【Spark】SparkStreaming入门解析(二)

(图片来源于网络,侵删)
一、Spark Streaming整合Kafka
【1】 概述
开发中我们经常会利用SparkStreaming实时地读取kafka中的数据然后进行处理,在spark1.3版本后,kafkaUtils里面提供了两种创建DStream的方法:
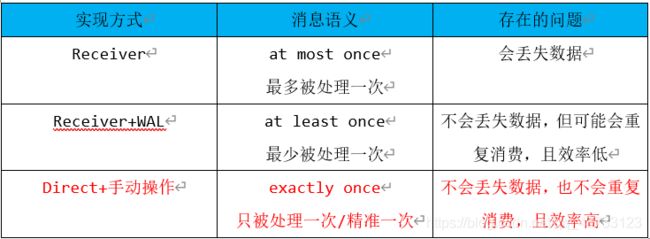
1)Receiver接收方式:
KafkaUtils.createDstream(开发中不用)
Receiver作为常驻的Task运行在Executor等待数据,但是一个Receiver效率低,所以需要开启多个,再手动合并数据(union),再进行处理,十分麻烦
如果Receiver哪台机器挂了,可能会丢失数据,所以需要开启WAL(预写日志)保证数据安全,那么效率又会降低!
Receiver方式是通过Zookeeper来连接kafka队列,调用Kafka高阶API,offset存储在Zookeeper,由Receiver维护
Spark在消费的时候为了保证数据不丢也会在Checkpoint中存一份offset,可能会出现数据不一致
所以不管从何种角度来说,Receiver模式都不适合在开发中使用了
2)Direct直连方式:
KafkaUtils.createDirectStream(开发中使用)
Direct方式是直接连接kafka分区来获取数据,从每个分区直接读取数据大大提高了并行能力
Direct方式调用Kafka低阶API(底层API),offset自己存储和维护,默认由Spark维护在checkpoint中,消除了与Zookeeper不一致的情况
当然offset也可以自己手动维护,存储在mysql、redis中
所以基于Direct模式可以在开发中使用,且借助Direct模式的特点+手动操作可以保证数据的Exactly once 精准一次
总结:
Receiver接收方式
1、多个Receiver接受数据效率高,但有丢失数据的风险
2、开启日志(WAL)可防止数据丢失,但写两遍数据效率低
3、Zookeeper维护offset有重复消费数据可能
4、使用高层次的API
Direct直连方式
1、不使用Receiver,直接到kafka分区中读取数据
2、不使用日志(WAL)机制
3、Spark自己维护offset
4、使用低层次的API
注意:
SparkStreaming和Kafka集成有两个版本:0.8及0.10+
0.8版本有Receiver和Direct模式(但是0.8版本生产环境问题较多,在Spark2.3之后不支持0.8版本了)
0.10以后只保留了direct模式(Reveiver模式不适合生产环境),并且0.10版本API有变化(更加强大)
【2】Direct
Direct方式会定期地从Kafka的topic下对应的partition中查询最新的偏移量,再根据偏移量范围在每个batch里面处理数据,Spark通过调用kafka简单的消费者API读取一定范围的数据
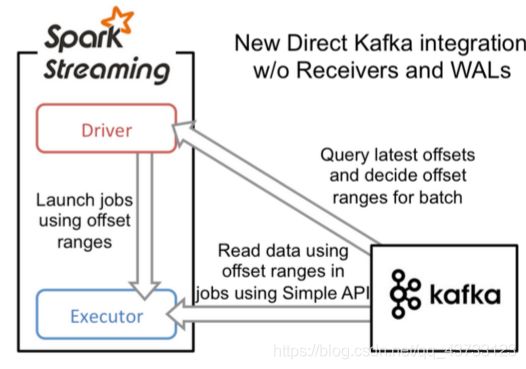
Direct的缺点是无法使用基于Zookeeper的Kafka监控工具
Direct相比基于Receiver方式有几个优点:
1)简化并行
不需要创建多个Kafka输入流,然后union它们,SparkStreaming将会创建和kafka分区数一样的rdd的分区数,而且会从kafka中并行读取数据,Spark中RDD的分区数和kafka中的分区数据是一一对应的关系
2)高效
Receiver实现数据的零丢失是将数据预先保存在WAL中,会复制一遍数据,会导致数据被拷贝两次,第一次是被kafka复制,另一次是写到WAL中。而Direct不使用WAL消除了这个问题。
3)恰好一次语义(Exactly-once-semantics)
Receiver读取kafka数据是通过kafka高层次api把偏移量写入Zookeeper中,虽然这种方法可以通过数据保存在WAL中保证数据不丢失,但是可能会因为SparkStreaming和ZK中保存的偏移量不一致而导致数据被消费了多次
Direct的Exactly-once-semantics(EOS)通过实现Kafka低层次api,偏移量仅仅被SparkStreaming保存在checkpoint中,消除了Zookeeper和SparkStreaming偏移量不一致的问题
【3】代码开发
添加如下依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.2.0</version>
</dependency>
代码如下:
object SparkStreaming05_KafkaSource {
def main(args: Array[String]): Unit = {
//1.创建SparkConf对象
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming05_KafkaSource")
// 2.创建StreamingContext对象,指定时间区间
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("WARN")
// 3.设置Kafka参数
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "192.168.100.111:9092,192.168.100.111:9092,192.168.100.111:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "SparkKafka",
"auto.offset.reset" -> "latest",
//false表示关闭自动提交.由spark帮你提交到Checkpoint或程序员手动维护
"enable.auto.commit" -> (false: java.lang.Boolean)
)
// 4.设置Topic
var topics = Array("KafkaSouce_SparkSink")
val recordDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc,
