Docker资源限制
Linux的Cgroup:
Linux系统中经常有个需求就是希望能限制某个或者某些进程的分配资源。也就是能完成一组容器的概念,在这个容器中,有分配好的特定比例的cpu时 间,IO时间,可用内存大小等。于是就出现了cgroup的概念,cgroup就是controller group,最初由google的工程师提出,后来被整合进Linux内核中。
Cgroup是将任意进程进行分组化管理的Linux内核功能。cgroup本身提供将进程进行分组化管理的功能和接口的基础结构。
Cgroups子系统介绍:
子系统:
子系统就是资源控制器,每种子系统就是一个资源的分配器,比如cpu子系统是控制cpu时间分配的。
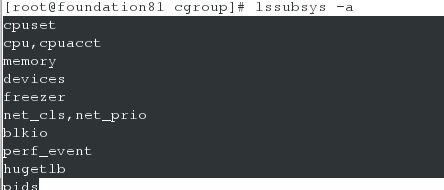
可以使用lssubsys -a来列出系统支持多少种子系统
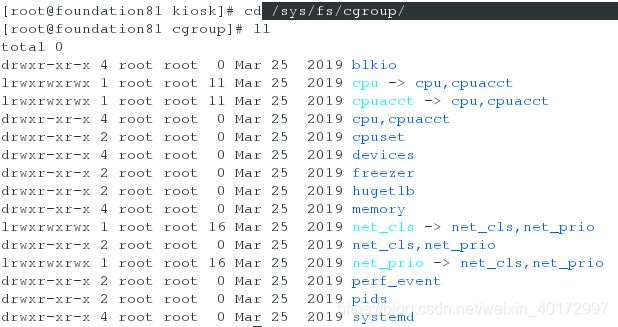
使用ls /sys/fs/cgroup/ 来显示已经挂载的子系统
- blkio: 这个subsystem可以为块设备设定输入/输出限制,比如物理驱动设备(包括磁盘、固态硬盘、USB等)。
- cpu: 这个subsystem使用调度程序控制task对CPU的使用。
- cpuacct: 这个subsystem自动生成cgroup中task对CPU资源使用情况的报告。
- cpuset: 这个subsystem可以为cgroup中的task分配独立的CPU(此处针对多处理器系统)和内存。
- devices 这个subsystem可以开启或关闭cgroup中task对设备的访问。
- freezer 这个subsystem可以挂起或恢复cgroup中的task。
- memory 这个subsystem可以设定cgroup中task对内存使用量的限定,并且自动生成这些task对内存资源使用情况的报告。
- perfevent 这个subsystem使用后使得cgroup中的task可以进行统一的性能测试。{![perf: Linux CPU性能探测器,详见https://perf.wiki.kernel.org/index.php/MainPage]}
- *net_cls 这个subsystem Docker没有直接使用,它通过使用等级识别符(classid)标记网络数据包,从而允许 Linux 流量.
若系统无cgroup,可以使用以下命令安装cgroup服务
[root@server1 ~]# yum search cgroup
[root@server1 ~]# yum install -y libcgroup.x86_64
[root@server1 ~]# yum install -y libcgroup-tools.x86_64
mount -t cgroup 可以用于查询系统中已经mount 的cgroup的文件系统,这里的t表示type

Docker资源限制:
1.针对mem内存的限制
memory.memsw.limit_in_bytes:内存+swap空间使用的总量限制。
memory.limit_in_bytes:内存使用量限制。
(1)设定资源限制参数:内存<=200M
计算200M内存对应的字节数
换算公式: 1MB=1024KB 1KB=1024Byte

进入目录/sys/fs/cgroup/memory下,创建一个文件夹,就创建了一个control group了
发现x1目录下自动创建了许多文件:(可以发现这些文件与上级目录memory下的文件是一样的,该目录继承了父目录的所有文件)
这些文件的含义如下:

