hadoop,WordCount,大厂面试题,手撸mapreduce 单词统计
有的大厂面试需要你手撸一个wordcount的例子,今天我们就从头到尾现一遍
1.在开始编程工作之前,先要规划好wordcount的步骤,规划的流程图和mapreduce原理如下:
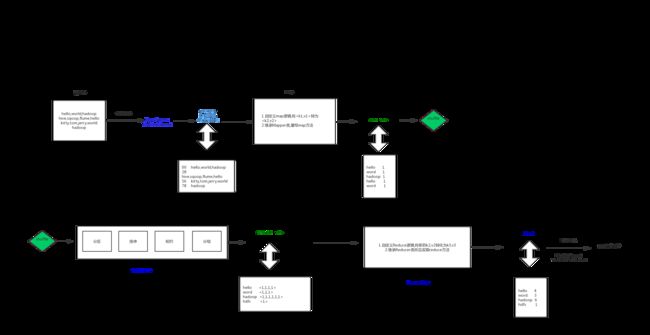
2.前期准备
(1) 启动hadoop和日志

(2).准备要处理的文件,并上传到hdfs分布式文件系统中

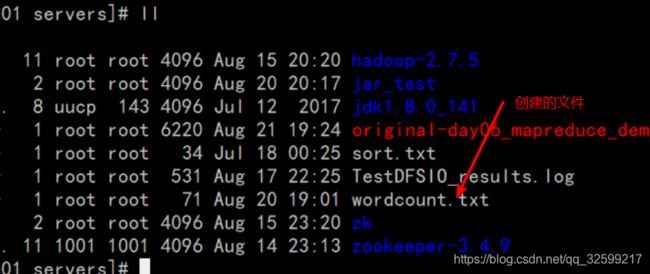
(3) 将文件上传到hdfs文件系统中
hdfs dfs -mkdir /wordcount/
hdfs dfs -put wordcount.txt /wordcount/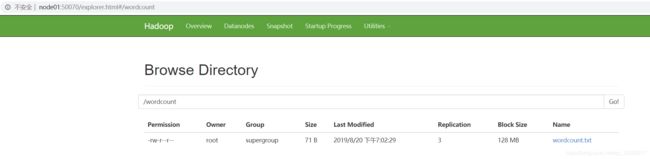
3.自定义mapper
package com.alibaba.mapreduce;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author Jiapeng Pang
* @Position 大数据工程师
* @date 2019/8/20 19:12.
*/
public class WordCountMapper extends Mapper{
//map方法就是将转为
/**
* @param key k1 行偏移量
* @param value v1 每一行的文本数据
* @param context 上下文对象,传递
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Text text = new Text();
LongWritable longWritable = new LongWritable();
//1.将一行的文本数据进行拆分
String[] split = value.toString().split(",");
//2.遍历数组,组装v2和k2
for (String word : split) {
text.set(word);
longWritable.set(1);
//3.将k2和v2 传入上下文中
context.write(text,longWritable);
}
}
}
4.自定义reduce
package com.alibaba.mapreduce;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author Jiapeng Pang
* @Position 大数据工程师
* @date 2019/8/20 19:32.
*
* KEYIN k2
* VALUEIN v2
* KEYOUT k3
* VALUEOUT v3
*
*/
public class wordCountReducer extends Reducer {
//将新的k2,v2转为k3和v3,将k3和v3写入上下文中
/**
*
* @param key 新k2
* @param values 新v2
* @param context 上下文对象
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
long count=0;
//遍历集合,将集合中的数字相加,得到v3
for (LongWritable value : values) {
count+=value.get();
}
context.write(key,new LongWritable(count));
//将k3和v3写入上下文中
}
}
5.编写主代码
package com.alibaba.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.net.URI;
/**
* @author Jiapeng Pang
* @Position 大数据工程师
* @date 2019/8/20 19:44.
*/
public class JobMain extends Configured implements Tool {
//指定一个job任务
@Override
public int run(String[] strings) throws Exception {
//1.创建一个job任务对象
Job job = Job.getInstance(super.getConf(), "wordcount");
//如果打包运行出错,需要加入该配置
//job.setJarByClass(JobMain.class);
//2.配置job任务对象(8个步骤)
//第一步 指定文件的读取方式和读取路径
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("hdfs://node01:8020/wordcount"));
//TextInputFormat.addInputPath(job,new Path("file:///E:\\mapreduce\\input"));
//第二步 指定map阶段处理方式和数据类型
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//3,4,5,6 采用默认方式
//第七步 指定 redce 的处理方式和数据类型
job.setReducerClass(wordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//第八步,设置输出类型
job.setOutputFormatClass(TextOutputFormat.class);
Path path =new Path("hdfs://node01:8020/wordcount_out");
//设置输出路径
TextOutputFormat.setOutputPath(job,path);
//TextOutputFormat.setOutputPath(job,new Path("file:///E:\\mapreduce\\output"));
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"), new Configuration());
boolean a = fileSystem.exists(path);
if(a){
fileSystem.delete(path,true);
}
//等待任务结束
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//启动job任务
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
6.集群运行和本地运行
//集群运行
hadoop jar hadoop_hdfs_operate-1.0-SNAPSHOT.jar cn.itcast.mapreduce.JobMain
//本地运行,修改目录
TextInputFormat.addInputPath(job,new Path("file:///E:\\mapreduce\\input"));
TextOutputFormat.setOutputPath(job,new Path("file:///E:\\mapreduce\\output"));7.查看结果