LocationStrategies.PreferConsistent, //位置策略,源码强烈推荐使用该策略,会让Spark的Executor和Kafka的Broker均匀对应
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams)) //消费策略,源码强烈推荐使用该策略
// 5.获取VALUE数据
val result: DStream[(String,Int)] = recordDStream.map(_.value()).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
result.print()
// 6.开启StreamingContext
ssc.start()
// 7.持续等待着接收数据
ssc.awaitTermination()
}
}
【4】Kafka手动维护偏移量
代码如下
object SparkStreaming06_KafkaSourceByNotAutoCommitOffset {
def main(args: Array[String]): Unit = {
// 1.创建SparkConf
val sparkConf = new SparkConf().setAppName("SparkStreaming06_KafkaSourceByNotAutoCommitOffset").setMaster("local[*]")
// 2.创建StreamingContext,并指定时间区间
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.sparkContext.setLogLevel("WARN")
// 3.设置Kafka参数
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "192.168.100.111:9092,192.168.100.111:9092,192.168.100.111:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "SparkKafka",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
// 4.设置Topic
val topics = Array("KafkaSouce_SparkSink")
// 5.使用KafkaUtil连接Kafak获取数据
//注意:
//如果MySQL中没有记录offset,则直接连接,从latest开始消费
//如果MySQL中有记录offset,则应该从该offset处开始消费
val offsetMap: mutable.Map[TopicPartition, Long] = OffsetUtil.getOffsetMap("SparkKafka", "KafkaSouce_SparkSink")
val recordDStream: InputDStream[ConsumerRecord[String, String]] = if (offsetMap.size > 0) { //有记录offset
println("MySQL中记录了offset,则从该offset处开始消费")
KafkaUtils.createDirectStream[String, String](ssc,
LocationStrategies.PreferConsistent, //位置策略,源码强烈推荐使用该策略,会让Spark的Executor和Kafka的Broker均匀对应
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams, offsetMap)) //消费策略,源码强烈推荐使用该策略
} else { //没有记录offset
println("没有记录offset,则直接连接,从latest开始消费")
KafkaUtils.createDirectStream[String, String](ssc,
LocationStrategies.PreferConsistent, //位置策略,源码强烈推荐使用该策略,会让Spark的Executor和Kafka的Broker均匀对应
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams)) //消费策略,源码强烈推荐使用该策略
}
// 6.操作数据
//注意:我们的目标是要自己手动维护偏移量,也就意味着,消费了一小批数据就应该提交一次offset
//而这一小批数据在DStream的表现形式就是RDD,所以我们需要对DStream中的RDD进行操作
//而对DStream中的RDD进行操作的API有transform(转换)和foreachRDD(动作)
recordDStream.foreachRDD(rdd => {
if (rdd.count() > 0) { //当前这一时间批次有数据
rdd.foreach(record => println("接收到的Kafk发送过来的数据为:" + record))
//注意:通过打印接收到的消息可以看到,里面有我们需要维护的offset,和要处理的数据
//接下来可以对数据进行处理....或者使用transform返回和之前一样处理
//处理数据的代码写完了,就该维护offset了,那么为了方便我们对offset的维护/管理,spark提供了一个类,帮我们封装offset的数据
val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
for (o <- offsetRanges) {
println(s"topic=${o.topic},partition=${o.partition},fromOffset=${o.fromOffset},untilOffset=${o.untilOffset}")
}
//手动提交offset,默认提交到Checkpoint中
recordDStream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
//实际中偏移量可以提交到MySQL/Redis中
