每个Update操作都会有一个对应的Serial Number,表示执行的顺序。在之前的ES版本中,每个写入操作并没有类似Serial Number的东西,所以很多事情做不了。在15年的时候,ES官方开始规划给每个写操作加入SequenceNumber,并设想了很多应用场景。具体信息可以参考以下两个链接:
Add Sequence Numbers to write operations #10708
Sequence IDs: Coming Soon to an Elasticsearch Cluster Near You
下面我们简单介绍一下Sequence、Checkpoint是什么,以及其应用场景。
Term和SequenceNumber
每个写操作都会分配两个值,Term和SequenceNumber。Term在每次Primary变更时都会加1,类似于PacificA论文中的Configuration Version。SequenceNumber在每次操作后加1,类似于PacificA论文中的Serial Number。
由于写请求总是发给Primary,所以Term和SequenceNumber会由Primary分配,在向Replica发送同步请求时,会带上这两个值。
LocalCheckpoint和GlobalCheckpoint
LocalCheckpoint代表本Shard中所有小于该值的请求都已经处理完毕。
GlobalCheckpoint代表所有小于该值的请求在所有的Replica上都处理完毕。GlobalCheckpoint会由Primary进行维护,每个Replica会向Primary汇报自己的LocalCheckpoint,Primary根据这些信息来提升GlobalCheckpoint。
GlobalCheckpoint是一个全局的安全位置,代表其前面的请求都被所有Replica正确处理了,可以应用在节点故障恢复后的数据回补。另一方面,GlobalCheckpoint也可以用于Translog的GC,因为之前的操作记录可以不保存了。不过ES中Translog的GC策略是按照大小或者时间,好像并没有使用GlobalCheckpoint。
快速故障恢复
当一个Replica故障时,ES会将其移除,当故障超过一定时间,ES会分配一个新的Replica到新的Node上,此时需要全量同步数据。但是如果之前故障的Replica回来了,就可以只回补故障之后的数据,追平后加回来即可,实现快速故障恢复。实现快速故障恢复的条件有两个,一个是能够保存故障期间所有的操作以及其顺序,另一个是能够知道从哪个点开始同步数据。第一个条件可以通过保存一定时间的Translog实现,第二个条件可以通过Checkpoint实现,所以就能够实现快速的故障恢复。这是SequenceNumber和Checkpoint的第一个重要应用场景。
ES与PacificA的比较
相同点
- Meta一致性和Data一致性分开处理:PacificA中通过Configuration Manager维护Configuration的一致性,ES中通过Master维护Meta的一致性。
- 维护同步中的副本集合:PacificA中维护Replica Group,ES中维护InSyncAllocationIds。
- SequenceNumber:在PacificA和ES中,写操作都具有SequenceNumber,记录操作顺序。
不同点
不同点主要体现在ES虽然遵循PacificA,但是目前其实现还有很多地方不满足算法要求,所以不能保证严格的强一致性。主要有以下几点:
- Meta一致性:上一篇中分析了ES中Meta一致性的问题,可以看到ES并不能完全保证Meta一致性,因此也必然无法严格保证Data的一致性。
- Prepare阶段:PacificA中有Prepare阶段,保证数据在所有节点Prepare成功后才能Commit,保证Commit的数据不丢,ES中没有这个阶段,数据会直接写入。
- 读一致性:ES中所有InSync的Replica都可读,提高了读能力,但是可能读到旧数据。另一方面是即使只能读Primary,ES也需要Lease机制等避免读到Old Primary。因为ES本身是近实时系统,所以读一致性要求可能并不严格。
小结
本文分析了ES中数据流的一致性问题,可以看到ES最近几年在这一块有很多进展,但也存在许多问题。本文是Elasticsearch分布式一致性原理剖析的最后一篇文章,该系列文章是对ES的一个调研分析总结,逐步分析了ES中的节点发现、Master选举、Meta一致性、Data一致性等,对能够读完该系列文章的同学说一声感谢,期待与大家的交流。
Reference
Index API | Elasticsearch Reference [6.2]
Reading and Writing documents | Elasticsearch Reference [6.2]
PacificA: Replication in Log-Based Distributed Storage Systems
Add Sequence Numbers to write operations #10708
Sequence IDs: Coming Soon to an Elasticsearch Cluster Near You