限制内存使用我们就可以设置memory.limit_in_bytes
[root@server1 x1]# cat memory.limit_in_bytes
9223372036854771712 ##内存不做限制时的大小
[root@server1 x1]# echo 209715200 > memory.limit_in_bytes

查看系统内存使用情况:

测试:
<1>100M
[root@server1 x1]# cd /dev/shm/
[root@server1 shm]# cgexec -g memory:x1 dd if=/dev/zero of=bigfile bs=1M count=100
cgexec是直接在某些子系统中的指定控制组运行的程序, memory:x1 是被指定的程序

直接从Mem内存中取走100M
<2>300M
[root@server1 shm]# rm bigfile
[root@server1 shm]# cgexec -g memory:x1 dd if=/dev/zero of=bigfile bs=1M count=300
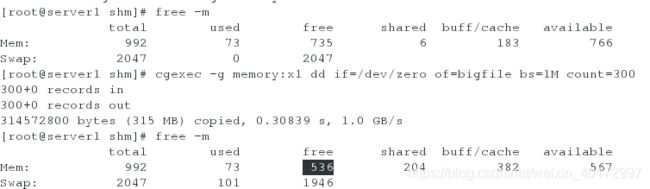
对比前后系统内存可以看出300M分别是从Mem内存中取走的200M和从Swap分区中取走的100M
400M是是从Mem内存中取走的200M和从Swap分区中取走的200M:

(2)设定资源限制参数:内存+交换分区<=200M:
[root@server1 x1]# echo 209715200 > memory.memsw.limit_in_bytes

测试:
<1>100M
没有超过200M。所以可以进行截取。
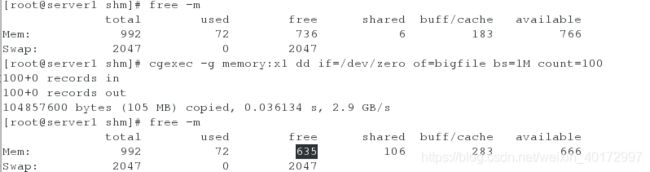
<2>300M
超过200M,所以被拒绝,进程直接杀死。
![]()
容器运行时可以指定限制内存的大小:

[root@server1 shm]# docker run --memory 209715200 --memory-swap 209715200 -it --name vm1 ubuntu

[root@server1 shm]# cd /sys/fs/cgroup/memory/
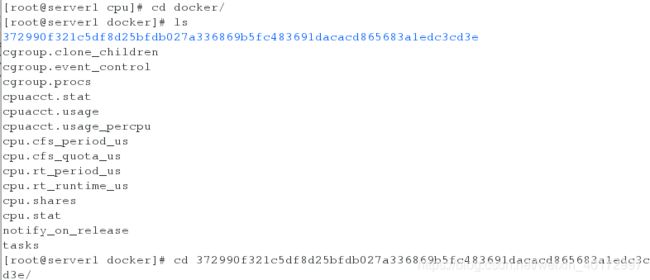
[root@server1 memory]# cd docker/
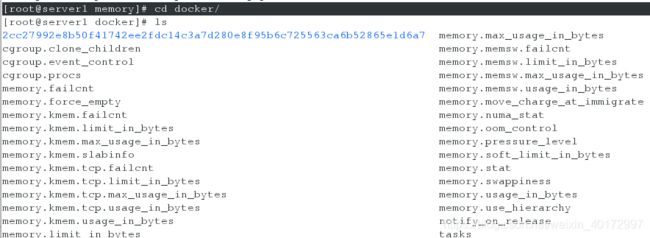
[root@server1 docker]# cd 2cc27992e8b50f41742ee2fdc14c3a7d280e8f95b6c725563ca6b52865e1d6a7/
[root@server1 2cc27992e8b50f41742ee2fdc14c3a7d280e8f95b6c725563ca6b52865e1d6a7]# cat memory.limit_in_bytes
209715200
[root@server1 2cc27992e8b50f41742ee2fdc14c3a7d280e8f95b6c725563ca6b52865e1d6a7]# cat memory.memsw.limit_in_bytes
209715200

