YOLO源码详解(二)- 函数剖析
本系列作者:木凌
时间:2016年11月。
文章连接:http://blog.csdn.net/u014540717
QQ交流群:554590241
1、网络参数解析函数:parse_network_cfg
network parse_network_cfg(char *filename)
{
//read_cfg这个函数将所有的参数读到一个图中,如下所示,希望能帮助理解下代码
list *sections = read_cfg(filename);//首先我们看一下list,section, node, kvp这四个结构体
typedef struct{
int size;
node *front;
node *back;
} list;
typedef struct{
char *type;
list *options;
} section;
typedef struct node{
void *val;
struct node *next;
struct node *prev;
} node;
typedef struct{
char *key;
char *val;
int used;
} kvp;
//再看下yolo.cfg文件
[net]
batch=64
subdivisions=64
height=448
width=448
channels=3
momentum=0.9
decay=0.0005
learning_rate=0.001
policy=steps
steps=200,400,600,20000,30000
scales=2.5,2,2,.1,.1
max_batches = 40000
[crop]
crop_width=448
crop_height=448
flip=0
.
.
.
/*用矩形表示list,椭圆表示section,圆形表示node,六边形表示kvp,为了表达方便,我就把section和kvp放到了node里面,其实这样表达有失妥当,大家理解就行。根据作者代码我们就可以得出以下的参数网络,如有表达错误或不妥,欢迎指正*/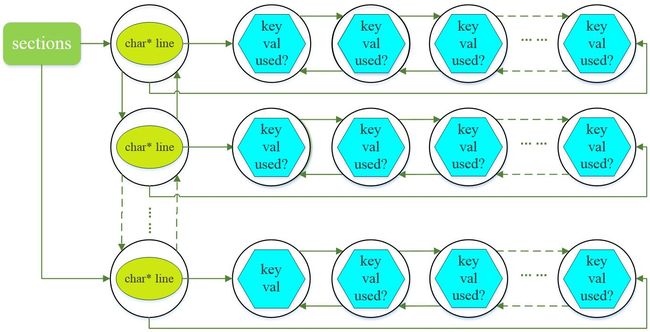
我们来大概解释下该参数网,首先创建一个list,取名sections,记录一共有多少个section(一个section存储了CNN一层所需参数);然后创建一个node,该node的void类型的指针指向一个新创建的section;该section的char类型指针指向.cfg文件中的某一行(line),然后将该section的list指针指向一个新创建的node,该node的void指针指向一个kvp结构体,kvp结构体中的key就是.cfg文件中的关键字(如:batch,subdivisions等),val就是对应的值;如此循环就形成了上述的参数网络图。
node *n = sections->front;
if(!n) error("Config file has no sections");
network net = make_network(sections->size - 1);
net.gpu_index = gpu_index;
size_params params;
section *s = (section *)n->val;
list *options = s->options;
if(!is_network(s)) error("First section must be [net] or [network]");
parse_net_options(options, &net);
params.h = net.h;
params.w = net.w;
params.c = net.c;
params.inputs = net.inputs;
params.batch = net.batch;
params.time_steps = net.time_steps;
params.net = net;
size_t workspace_size = 0;
n = n->next;
int count = 0;
free_section(s);
while(n){
params.index = count;
fprintf(stderr, "%d: ", count);
s = (section *)n->val;
options = s->options;
layer l = {0};
LAYER_TYPE lt = string_to_layer_type(s->type);
if(lt == CONVOLUTIONAL){
l = parse_convolutional(options, params);
}else if(lt == LOCAL){
l = parse_local(options, params);
}else if(lt == ACTIVE){
l = parse_activation(options, params);
}else if(lt == RNN){
l = parse_rnn(options, params);
}else if(lt == GRU){
l = parse_gru(options, params);
}else if(lt == CRNN){
l = parse_crnn(options, params);
}else if(lt == CONNECTED){
l = parse_connected(options, params);
}else if(lt == CROP){
l = parse_crop(options, params);
}else if(lt == COST){
l = parse_cost(options, params);
}else if(lt == REGION){
l = parse_region(options, params);
}else if(lt == DETECTION){
l = parse_detection(options, params);
}else if(lt == SOFTMAX){
l = parse_softmax(options, params);
net.hierarchy = l.softmax_tree;
}else if(lt == NORMALIZATION){
l = parse_normalization(options, params);
}else if(lt == BATCHNORM){
l = parse_batchnorm(options, params);
}else if(lt == MAXPOOL){
l = parse_maxpool(options, params);
}else if(lt == REORG){
l = parse_reorg(options, params);
}else if(lt == AVGPOOL){
l = parse_avgpool(options, params);
}else if(lt == ROUTE){
l = parse_route(options, params, net);
}else if(lt == SHORTCUT){
l = parse_shortcut(options, params, net);
}else if(lt == DROPOUT){
l = parse_dropout(options, params);
l.output = net.layers[count-1].output;
l.delta = net.layers[count-1].delta;
#ifdef GPU
l.output_gpu = net.layers[count-1].output_gpu;
