
为什么中文名称的图片打开后网址是一串乱码?为什么好好的短网址复制粘贴就变长了一大长串?罪魁祸首居然是……
杭州终于出梅了!二狗子看到气象台发布的消息,开心的不得了。杭州的雨从五月底一直下,每天除了雨还是雨,天空都是灰蒙蒙的,都快把人搞抑郁了。出梅了,天晴了,二狗子的心也随着蓝天上的白云飘荡出去了。
同事小峰峰告诉二狗子,公司后边的皇后公园,向日葵开的正好,一大片一大片的绵延出去,阳光下金灿灿的,可好看了。“要不要一起去看看?你拍点照片给婷婷呗~”
二狗子一想起女神婷婷很喜欢向日葵,拍点美丽的照片,能看到婷婷甜甜的笑,就迫不及待地拉着小峰峰往公园跑。

二狗子拍了好多照片,精挑细选了好几张,上传到自己的图片网站了。他用浏览器打开图片看了看,没有问题,非常完美,就复制了图片地址发给婷婷。
二狗子有点尴尬,明明在浏览器中是正常显示的 URL 地址,怎么复制出来就变成一堆奇怪的字符了呢?
二狗子百思不得其解,得,还是问一下自己的存储服务商——无所不能的又拍云吧。
客服乔巴接待了二狗子,并告诉了二狗子这个问题的由来。
URL - 网络资源定位符
通过互联网来访问网络中资源的时候,最常见就是通过浏览器输入资源的 URL 地址来进行访问。
URL(Uniform Resource Locator),是互联网中的一个核心概念,官方名称叫做统一资源定位符。简单的来说,URL 就是一个由网站开发者给资源在互联网上分配的地址。一般来说,每个有效的 URL 都指向单独的一个资源,这个资源可以是HTML 页面、CSS 文档,又或者是一幅图像等。
一个 URL 由不同的部分组成,其中一些是必须的,而另一些是可选的。下面我们来看下 URL 的具体组成部分:
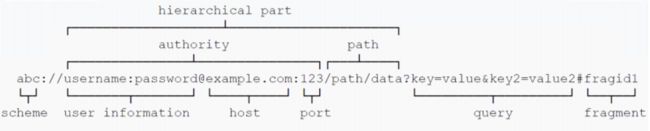
上图就是完整的 URL 结构展示。很多时候其中的一些部分是用不到的,例如 user information。作为参考,我们可以来看一下又拍云存储的 URL 地址。
https://www.upyun.com/product...
- https:// ,请求协议(scheme),指定了浏览器需要使用何种协议来与目标服务器进行通讯。常见的协议有 HTTP 和 HTTPS。
- www.upyun.com,域名(host),表明请求的资源所在的服务器地址。
- /products/file-storage ,资源路径地址(path),服务器通过路径来确认访问资源在服务器上的哪个位置。
一般常见的 URL 地址由这三个部分组成,其余的部分根据开发的需要,可以进行自定义。
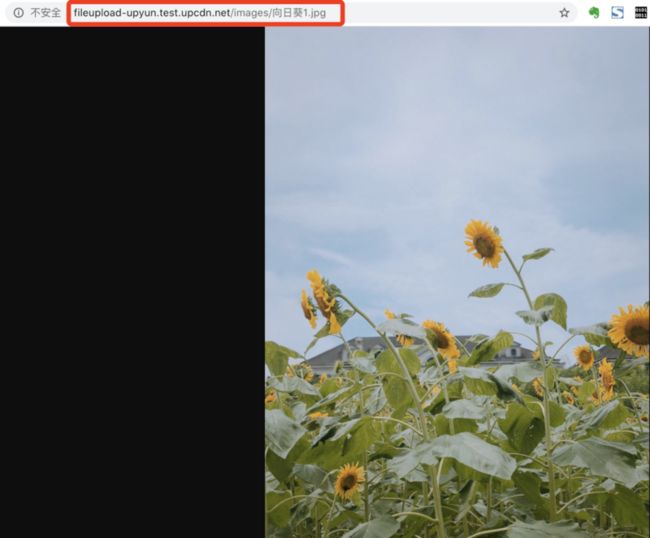
了解 URL 的概念后,就知道二狗子的图片链接 http://fileupload-upyun.test.... 的由来了。通过这个地址,婷婷可以访问到二狗子服务器上拍摄的向日葵图片。但是,为什么二狗子复制了浏览器地址栏中的地址,发送给婷婷的时候,URL 却变成了 http://fileupload-upyun.test.... 了呢?
{kind=link}
奇怪的字符 - URL 编码
我们可以看到,二狗子发给婷婷的链接,改变了的部分属于 URL 的 path 部分,而且,英文部分其实没有改动,只有中文的部分被转成 %XX 的这种编码格式了。
虽然,这不会影响图片的打开,地址依旧是有效的。但是为什么浏览器要把中文转换成这种奇怪的形式呢?
我们先来看一个例子。如果访问下面这个 URL 链接:
https://www.baidu.com/s?wd=?#!
这是使用百度进行搜索的一个链接,/s 后面跟着的 ? 代表请求参数(query),也就是我们想向请求的服务器提交一些参数。wd 为百度规定的查询参数名,wd 后边跟着的就是需要搜索的内容。
我们想搜索 ?#! 这个内容,可是当你复制这个链接放在浏览器中打开时,会发现一个问题,百度仅仅是搜索了 ? 这个内容,#! 不见了。
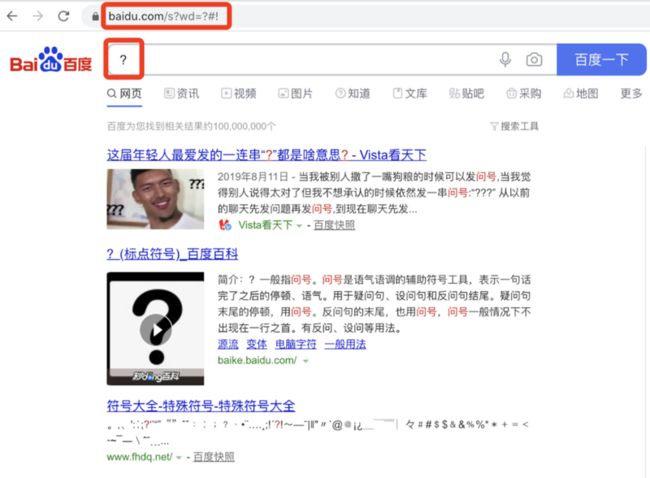
为什么呢?如果你仔细看上面那张 URL 的构成图,会发现 URL 结构中还有一个锚点(fragment)的部分,分隔符号就是 #。
所以这里就会出现一个问题,我们的业务需求是将 # 当做一个普通文本来进行搜索,但是 # 在 URL 中有特定的意思,所以浏览器就遇到了一个解释歧义的问题。