![]()

2.针对cpu的限制
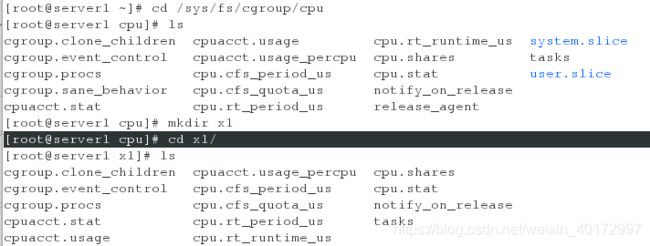
[root@server1 ~]# cd /sys/fs/cgroup/cpu
[root@server1 cpu]# mkdir x1
[root@server1 cpu]# cd x1/
[root@server1 x1]# cat cpu.cfs_period_us
100000 ## cpu分配的周期(微秒),默认为100000[root@server1 x1]# cat cpu.cfs_quota_us 该参数表示该control group限制占用的时间(微秒),默认为-1,表示不限制。如果设为50000,表示占用50000/10000=50%的CPU。
-1[root@server1 x1]# echo 20000 > cpu.cfs_quota_us
这里将cpu.cfs_quota_us的值设置为20000,即设置占用20%的CPU,。

测试:
[root@server1 x1]# dd if=/dev/zero of=/dev/null &
[1] 1224
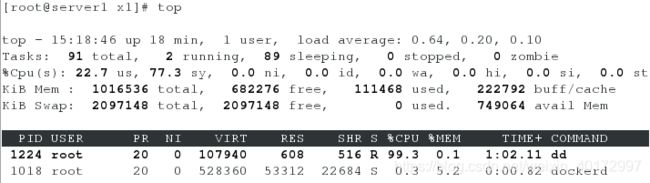
可以看出默认占用内存为100%
重新打开一个shell:
[root@server1 ~]# ps ax

[root@server1 ~]# cd /sys/fs/cgroup/cpu/x1/
[root@server1 x1]# cat tasks
[root@server1 x1]# echo 1224 > tasks ##将dd命令的进程号扔到任务列表中进行控管
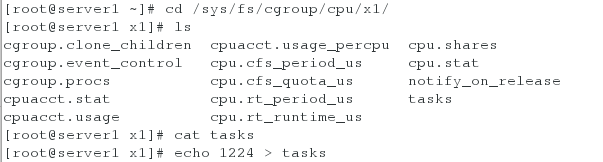
此时占用内存为20%:

对运行的docker进行cpu控制:
不进行控制时,默认占用量为100%
[root@server1 ~]# docker run -it --name vm1 ubuntu
root@cd862649072d:/# dd if=/dev/zero of=/dev/null
重新打开一个shell查看cpu占用情况

删除该容器:
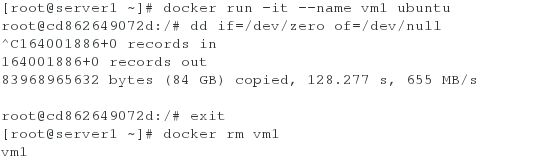
对运行的docker进行cpu控制:
[root@server1 ~]# docker run -it --name vm1 --cpu-quota=20000 ubuntu
root@372990f321c5:/# dd if=/dev/zero of=/dev/null
可以看出,cpu占用量被控制在20%

![]()
3.针对io的速度限制
[root@server1 ~]# cat /sys/fs/cgroup/blkio/blkio.throttle.read_bps_device ##默认无io限制
![]()
[root@server1 ~]# docker run -it --device-write-bps /dev/sda:30MB ubuntu
[root@server1 ~]# docker run -it --device-write-bps /dev/sda:30MB ubuntu
root@ad238984cc79:/# dd if=/dev/zero of=file bs=1M count=300 oflag=direct ##oflag=direct表示直连io,不经过系统缓存
300+0 records in
300+0 records out
314572800 bytes (315 MB) copied, 11.406 s, 27.6 MB/s 速度是经过限制后的速度
4.进程冻结(进程中止,但依旧存在)
[root@server1 ~]# yum install -y iotop ##用来监视磁盘I/O使用状况的工具
先运行一个进程:
[root@server1 ~]# dd if=/dev/zero of=/dev/null &
[1] 1936