l.delta_gpu = net.layers[count-1].delta_gpu;
#endif
}else{
fprintf(stderr, "Type not recognized: %s\n", s->type);
}
l.dontload = option_find_int_quiet(options, "dontload", 0);
l.dontloadscales = option_find_int_quiet(options, "dontloadscales", 0);
option_unused(options);
net.layers[count] = l;
if (l.workspace_size > workspace_size) workspace_size = l.workspace_size;
free_section(s);
n = n->next;
++count;
if(n){
params.h = l.out_h;
params.w = l.out_w;
params.c = l.out_c;
params.inputs = l.outputs;
}
}
free_list(sections);
net.outputs = get_network_output_size(net);
net.output = get_network_output(net);
if(workspace_size){
//printf("%ld\n", workspace_size);
#ifdef GPU
if(gpu_index >= 0){
net.workspace = cuda_make_array(0, (workspace_size-1)/sizeof(float)+1);
}else {
net.workspace = calloc(1, workspace_size);
}
#else
net.workspace = calloc(1, workspace_size);
#endif
}
return net;
}2、加载权重函数:load_weights(&net, weightfile)
void load_weights(network *net, char *filename)
{
//调用load_weights_upto(net, filename, net->n)函数
load_weights_upto(net, filename, net->n);
}
void load_weights_upto(network *net, char *filename, int cutoff)
{
#ifdef GPU
if(net->gpu_index >= 0){
cuda_set_device(net->gpu_index);
}
#endif
fprintf(stderr, "Loading weights from %s...", filename);
//fflush()函数冲洗流中的信息,该函数通常用于处理磁盘文件。
fflush(stdout);
FILE *fp = fopen(filename, "rb");
if(!fp) file_error(filename);
int major;
int minor;
int revision;
/*size_t fread ( void *buffer, size_t size, size_t count, FILE *stream)
fread是一个函数。从一个文件流中读数据,最多读取count个项,每个项size个字节,如果调用成功返回实
际读取到的项个数(小于或等于count),如果不成功或读到文件末尾返回0。*/
fread(&major, sizeof(int), 1, fp);
fread(&minor, sizeof(int), 1, fp);
fread(&revision, sizeof(int), 1, fp);
fread(net->seen, sizeof(int), 1, fp);
int transpose = (major > 1000) || (minor > 1000);
int i;
//cutoff顾名思义,之后的参数不加载,fine tuning的时候用
for(i = 0; i < net->n && i < cutoff; ++i){
//读取各层权重
layer l = net->layers[i];
if (l.dontload) continue;
if(l.type == CONVOLUTIONAL){
load_convolutional_weights(l, fp);
}
//我们看下卷积层的权重加载void load_convolutional_weights(layer l, FILE *fp)
{
if(l.binary){
//load_convolutional_weights_binary(l, fp);
//return;
}
//卷积层的参数个数,卷积核个数×通道数×卷积核长度×卷积核宽度
int num = l.n*l.c*l.size*l.size;
//这个估计没用上吧,直接给0了
if(0){
fread(l.biases + ((l.n != 1374)?0:5), sizeof(float), l.n, fp);
if (l.batch_normalize && (!l.dontloadscales)){
fread(l.scales + ((l.n != 1374)?0:5), sizeof(float), l.n, fp);
fread(l.rolling_mean + ((l.n != 1374)?0:5), sizeof(float), l.n, fp);
fread(l.rolling_variance + ((l.n != 1374)?0:5), sizeof(float), l.n, fp);
}
fread(l.weights + ((l.n != 1374)?0:5*l.c*l.size*l.size), sizeof(float), num, fp);
}else{
fread(l.biases, sizeof(float), l.n, fp);
//如果使用了Batch Normalizationn(https://www.zhihu.com/question/38102762,
https://arxiv.org/abs/1502.03167),
那就加载三个参数
if (l.batch_normalize && (!l.dontloadscales)){
fread(l.scales, sizeof(float), l.n, fp);
fread(l.rolling_mean, sizeof(float), l.n, fp);
fread(l.rolling_variance, sizeof(float), l.n, fp);
}
fread(l.weights, sizeof(float), num, fp);
}
if(l.adam){
fread(l.m, sizeof(float), num, fp);
fread(l.v, sizeof(float), num, fp);
}
//if(l.c == 3) scal_cpu(num, 1./256, l.weights, 1);
if (l.flipped) {
transpose_matrix(l.weights, l.c*l.size*l.size, l.n);
}
//if (l.binary) binarize_weights(l.weights, l.n, l.c*l.size*l.size, l.weights);
