参考链接:AWS官方解决方案
一、背景:
现在,越来越多的中国公司,在AWS海外区域部署业务。利用 S3 作为数据湖,存储海量的数据,包括图片、视频、日志、备份等等。很多场景下,需要把海外的 S3 数据复制到中国,在中国进行进一步分析处理。AWS S3 在海外提供跨区域自动复制功能 (Cross region replication, CRR) ,打个比方,如果你在弗吉尼亚的S3上上传的文件需要同步至新加坡,那么只需要在S3上打开SRR功能并设置Destination Bucket即可同步。但是,由于中国和海外区域隔离,不能使用CRR功能。

解决方案1:CP指令(AWS Cli)
我们可以用一个简单的命令行,调用不同的 profile ,利用管道,把第一个命令的输出流,作为第二个命令的输入流,可以复制 S3 文件:
$ aws s3 cp s3 ://globalbucket/testfile - --profile global | aws s3 cp - s3 ://chinabucket/testfile --profile china
但是,命令行需要有服务器来运行。更重要的问题是,没有机制来获取 S3 对象的变化信息,包括删除,新增,修改等,所以很难实现类似 S3 CRR的自动复制。
解决方案2:Sync指令(AWS Cli)
aws s3 sync同步命令,可以比较源和目标的变化,但是sync同步需要先list列出。在源 S3 有大量文件的时候,性能会受到影响。
解决方案3:利用 Lambda 来实现海外和中国之间的 S3 自动同步:
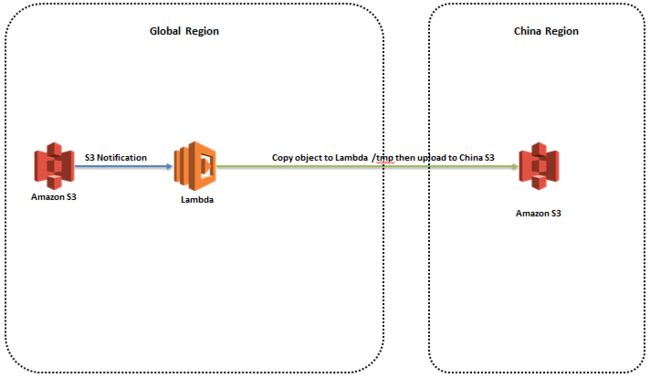
S3 有通知功能 (Notification) ,每当有对象创建或者删除时,发送通知触发 Lambda ,复制 S3 对象到其他区域。具体实现上, Lambda 下载 S3 对象到本地 /tmp目录,然后上传到中国。
此方案比较简单,但是, Lambda 容器 /tmp目录只有512MB,更大的 S3 文件不能下载。如果采用 Stream 流的方式,大文件很容易把 Lambda 内存用尽。并且,海外到中国的网络如果不稳定,传输中断,文件复制失败,没有任务监控和重新传输的机制.
解决方案4:
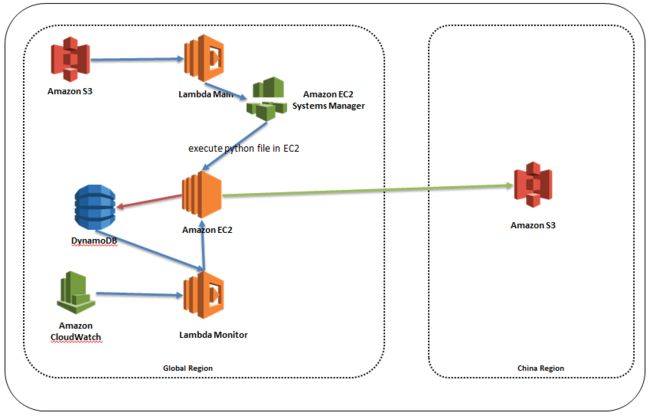
此方案把任务分解成多个 Lambda 函数,并行处理。任务状态和处理结果,存储在 DynamodDB 数据库。有专门的 Lambda 函数,定期检查状态。发现有失败的任务,会自动再次调用,直到整个任务完成。
具体逻辑实现,首先 S3 通知触发 Lambda 函数 ”Main”,调用 S3 Head Object 获得 S3 对象大小,每个5MB分块触发一个 Lambda “MPU” (Multi Part Upload) 函数,并且生成一个中国区 S3 Upload Id 。每个 MPU 函数使用 Get Object 下载自己对应的 S3 range 部分,并调用 Upload Part 上传到中国区 S3 ,完成之后把任务和结果信息写入 DynamodDB 。除了完成 Upload Part 任务,还会统计完成任务的数量。如果已完成任务数量等于 S3 分段数量,调用中国 S3 Complete Upload ,结束任务。
Lambda MPU函数超时设置为5分钟。对于 5MB 的数据,这个时间一般足够了。但是,海外到中国区网络可能会有稳定, Lambda MPU 函数如果出现超时,此分段就不能再执行。 Lambda 是无状态的,运行结束,数据不会保留。
为了监控每个分块函数的执行情况,加入了 Lambda “Monitor” 函数,由 Cloudwatch Events 每5分钟定期触发。Monitor函数扫描 DynamodDB 的任务执行情况,如果出现未完成的任务,并且超时,就重新执行,直到所有任务执行完成。
这里引入了分布式的设计理念,利用一个主调度函数Main,调用执行函数 MPU 处理每个分块,并有监控函数 Monitor 检查任务执行结果。对于大文件,调用多个 Lambda 并行处理,提高处理效率和传输速度,理论上可以支持到 S3 最大单个文件5TB。每个 Lambda 函数可以只用最低的内存128MB ,减少成本。