OffsetUtil.saveOffsetRanges("SparkKafkaDemo", offsetRanges)
}
})
// 7.对数据进行WordCount操作并打印
val lineDStream: DStream[String] = recordDStream.map(_.value()) //_指的是ConsumerRecord
val wrodDStream: DStream[String] = lineDStream.flatMap(_.split(" ")) //_指的是发过来的value,即一行数据
val wordAndOneDStream: DStream[(String, Int)] = wrodDStream.map((_, 1))
val result: DStream[(String, Int)] = wordAndOneDStream.reduceByKey(_ + _)
result.print()
// 8.开启StreamingContext
ssc.start()
// 9.持续等待着接收数据
ssc.awaitTermination()
}
/*
手动维护offset的工具类
首先在MySQL创建如下表
CREATE TABLE `offset` (
`topic` varchar(255) NOT NULL,
`partition` int(11) NOT NULL,
`groupid` varchar(255) NOT NULL,
`offset` bigint(20) DEFAULT NULL,
PRIMARY KEY (`topic`,`partition`,`groupid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
*/
object OffsetUtil {
//从数据库读取偏移量
def getOffsetMap(groupid: String, topic: String) = {
val connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/KafkaOffset?characterEncoding=UTF-8", "root", "root")
val pstmt = connection.prepareStatement("select * from offset where groupid=? and topic=?")
pstmt.setString(1, groupid)
pstmt.setString(2, topic)
val rs: ResultSet = pstmt.executeQuery()
val offsetMap = mutable.Map[TopicPartition, Long]()
while (rs.next()) {
offsetMap += new TopicPartition(rs.getString("topic"), rs.getInt("partition")) -> rs.getLong("offset")
}
rs.close()
pstmt.close()
connection.close()
offsetMap
}
//将偏移量保存到数据库
def saveOffsetRanges(groupid: String, offsetRange: Array[OffsetRange]) = {
val connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/KafkaOffset?characterEncoding=UTF-8", "root", "root")
//replace into表示之前有就替换,没有就插入
val pstmt = connection.prepareStatement("replace into offset (`topic`, `partition`, `groupid`, `offset`) values(?,?,?,?)")
for (o <- offsetRange) {
pstmt.setString(1, o.topic)
pstmt.setInt(2, o.partition)
pstmt.setString(3, groupid)
pstmt.setLong(4, o.untilOffset)
pstmt.executeUpdate()
}
pstmt.close()
connection.close()
}
}
}
二、Spark Streaming自定义数据源
代码如下
object SparkStreaming07_MyReceiver {
def main(args: Array[String]): Unit = {
// 1.创建SparkConf对象
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming07_MyReceiver")
// 2.创建StreamingContext对象,指定时间区间
val ssc = new StreamingContext(sparkConf,Seconds(5))
ssc.sparkContext.setLogLevel("WARN")
// 3.指定从socket中获取DStream数据
val socketDStream: ReceiverInputDStream[String] = ssc.receiverStream(new MyReceiver("192.168.100.111",44444))
// 4.对数据进行解析
val wordToNumDStream: DStream[(String, Int)] = socketDStream.flatMap(_.split(" ")).map(_ -> 1).reduceByKey(_ + _)
// 5.打印输出
wordToNumDStream.print()
// 6.开启StreamingContext
ssc.start()
// 7.持续等待着接收数据
ssc.awaitTermination()
}
class MyReceiver(host: String, port: Int)
extends Receiver[String](StorageLevel.MEMORY_AND_DISK_2) with Logging {
