原文翻译如下。
Apache Flink是一个能在有界与无界数据流上进行有状态计算的框架。Flink在不同层次的抽象上提供了相应的API,并且针对常用的使用场景提供了工具库。
流应用的基础元素
基于流处理框架来构建与运行什么样的应用,取决于该应用所选择的框架处理 stream,state以及time的能力。下面我们将会描述流处理应用中这三个基础元素,并解释Flink是如何处理这三者的。
Streams
很显然,stream是流处理中的基础概念。然而,流的不同的特性决定了一个流能够并且应该如何被处理。Flink是一个多变的处理框架,能够处理任意类型的流。
- 有界流与无界流: 流可以是无界的,也可以是有界的,如一个固定大小的数据集。Flink提供了精妙的能力来处理无界流,同时提供了高效处理有界流的操作符。
- 实时流与记录流:所有数据都可以看作流。有两种方式来处理这些数据。当数据生成时,实时地进行处理;或者将流持久化到存储系统,如文件系统或对象存储等,然后之后再对数据进行处理。Flink对上述两种类型的流都可以进行处理。
State
每一个稍微复杂些的流应用都是有状态的,只有那些仅仅对单个事件进行转化的应用不需要状态。任何一个执行基本业务逻辑的应用都需要保存状态或中间计算结果,以便于在稍后的某个时刻,如下一个事件到达时或经过一段特定时间段后,再获取该状态或结果。
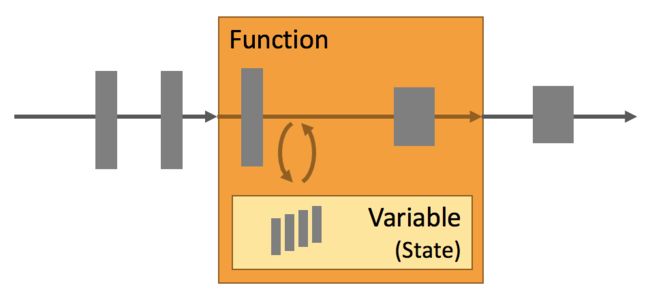
应用状态在Flink中是最重要的数据。Flink提供了处理state的上下文context,你可以在context提供的特性中印证这一点。
- 多种状态基元:Flink为不同的数据结构提供了相应的状态基元,例如atomic values, lists及maps。开发者可以基于方法的访问模式来选择最高效的状态基元。
- 可插拔的状态后端:应用状态是由一个可插拔的状态后端在管理与检查。Flink提供了内存存储或RocksDB两种不同的状态后端,RocksDB是一个高效的,嵌入式的磁盘数据存储。Flink也支持自定义的状态后端。
- 准确且一致的状态:Flink的检查点算法与恢复算法,保证了应用在遇到故障时,仍能维持应用状态的一致性。因此故障处理不会对应用的正确性造成影响。
- 非常大的状态:得益于Flink的异步且增量的检查点算法,使得Flink有能力维持TB级别的应用状态。
- 可扩展的应用:Flink支持有状态应用的横向扩展,只需要将状态重新分发给更多或更少的works即可。
Time
Time是流应用中另一个重要概念。大多数的事件流都有其固有的时间属性,这是由于每一个事件都是在某个特定时刻产生的。不仅如此,许多常见的流计算都是基于时间的,例如windows aggregations(对在某时间窗口的所有数据执行聚合操作), sessionization(基于会话session的统计), pattern detection(模式检测), and time-based joins(基于时间的流联接)。一个流应用的重要方面便是该应用如何处理时间,处理何种类型的时间,如event-time(事件时间)或者processing-time(处理时间)。
Flink提供了一系列丰富的与时间相关的特性:
- Event-time 模式:应用以Event-time模式来处理流,意味着应用是基于事件的时间戳来进行计算。因此,Event-time模式保证了不管是处理实时数据还是记录数据,都能得到准确且一致的结果。
- 支持 Watermark(水印):Flink提出Watermark的概念是为了在非理想情况下Event-time模式中的时间更具有完备性(后续文章会有详细介绍,大意是指在真实世界中,总会存在某些数据由于网络等原因而无法按照顺序到达,若不等待该迟到数据,则计算结果不准确,Watermark则表明了某时刻之前的所有数据都已到达,可以执行计算,保证了结果的准确性。Watermark的作用在于在允许延迟时间内,等待尽可能多的迟到数据到达,然后再开始计算,尽量保证结果的完整性)。Watermark提供了一个灵活的机制,在延迟与结果完整性之间做出权衡。
- 迟到数据处理:当使用Event-time模式以及Watermark处理流数据时,有可能出现这样的情况:在计算完成之后,与该计算相关的某些事件才到达,这样的事件(数据)成为迟到的事件(数据)。Flink提供了多种选择来处理迟到数据,例如通过侧输出将该迟到数据重新路由,并更新之前已经计算完成的结果。
- Processing-time模式:除了提供Event-time模式之外,Flink还提供了Processing-time模式,该模式根据执行计算的机器的执行时间来进行计算。Processing-time模式适合于特定的应用,这类应用对低延迟有极高的要求并且可以接受近似的结果。
分层的API
Flink提供了三层API,每一层API在使用的简易性与表达的丰富性之间做了权衡,以适应不同的使用情况。
[图片上传失败...(image-b7f7e3-1543665726598)]
我们简要的展示一下每一层API,并且讨论它们的使用,以及给出一个代码示例。
ProcessFunction
ProcessFunction是Flink提供的最具有表达力的函数接口。Flink提供该接口来处理一个或两个输入流中的事件或者处理在window中分组后的事件。ProcessFunction提供了对时间和状态的精细控制。一个ProcessFunction可以根据需要修改状态以及注册一个timer,该timer会在设定好的未来某个时刻触发一个回调函数。因此,ProcessFunction可以按照大多数有状态的事件驱动(event-driven)应用的要求,实现针对每个事件的复杂业务逻辑。
下面的示例展示了 KeyedProcessFunction ,该函数作用在 KeyedStream 上,用来匹配 START 与 END 事件。当一个START事件到达时,该函数会将START事件的时间戳存储在state中,并且注册一个4小时的timer。如果在4小时内,注册的timer未被触发时,END事件就已经到达,该函数会计算END事件与START事件之间的时间差,清除state并且返回结果。否则,则会触发timer的回调函数,清除state内容。
/**
* Matches keyed START and END events and computes the difference between
* both elements' timestamps. The first String field is the key attribute,
* the second String attribute marks START and END events.