S3 分段上传,先创建一个 Upload ID ,然后把文件分成多个分块并行传输,最后当所有分块完成之后,调用 Complete Upload 完成整个上传。在分块传输阶段,每个分块单独传输。只要不执行 complete 或者 abort 操作,任务就不会结束。而已经上传的部分会暂时存储在目标 S3 ,直到任务结束。从这里来看,哪怕是分块传输中断,也只需要传输这部分的数据。
但是问题在于Lambda起的机器性能得不到保证,因此传输性能也得不到保障,因此我们设计了另外一套方案。
解决方案5:
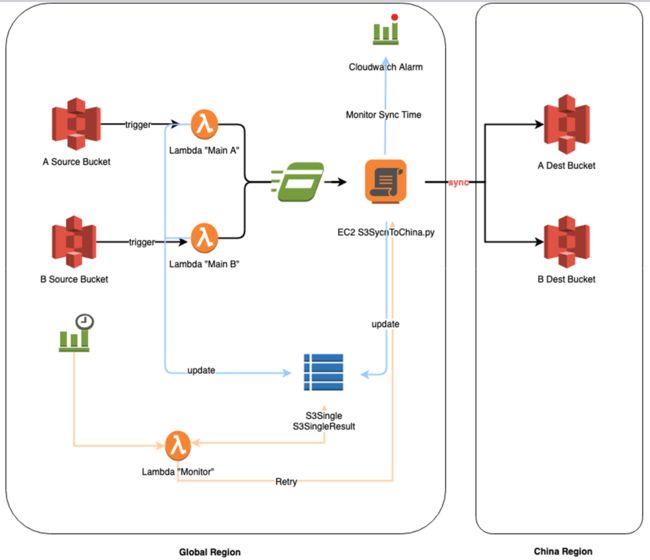
由于中国与海外区域隔离,S3不支持CRR功能。而海外的业务数据需要实时同步到中国区,因此我们利用Lambda及EC2等实现S3的实时同步。
涉及的相关服务:
• S3 Events:当有任何object的创建和删除操作时触发Lambda函数。
• Lambda:部署主函数及监控函数,主函数负责触发ssm执行同步脚本。
• DynamoDB:将同步任务状态持久化。
• Cloudwatch Events:定时触发监控函数,将没有同步成功的函数重新同步。
• SSM:在EC2实例执行同步脚本
• EC2:部署同步脚本。
配置流程:
1.创建⻆s3syncrole并附加到EC2实例:AmazonEC2RoleforSSM,AmazonS3FullAccess,AmazonDynamoDBFullAccess,AmazonSSMFullAccess
2.EC2实例配置BBR :
vi /etc/sysctl.conf
net.core.default_qdisc = fq
net.ipv4.tcp_congestion_control = bbr
3.EC2实例安装python3.6及boto3等模块
4.EC2实例部署脚本
5.创建Lambda执行角色并配置Lambda Main函数:
• 将中国区的ak/sk写入S3BJScredential.txt并存放在global的S3中,设置只允许lambda函数读取
{
"Version": "2012-10-17",
"Id": "AllowOnlyLambda",
"Statement": [
{
"Sid": "AllowOnlyLambda",
"Effect": "Deny",
"NotPrincipal": {
"Service": "lambda.amazonaws.com"
},
"Action": "S3:GetObject",
"Resource":"arn:aws:S3:::globalbucket/S3BJScredential.txt"
}
]
}
• 创建Lambda 主函数
Name: S3CopyToChina-Main,Runtime:
Python 3.6,Role : Lambda-S3copy
1) 配置超时Timeout=5 mins
2) 环境变量设置
CredBucket = <海外区域存放credential S3 bucket>
CredObject = <海外区域存放credential S3 object>
DstBucket = <中国目标 S3 bucket>
3)部署主函数
4) (可选)开启DLQ资源
Lambda默认并发1000,即使达到1000并发,仍有重试机制。除非同时上传的文件太大太多,一般都可以通过默认的重试两次来解决高并发问题,我们可以观察Lambda Dead Letter Queue指标,如果此指标大于0,说明有事件被丢弃。
6.监控函数
6.1 部署监控函数
6.2 配置Cloudwatch Events

7.源S3 Bucket中events的创建

8. 测试
• 在源S3上传文件
aws s3 cp AWildlife.tpks3://s3-virginia-to-china-speed-bespin/
• 查看文件是否同步到中国区的S3
aws s3 lss3://develop-s3-beijing-bespin-test --profile="china-s3"
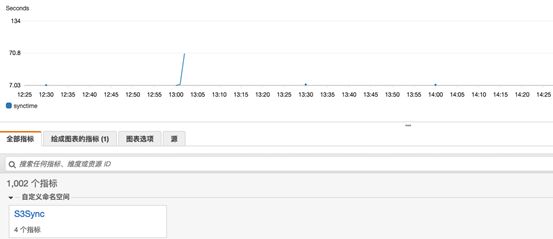
• 如果同步成功可通过Cloudwatch查看同步时间