def onStart() {
// Start the thread that receives data over a connection
new Thread("Socket Receiver") {
override def run() { receive() }
}.start()
}
def onStop() {
// There is nothing much to do as the thread calling receive()
// is designed to stop by itself if isStopped() returns false
}
/** Create a socket connection and receive data until receiver is stopped */
private def receive() {
var socket: Socket = null
var userInput: String = null
try {
// Connect to host:port
socket = new Socket(host,port)
// Until stopped or connection broken continue reading
val reader = new BufferedReader(
new InputStreamReader(socket.getInputStream(), StandardCharsets.UTF_8))
userInput = reader.readLine()
while(!isStopped && userInput != null) {
store(userInput)
userInput = reader.readLine()
}
reader.close()
socket.close()
// Restart in an attempt to connect again when server is active again
restart("Trying to connect again")
} catch {
case e: java.net.ConnectException =>
// restart if could not connect to server
restart("Error connecting to " + host + ":" + port, e)
case t: Throwable =>
// restart if there is any other error
restart("Error receiving data", t)
}
}
}
}
三、缓存、容错与持久化
【1】Caching / Persistence
和RDDs类似,DStreams同样允许开发者将流数据保存在内存中。也就是说,在DStream上使用persist()方法将会自动把DStreams中的每个RDD保存在内存中。当DStream中的数据要被多次计算时,这个非常有用(如在同样数据上的多次操作),对于像reduceByWindowred和reduceByKeyAndWindow以及基于状态的(updateStateByKey)这种操作,保存是隐含默认的,因此,即使开发者没有调用persist(),由基于窗操作产生的DStreams会自动保存在内存中
【2】检查点机制
检查点机制是我们在Spark Streaming中用来保障容错性的主要机制,与应用程序逻辑无关的错误(即系统错位,JVM崩溃等)有迅速恢复的能力
它可以使Spark Streaming阶段性地把应用数据存储到诸如HDFS这样的可靠存储系统中, 以供恢复时使用
具体来说,检查点机制主要为以下两个目的服务:
- 1)控制发生失败时需要重算的状态数,SparkStreaming可以通过转化图的谱系图来重算状态,检查点机制则可以控制需要在转化图中回溯多远
- 2)提供
驱动器程序容错,如果流计算应用中的驱动器程序崩溃了,你可以重启驱动器程序并让驱动器程序从检查点恢复,这样Spark Streaming就可以读取之前运行的程序处理数据的进度,并从那里继续
了实现这个,Spark Streaming需要为容错存储系统checkpoint足够的信息从而使得其可以从失败中恢复过来
有两种类型的数据设置检查点:
- 1)
Metadata checkpointing:将定义流计算的信息存入容错的系统如HDFS,元数据包括:
①配置:用于创建流应用的配置
②DStreams操作:定义流应用的DStreams操作集合
③不完整批次 :批次的工作已进行排队但是并未完成 - 2)
Data checkpointing: 将产生的RDDs存入可靠的存储空间。对于在多批次间合并数据的状态转换,这个很有必要。在这样的转换中,RDDs的产生基于之前批次的RDDs,这样依赖链长度随着时间递增。为了避免在恢复期这种无限的时间增长(和链长度成比例),状态转换中间的RDDs周期性写入可靠地存储空间(如HDFS)从而切短依赖链
总而言之,元数据检查点在由驱动失效中恢复是首要需要的,而数据或者RDD检查点甚至在使用了状态转换的基础函数中也是必要的
出于这些原因,检查点机制对于任何生产环境中的流计算应用都至关重要。你可以通过向 ssc.checkpoint() 方法传递一个路径参数(HDFS、本地路径均可)来配置检查点机制,同时你的应用应该能够使用检查点的数据
1)当程序首次启动,其将创建一个新的StreamingContext,设置所有的流并调用start()
2)当程序在失效后重启,其将依据检查点目录的检查点数据重新创建一个StreamingContext, 通过使用StraemingContext.getOrCreate很容易获得这个性能
【3】驱动器程序容错
驱动器程序的容错要求我们以特殊的方式创建 StreamingContext,我们需要把检查点目录提供给 StreamingContext。与直接调用 new StreamingContext 不同,应该使用 StreamingContext.getOrCreate() 函数
object SparkStreaming09_getDataFromCheckPoint {
def main(args: Array[String]): Unit = {