这就引申出一个问题,URL 在数据传递中,如果存在用作分隔符等特殊作用的保留字符怎么办?
在实际的业务场景中,会经常碰到一些在 URL 中有歧义性的数据,为了避免解释错误,开发者想出了一个解决方法,就是对这些数据进行一定的处理,从而解决歧义的问题。处理的方法有很多种,最常用的处理方式,就是对歧义性的数据进行 URL 百分号编码。
哪些是会引起歧义的数据呢?
根据 RFC 3986(https://tools.ietf.org/html/r...)的规定,我们可以得到下面的结果。
- 不在 ASCII 码范围内的字符 (URL 使用 ASCII 码进行编解码)
- ASCII 码中不可显示的字符
- URL 中规定的保留字符
- 不安全字符(传输环节中可能会被不正确处理),如空格、引号、尖括号等
保留字符由组件分隔符(gen-delims)和子组件分隔符(sub-delims)组成,这些字符在 URL 中都有特殊的意义:
Reserved = gen-delims / sub-delims
- gen-delims = ":" / "/" / "?" / "#" / "[" / "]" / "@"
- sub-delims = "!" / "$" / "&" / "'" / "(" / ")" / "*" / "+" / "," / ";" / "="
URL 中可以直接使用的非保留字符则有:
Unreserved = ALPHA / DIGIT / "-" / "." / "_" / "~"
- ALPHA:%41 - %5A AND %61 - %7A (英文字母大写 A-Z 以及英文字小写 a-z)
- DIGIT:%30 - %39 (数字 0-9)
- -: %2D .: %2E _: %5F
- ~: %7E (某些服务实现将其作为保留字符,一般也需要进行编码处理)
这下子我们就了解了,为什么 URL 中有时会出现奇怪的字符,很多时候浏览器会自动帮我们做编码和解码的操作。就像“向日葵”的 URL 一样,中文部分因为并不在 ASCII 码中,于是浏览器进行 URL 百分号编码的形式来进行访问。

(又拍云服务名的合法范围就是在非保留字符中获取,而不能指定为任意字符)
编码的形式
最常见的编码形式就是百分号编码(pct-encoded),这也是浏览器默认的编码形式。
pct-encoded = "%" HEXDIG HEXDIG
百分号编码一个保留字符, 首先需要把该字符的 ASCII 的值表示为两个 16 进制的值, 然后在其前面放置转义字符(%)。对于非 ASCII 字符, 则需要转换为 UTF-8 字节序, 然后每个字节按照上述方式表示。

(感兴趣的同学可以参考百分号编码 https://zh.wikipedia.org/zh-h... 条目)
各个编程语言中也有相对应的方法可以进行百分号编码,例如 JavaScript 中就提供了多种编码方法,常用的有 encodeURI 和 encodeURIComponent 两个方法。

乔巴说,在日常开发使用中,我们使用的开发库对 URL 编码的判断标准可能并不相同,这是因为这些库所面临的网络环境中,对于特殊字符的安全处理策略各有判断,这也会导致 URL 中如果存在一些特殊字符,开发、访问过程中可能就会出现一些奇怪的问题。在这里也建议大家使用非保留字符来设计自己程序中 URL 部分,避免一些不必要的 BUG 产生。
听完乔巴的介绍,二狗子终于明白了为啥 URL 中出现这些奇怪的字符了。嘿嘿,这下可以和婷婷解释 URL 为什么这么长咯。