#ifdef GPU
if(gpu_index >= 0){
push_convolutional_layer(l);
}
#endif
} if(l.type == CONNECTED){
load_connected_weights(l, fp, transpose);
}
if(l.type == BATCHNORM){
load_batchnorm_weights(l, fp);
}
if(l.type == CRNN){
load_convolutional_weights(*(l.input_layer), fp);
load_convolutional_weights(*(l.self_layer), fp);
load_convolutional_weights(*(l.output_layer), fp);
}
if(l.type == RNN){
load_connected_weights(*(l.input_layer), fp, transpose);
load_connected_weights(*(l.self_layer), fp, transpose);
load_connected_weights(*(l.output_layer), fp, transpose);
}
if(l.type == GRU){
load_connected_weights(*(l.input_z_layer), fp, transpose);
load_connected_weights(*(l.input_r_layer), fp, transpose);
load_connected_weights(*(l.input_h_layer), fp, transpose);
load_connected_weights(*(l.state_z_layer), fp, transpose);
load_connected_weights(*(l.state_r_layer), fp, transpose);
load_connected_weights(*(l.state_h_layer), fp, transpose);
}
if(l.type == LOCAL){
int locations = l.out_w*l.out_h;
int size = l.size*l.size*l.c*l.n*locations;
fread(l.biases, sizeof(float), l.outputs, fp);
fread(l.weights, sizeof(float), size, fp);
#ifdef GPU
if(gpu_index >= 0){
push_local_layer(l);
}
#endif
}
}
fprintf(stderr, "Done!\n");
fclose(fp);
}3、train_network(network net, data d)
这个函数是核心~
//network.c
float train_network(network net, data d)
{
//先看以下data的结构//data.h
typedef struct{
int w, h;
matrix X;
matrix y;
int shallow;
int *num_boxes;
box **boxes;
} data;//matrix.h
//这里rows是一次加载到内存中的样本的个数(batch*net.subdivisions),cols就是样本的维度,**vals指向的是样本的值
typedef struct matrix{
int rows, cols;
float **vals;
} matrix; assert(d.X.rows % net.batch == 0);
int batch = net.batch;
//注意,n现在表示加载一次数据可以训练几次,其实就是subdivisions
int n = d.X.rows / batch;
float *X = calloc(batch*d.X.cols, sizeof(float));
float *y = calloc(batch*d.y.cols, sizeof(float));
int i;
float sum = 0;
for(i = 0; i < n; ++i){
//完成数据拷贝,从d拷贝到X和y中
get_next_batch(d, batch, i*batch, X, y);//data.c
void get_next_batch(data d, int n, int offset, float *X, float *y)
{
int j;
for(j = 0; j < n; ++j){
//offset就是第几个batch(i*batch)了,j表示的是每个batch中的第几个样本(图像)
int index = offset + j;
//void *memcpy(void *dest, const void *src, size_t n);
//memcpy函数的功能是从源src所指的内存地址的起始位置开始拷贝n个字节到目标dest所指的内存地址的起始位置中
memcpy(X+j*d.X.cols, d.X.vals[index], d.X.cols*sizeof(float));
memcpy(y+j*d.y.cols, d.y.vals[index], d.y.cols*sizeof(float));
}
} float err = train_network_datum(net, X, y);//network.c
float train_network_datum(network net, float *x, float *y)
{
#ifdef GPU
if(gpu_index >= 0) return train_network_datum_gpu(net, x, y);
#endif
network_state state;
*net.seen += net.batch;
state.index = 0;
state.net = net;
state.input = x;
state.delta = 0;
state.truth = y;
state.train = 1;
//这两个函数才是整个网络的重中之重,我们下一节讲
forward_network(net, state);
backward_network(net, state);
float error = get_network_cost(net);//network.c
float get_network_cost(network net)
{
int i;
float sum = 0;
int count = 0;
for(i = 0; i < net.n; ++i){
//获取各层的损失,用`$grep -rn "l.cost"`可以看出,只有detection层有cost,因为这个复制函数在前向传播里,我们下节再详细分析
if(net.layers[i].cost){
sum += net.layers[i].cost[0];
++count;
}
}
//返回平均损失
return sum/count;
} if(((*net.seen)/net.batch)%net.subdivisions == 0) update_network(net);
return error;
} sum += err;
}
free(X);
free(y);
return (float)sum/(n*batch);
}到这里我们只剩下最重要的两个函数:
forward_network(net, state);
backward_network(net, state);
(END)