*/
public static class StartEndDuration
extends KeyedProcessFunction, Tuple2> {
private ValueState startTime;
@Override
public void open(Configuration conf) {
// obtain state handle
startTime = getRuntimeContext()
.getState(new ValueStateDescriptor("startTime", Long.class));
}
/** Called for each processed event. */
@Override
public void processElement(
Tuple2 in,
Context ctx,
Collector> out) throws Exception {
switch (in.f1) {
case "START":
// set the start time if we receive a start event.
startTime.update(ctx.timestamp());
// register a timer in four hours from the start event.
ctx.timerService()
.registerEventTimeTimer(ctx.timestamp() + 4 * 60 * 60 * 1000);
break;
case "END":
// emit the duration between start and end event
Long sTime = startTime.value();
if (sTime != null) {
out.collect(Tuple2.of(in.f0, ctx.timestamp() - sTime));
// clear the state
startTime.clear();
}
default:
// do nothing
}
}
/** Called when a timer fires. */
@Override
public void onTimer(
long timestamp,
OnTimerContext ctx,
Collector> out) {
// Timeout interval exceeded. Cleaning up the state.
startTime.clear();
}
}
该示例展示了 KeyedProcessFunction 的表现力,但同时也体现出该API有些繁琐。
DataStream API
DataStream API针对大多数常见的流处理操作提供了方法,如:根据时间窗口处理数据(windowing),依次记录转化(record-at-a-time transformations),通过查询其他数据源来丰富事件(enriching events by querying an external data store)。DataStream API对Java与Scala都可用,且提供了如 map(), reduce(), 以及 aggregate()等方法。具体的业务逻辑可以通过实现其方法接口或者使用Java/Scala的lambda表达式。
下面的示例展示了,在鼠标点击事件流中,如何统计每个会话session中的点击数量。
// a stream of website clicks
DataStream clicks = ...
DataStream> result = clicks
// project clicks to userId and add a 1 for counting
.map(
// define function by implementing the MapFunction interface.
new MapFunction>() {
@Override
public Tuple2 map(Click click) {
return Tuple2.of(click.userId, 1L);
}
})
// key by userId (field 0)
.keyBy(0)
// define session window with 30 minute gap
.window(EventTimeSessionWindows.withGap(Time.minutes(30L)))
// count clicks per session. Define function as lambda function.
.reduce((a, b) -> Tuple2.of(a.f0, a.f1 + b.f1));
SQL & Table API
Flink提供了两种关系型API:Table API 以及 SQL。不论是处理离线数据还是流数据,每种API都可以使用相同的方法来处理,例如在无界实时数据流或者记录数据流上使用相同的API执行查询操作,都会得到相同的结果。Table API 与 SQL 使用了Apache Calcite进行解析,校验以及查询优化。它们可以与DataStream以及DataSet API无缝的结合使用,且提供了对用户定义的标量(user-defined scalar)、聚合和表值函数(table-valued function)的支持。
Flink提供的关系型API的设计初衷便是使得数据分析,数据清洗以及构建ETL应用更简单。
下面的示例展示了如何使用SQL 的 API 在鼠标点击事件流中,查询每个会话session中的点击总数。这与上面DataStream API的使用案例是相同的。
SELECT userId, COUNT(*)
FROM clicks
GROUP BY SESSION(clicktime, INTERVAL '30' MINUTE), userId
工具库
Flink针对常见的数据处理使用场景提供了几个工具库。这些工具库一般都内置在API中而不会单独存在。因此,它们能够享受到Flink API提供的便利以及可以与其他工具库集成。
- 复杂事件处理: 在处理事件流时,模式匹配是一个十分常见的场景。Flink的CEP库提供了API来指定需要匹配的时间的模式(类似于正则表达式或者状态机),CEP库与DataStream API进行了集成,因此这些匹配模式是由DataStream API在数据流上进行匹配。能够使用CEP工具库的应用包括:网络入侵检测,业务处理监控,以及欺诈检测。
- DataSet API:DataSet API是Flink执行批处理任务的核心API。DataSet API的基本函数包括:map, reduce, (outer) join, co-group, 以及iterate。这些操作都由一系列算法和数据结构提供支撑,这些算法与数据结构用于内存中的序列化数据,当数据的大小超过所分配的内存容量时,会将数据保存到磁盘。Flink DataSet API的数据处理算法受到了关系型数据库操作符的启发,例如hybrid hash-join, external merge-sort.
- Gelly:Gelly是一个用于可伸缩的图像处理与分析应用的工具库。Gelly基于DataSet API来实现,并与DataSet API进行了集成。因此,Gelly继承了DataSet API的可伸缩性以及运算符的健壮性。Gelly提供了内置的算法,例如:标签传播(label propagation,) 三角形枚举法(triangle enumeration), 以及网页排名(page rank),同时,Gelly也提供了Graph API可以很容易的实现自定义的图像算法。