python 哈工大NTP分词 安装pyltp 及配置模型(python3.5 3.6)
哈工大语言云 NTP python使用
系统配置(方法windows通用):
windows10 python3.5
使用文档地址:https://pyltp.readthedocs.io/zh_CN/latest/api.html#id13
第一步 :安装pyltp##
######三个无果尝试
(无果的) cmd pip install pyltp 失败
(无果的)[pip 指定 安装源方法安装] ,此方法很长时间,也不一定有结果,不建议再尝试啦(https://blog.csdn.net/shuihupo/article/details/81416381):
pip install pyltp -i https://pypi.douban.com/simple
(无果的)(下载安装包安装,满满的期待满满的失望),安装包地址: https://pypi.org/search/?q=pyltp
[[Python第三方库安装方法](https://blog.csdn.net/shuihupo/article/details/79992615)](包括不同格式压缩文件的安装,和存放地址说明)(https://blog.csdn.net/shuihupo/article/details/79992615)
最后一步报错:
“d:\local\anaconda3\tools\scripts\pyltp-0.2.1\ltp\src\srl\include\extractor\Converter.h(32): error C3861: ‘convert’: identifier not found
error: command ‘C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\BIN\x86_amd64\cl.exe’ failed with exit status 2”
又开始满满搜索
######有果的成功安装
下载wheels
这是一个大神在自己的电脑(win10)上编译的,64bit的windows应该都可以,亲测成功。csdn下载地址
pyltp-0.2.1-cp35-cp35m-win_amd64.whl
pyltp-0.2.1-cp36-cp36m-win_amd64.whl
注意: 这两个文件的区别是python版本号
安装方法参考我的另一个博客:(包括不同格式压缩文件的安装,和存放地址说明)(https://blog.csdn.net/shuihupo/article/details/79992615)
也可以在这里下载这里写链接内容
第二步 :模型下载##
######下载地址
官网,http://ltp.ai/download.html
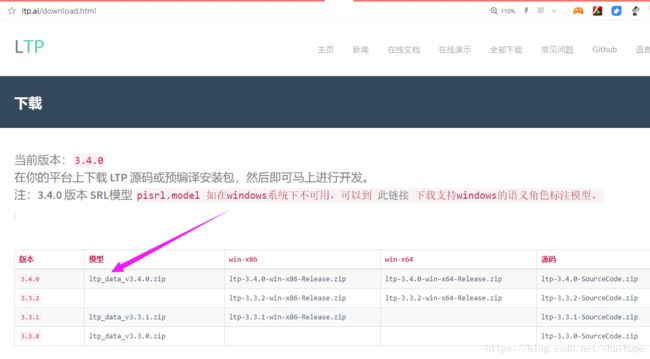
######注意
######1.版本的匹配目前最新的配置:
- pyltp 版本:0.2.0
- LTP 版本:3.4.0
-
模型版本:3.4.0 (解压前600多兆)
######2.存放地址
(1)新建一个项目文件夹,比如:D:\myLTP;
(2)将模型文件解压,将带版本号的模型文件改名字为ltp_data。文件夹放入项目文件夹;这将是我们以后加载模型的路径。 D:\myLTP\ltp_data.
下面说明所包含的模型内容:
1. 官方的下载模型文件,ltp_data并解压到任意位置(注意点:模型的路径最好不要有中文,不然模型加载不出),
2. 解压后得到一个大于1G的文件夹,确保此文件夹名称为ltp_data,位置任意,但在Python程序中一定要指明这个路径。
3. LTP提供的模型包括:(在ltp_data文件夹里面)
cws.model 分句模型,单文件
pos.model 词性标注模型,单文件
ner.model 命名实体识别模型,单文件
parser.model 依存句法分析模型,单文件
srl_data/ 语义角色标注模型,多文件(文件夹srl)(注意:按照官网提示注:3.4.0 版本 SRL模型 pisrl.model 如在windows系统下不可用,可以到官网“此链接” 下载支持windows的语义角色标注模型。)
2017/06/15 16:42 182,672,934 cws.model
2017/07/07 15:47 260 md5.txt
2017/06/15 15:19 22,091,814 ner.model
2017/06/15 16:26 367,819,616 parser.model
2017/06/15 16:00 196,372,381 pisrl.model
2017/06/15 16:43 433,443,857 pos.model
2017/07/07 15:47 6 version
7 个文件 1,202,400,868 字节
2 个目录 108,015,374,336 可用字节
- 文档说明地址:https://github.com/HIT-SCIR/ltp
- Python文档说明地址:https://github.com/HIT-SCIR/pyltp
- http://pyltp.readthedocs.io/zh_CN/latest/api.html#id2
##第三步 测试
文档地址:https://pyltp.readthedocs.io/zh_CN/latest/api.html#id13
在使用时,使用类似的方式的加载模型,注意替换自己的模型地址
使用 pyltp 进行分句示例如下,注意将官网示例由python2的语法,转换python3,主要是print加括号。
# -*- coding: utf-8 -*-
from pyltp import SentenceSplitter
sents = SentenceSplitter.split('元芳你怎么看?我就趴窗口上看呗!') # 分句
print '\n'.join(sents)
结果如下
元芳你怎么看?
我就趴窗口上看呗!
分词测试:
# -*- coding: utf-8 -*-
import os
LTP_DATA_DIR = 'E:\MyLTP\ltp_data' # ltp模型目录的路径
cws_model_path = os.path.join(LTP_DATA_DIR, 'cws.model') # 分词模型路径,模型名称为`cws.model`
from pyltp import Segmentor
segmentor = Segmentor() # 初始化实例
segmentor.load(cws_model_path) # 加载模型
words = segmentor.segment('元芳你怎么看') # 分词
print('\t'.join(words))
segmentor.release() # 释放模型
元芳 你 怎么 看
Process finished with exit code 0