def createStreamingContext():StreamingContext = {
// 1.创建SparkConf对象
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming09_getDataFromCheckPoint")
val ssc = new StreamingContext(sparkConf,Seconds(5))
ssc.sparkContext.setLogLevel("WARN")
val socketDStream: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.100.111",44444)
val wordToNum: DStream[(String, Int)] = socketDStream.flatMap(_.split(" ")).map(_ -> 1).updateStateByKey(sum)
wordToNum.print()
ssc
}
// 2.从检查点的获取StreamingContext,如果没有就创建新的
val ssc = StreamingContext.getOrCreate("updateStateByKey", createStreamingContext _)
ssc.start()
// 7.持续等待着接收数据
ssc.awaitTermination()
}
def sum(newDatas:Seq[Int],historyDatas:Option[Int]):Option[Int]={
var result = newDatas.sum + historyDatas.getOrElse(0)
Some(result)
}
}
【4】工作节点容错
为了应对工作节点失败的问题,Spark Streaming使用与Spark的容错机制相同的方法。所有从外部数据源中收到的数据都在多个工作节点上备份。所有从备份数据转化操作的过程 中创建出来的 RDD 都能容忍一个工作节点的失败,因为根据 RDD 谱系图,系统可以把丢失的数据从幸存的输入数据备份中重算出来
【5】接收器容错
运行接收器的工作节点的容错也是很重要的。如果这样的节点发生错误,Spark Streaming 会在集群中别的节点上重启失败的接收器。然而,这种情况会不会导致数据的丢失取决于数据源的行为(数据源是否会重发数据)以及接收器的实现(接收器是否会向数据源确认 收到数据)
举个例子,使用 Flume 作为数据源时,两种接收器的主要区别在于数据丢失时的保障。在“接收器从数据池中拉取数据”的模型中,Spark 只会在数据已经在集群中 备份时才会从数据池中移除元素。而在“向接收器推数据”的模型中,如果接收器在数据 备份之前失败,一些数据可能就会丢失。总的来说,对于任意一个接收器,你必须同时考虑上游数据源的容错性(是否支持事务)来确保零数据丢失。
总的来说,接收器提供以下保证:
- 所有
从可靠文件系统中读取的数据(比如通过StreamingContext.hadoopFiles读取的) 都是可靠的,因为底层的文件系统是有备份的Spark Streaming会记住哪些数据存放到 了检查点中,并在应用崩溃后从检查点处继续执行 - 对于像
Kafka、推式Flume、Twitter这样的不可靠数据源,Spark会把输入数据复制到其他节点上,但是如果接收器任务崩溃,Spark 还是会丢失数据。在 Spark 1.1 以及更早的版 本中,收到的数据只被备份到执行器进程的内存中,所以一旦驱动器程序崩溃(此时所 有的执行器进程都会丢失连接),数据也会丢失。在 Spark 1.2 中,收到的数据被记录到诸 如 HDFS 这样的可靠的文件系统中,这样即使驱动器程序重启也不会导致数据丢失
综上所述,确保所有数据都被处理的最佳方式是使用可靠的数据源(例如 HDFS、拉式 Flume 等)。如果你还要在批处理作业中处理这些数据,使用可靠数据源是最佳方式,因为这种方式确保了你的批处理作业和流计算作业能读取到相同的数据,因而可以得到相同的结果
【6】处理保证
由于Spark Streaming工作节点的容错保障,Spark Streaming可以为所有的转化操作提供 “精确一次”执行的语义,即使一个工作节点在处理部分数据时发生失败,最终的转化结果(即转化操作得到的 RDD)仍然与数据只被处理一次得到的结果一样
然而,当把转化操作得到的结果使用输出操作推入外部系统中时,写结果的任务可能因故障而执行多次,一些数据可能也就被写了多次。由于这引入了外部系统,因此我们需要专门针对各系统的代码来处理这样的情况。我们可以使用事务操作来写入外部系统(即原子化地将一个 RDD 分区一次写入),或者设计幂等的更新操作(即多次运行同一个更新操作 仍生成相同的结果)。比如 Spark Streaming 的 saveAs...File 操作会在一个文件写完时自动将其原子化地移动到最终位置上,以此确保每个输出文件只存在一份
【7】性能考量
最常见的问题是Spark Streaming可以使用的最小批次间隔是多少。总的来说,500毫秒已经被证实为对许多应用而言是比较好的最小批次大小
寻找最小批次大小的最佳实践是从一个比较大的批次大小(10 秒左右)开始,不断使用更小的批次大小。如果 Streaming 用 户界面中显示的处理时间保持不变,你就可以进一步减小批次大小。如果处理时间开始增 加,你可能已经达到了应用的极限
相似地,对于窗口操作,计算结果的间隔(也就是滑动步长)对于性能也有巨大的影响。 当计算代价巨大并成为系统瓶颈时,就应该考虑提高滑动步长了
减少批处理所消耗时间的常见方式还有提高并行度,有以下三种方式可以提高并行度:
- 增加接收器数目 :
有时如果记录太多导致单台机器来不及读入并分发的话,接收器会成为系统瓶颈。这时 你就需要通过创建多个输入DStream(这样会创建多个接收器)来增加接收器数目,然后使用union来把数据合并为一个数据源 - 将收到的数据显式地重新分区:
如果接收器数目无法再增加,你可以通过使用 DStream.repartition 来显式重新分区输 入流(或者合并多个流得到的数据流)来重新分配收到的数据。 - 提高聚合计算的并行度:
对于像 reduceByKey() 这样的操作,你可以在第二个参数中指定并行度,我们在介绍 RDD 时提到过类似的手段
都看到这里了,点赞评论一下吧!!!