[root@server1 ~]# cd /sys/fs/cgroup/freezer/
[root@server1 freezer]# mkdir x1
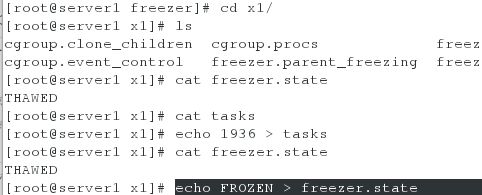
[root@server1 freezer]# cd x1
[root@server1 x1]# ls
cgroup.clone_children cgroup.procs freezer.self_freezing notify_on_release
cgroup.event_control freezer.parent_freezing freezer.state tasks[root@server1 x1]# echo 1936 > tasks ##将该进程扔入任务列表中进行管控
[root@server1 x1]# cat freezer.state ##默认是解冻状态
THAWED
测试:
- 进程冻结
[root@server1 x1]# echo FROZEN > freezer.state
ps命令查看进程,进程存在:

iotop查看进程,进程不存在,进程冻结:

- 进程解冻
[root@server1 x1]# echo THAWED > freezer.state

ps命令查看进程,进程存在:

iotop查看进程,进程存在,进程解冻:
增强docker容器的隔离性
利用LXCFS提升容器资源可见性:
Linuxs利用Cgroup实现了对容器的资源限制,但在容器内部依然缺省挂载了宿主机上的procfs的/proc目录,其包含如:meminfo, cpuinfo,stat, uptime等资源信息。一些监控工具如free/top或遗留应用还依赖上述文件内容获取资源配置和使用情况。当它们在容器中运行时,就会把宿主机的资源状态读取出来,引起错误和不便。
LXCFS简介
社区中常见的做法是利用 lxcfs来提供容器中的资源可见性。lxcfs 是一个开源的FUSE(用户态文件系统)实现来支持LXC容器,它也可以支持Docker容器。
LXCFS通过用户态文件系统,在容器中提供下列 procfs 的文件。
- /proc/cpuinfo
- /proc/diskstats
- /proc/meminfo
- /proc/stat
- /proc/swaps
- /proc/uptime
比如,把宿主机的 /var/lib/lxcfs/proc/memoinfo 文件挂载到Docker容器的/proc/meminfo位置后。容器中进程读取相应文件内容时,LXCFS的FUSE实现会从容器对应的Cgroup中读取正确的内存限制。从而使得应用获得正确的资源约束设定。
Docker环境下LXCFS使用:
[root@server1 ~]# yum install -y lxcfs-2.0.5-3.el7.centos.x86_64.rpm
[root@server1 ~]# cd /var/lib/lxcfs/
[root@server1 lxcfs]# ls ##没有文件
[root@server1 lxcfs]# lxcfs /var/lib/lxcfs/ &

[root@server1 lxcfs]# cd /var/lib/lxcfs/
[root@server1 lxcfs]# ls
cgroup proc
[root@server1 ~]# docker run -it --name vm1 -m 200m -v /var/lib/lxcfs/proc/cpuinfo:/proc/cpuinfo \
> -v /var/lib/lxcfs/proc/diskstats:/proc/diskstats \
> -v /var/lib/lxcfs/proc/meminfo:/proc/meminfo \
> -v /var/lib/lxcfs/proc/stat:/proc/stat \
> -v /var/lib/lxcfs/proc/swaps:/proc/swaps \
> -v /var/lib/lxcfs/proc/uptime:/proc/uptime ubuntu

我们可以看到total的内存为200MB,配置已经生效。