Raft原理:作者亲自上阵讲解
参考视频:
https://www.youtube.com/watch?v=vYp4LYbnnW8&feature=youtu.be
步骤分解

1.Leader选举
选一个server当leader
检测到crashes,就选个新的leader
2.复制Log(正常情况)
Leader接受client请求,本地append log
leader将log复制到其他server(覆写不一致的地方)
3.安全
保持logs是一致的
只有获得最新的logs的servers可以成为leader
Server状态以及RPCs

初始化是Follower(被动的,仅仅傻傻地等待心跳)
如果一直等不到,那就成为Candidate。(发起RequestVote RPCs,大家来投我当leader啊)
- 如果获得大多数的支持,赢得了选举,就成为了leader(发起
AppendEntriesRPCs: 复制我的log,发心跳来维持我的统治)
只要发现更高的term,我就乖乖变回follower。
Terms(决定哪些信息是过期的)
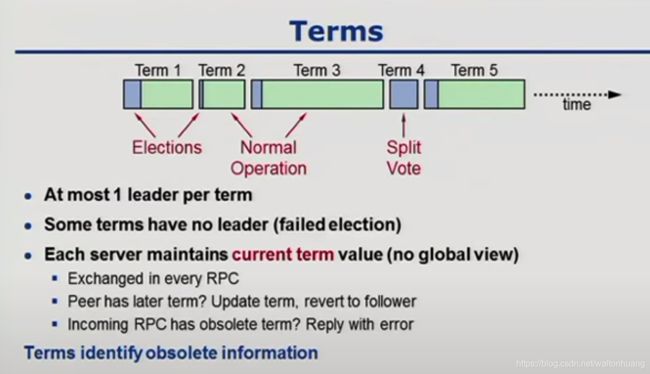
- 每个term最多1个leader
- 有些term是没有leader的(选举失败)
- 每个server维护一个
current term的值(但是都不知道全局的term是啥样,没有上帝视角)
– 每次RPC都交换信息
– 发现我的小伙伴有更新的term?好,那你是大哥,我信你,我把本地的term改成跟你一样,我还是乖乖当follower
– 来一个RPC请求有过期的term?告诉他你可能搞错了兄弟。reply error
Leader选举
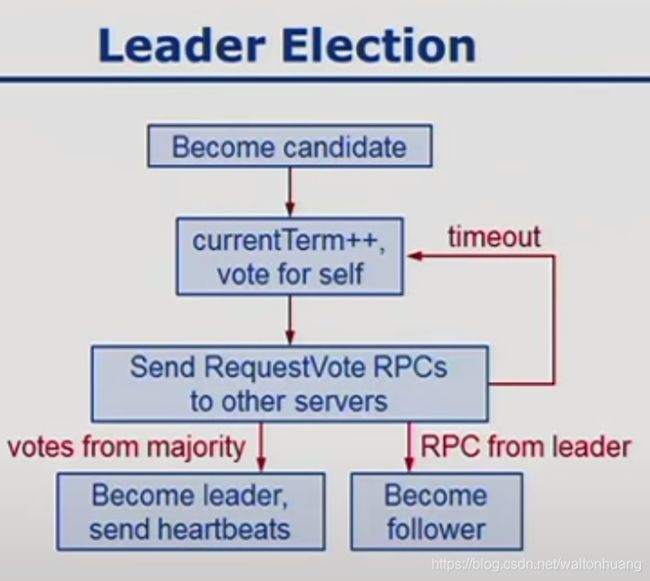
成为Candidate
本地currentTerm++,自己给自己投一票
发送RequestVote RPCs给其他servers(超时重试上一步)
获得大多数支持:成为leader,发心跳。
收到leader的RPC,乖乖当follower。
选举的正确性
Safety:每个term最多一个winner
每个server 每个term只投一票(持久化到硬盘)
赢得大多数选票才能赢得选举
Liveness:总有人最终要赢
选举超时: 是个在[T,2T]的随机数,如150-300ms
一般情况,有一个server会首先超时然后赢得选举
当T >> 广播时间的时候,工作良好
随机数是你的好朋友,实践证明比ranking好使
具体是ranking可能要考虑很多corner case
随机数的逻辑相对简单清晰
常规操作

客户端发送command到leader
leader 本地append log
leader 发送 AppendEntries RPCs给所有Followers
一旦有新的entry committed
- Leader 在自己的状态机执行 command,返回结果给client
- Leader在接下来的
AppendEntries中通知Followers,哪些entries被committed - Followers在自己的状态机执行 command
如果followers 挂掉了或者反应迟钝
- Leader会重试
AppendEntries直到成功
常规情况下性能不错
- 一个成功的RPC发给大多数的servers
Log 结构
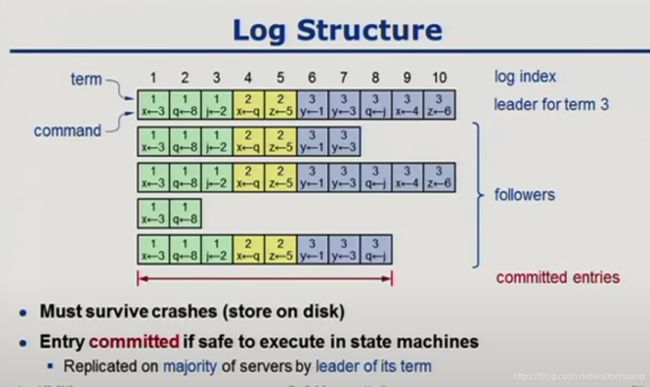
每个log 都保存了term
什么叫committed?
大多数的机器都保存了一样的log。如同上图的committed entries
Log 不一致
一旦有机器挂了,就会出现不一致

遇到这种奇怪的情况,Raft怎么解决呢?
目标:最小化special code来修复不一致
- Leader就认为自己的log是对的
- 正常的operation可以修复所有不一致
Log Matching Property

如果不同的servers 的log entries有一样的index 和 term
- 他们保存了相同的command
- 所有前面的entries都相同
如果一个entry committed,所有前面的entries都被committed
AppendEntries 一致性检查
AppendEntries RPCs 包括了 前一个entry的
Follower 必须包含matching entry,否则他会拒绝请求
- Leader就需要用更低的log索引请求
实现一个induction step,保证Log Matching Property
看图好理解:

注意前提:leader的log永远正确
问题来了,我们怎么知道leader的log就一定正确呢?
Safety: Leader Completeness
一旦一个log entry committed,所有未来的leader都要保存这个entry。
servers如果没有完整的log,是不能被选举的
- Candidates 在RequestVote RPCs中包括了index和term
- 每个server在投票的时候,如果自己的log更好,那就拒绝,投反对票
- 怎么作为好? 按照
排序

上面这个图这个例子,如何比较呢
先看谁的lastTerm大,首先S5就干不过别的。然后再看谁更长(lastIndex大)S3比S1和S4强。所以S3是真正的大哥。
有个问题:按照前面的逻辑,如果S1先timeout,先发的RequestVote,S3后发,S2,S4,S5都干不过S1,都会同意让S1当老大,那S3不就当不了老大了?
彩蛋:Raft这个名字怎么取的

Replicated And Fault Tolerant的缩写
复制的,容错的
Raft代表木筏:可以帮助你躲过Paxos这个万恶的大山