深度探索JFR - JFR详细介绍与生产问题定位落地 - 2. 通过一个线上调优例子了解JMC 与 Event 结构与详细配置
查看 JFR 事件的工具 - JMC (Java Mission Control)
官网地址:https://adoptopenjdk.net/jmc.html
国内下载起来比较慢,建议在aws上面建一个欧洲法兰克福的实例,在这个实例上先下载好,然后传输到本地。或者直接用我下面提供的连接下载,我也会跟着官网上面的版本进行更新的。
我的私人下载地址:https://zhxhash-blog.oss-cn-beijing.aliyuncs.com/resources/jmc.zip
如果更新的不够及时,欢迎大家留言提醒我要更新啦。谢谢
首先打开 jmc,我们通过 “文件” -> “打开文件” 来打开一个 jfr 文件。 由于 JFR 文件里面的数据要全部导入内存,而且 JMC 需要给这些数据做很多索引以及报表,最后的内存占用大概是原始文件的4~6倍左右。如果你的系统内存不足, JMC 也会提示你只截取一部分查看。最好你在 dump JFR 文件的时候,就利用 begin 还有 end 参数截取你感兴趣的时间段。
打开文件后, JMC 会自动对事件进行归类和分析,出一些报表出来。有些分析和建议非常有用,可以参考,报表也比事件更加直观。
但是就我个人使用倾向来看,我还是喜欢直接去看事件浏览器里面的具体事件。
我们先用一个简单的线上调优的例子,来初步了解下 JFR 的使用。
JVM 调优简单实例
线上某个实例,dump出了 jfr 文件。下载到本地,按照持续时间倒序查看 GC Event:

发现有一些耗时比较高的 GC 事件, 并且这些事件都是 Old GC。GC 原因是:G1 Humongous Allocation。
大型对象(Humongous)是大于 G1 中 region 大小50%的对象。频繁大型对象分配会导致性能问题。如果 region 里面包含大量的大型对象,则该region中最后一个具有巨型对象的区域与区域末端之间的空间将不会使用。如果有多个这样的大型对象,这个未使用的空间可能导致堆碎片化。针对这个原因,调整的方法一般是修改 region 的大小是这个 大对象的 2 倍以上。那么这个大对象有多大呢?
我们可以通过 Old Object Sample 这个 Event 来查看老对象采样,一般随着你的程序运行时间增长,这个采集会更加准确地命中到你最关注的对象。
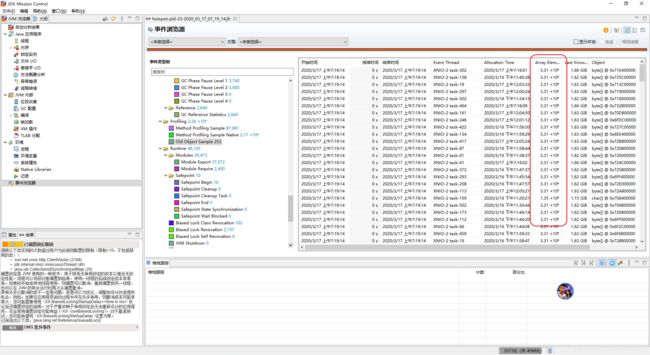
注意这个 Event 里面的 heap used 不是这个对象用的堆大小,而是当前所有对象占用的堆内存大小。这个对象大小,可以通过数组大小计算而出,这里最大就是 3.31 * 10^6 字节
我们再来看一下当前 G1HeapRegionSize 的配置,通过查看 Unsiged Long Flag Event:

发现大小是:4.19 * 10^6 字节,不足最大对象的两倍。所以,这里我们需要将 G1HeapRegionSize 至少调整到 6.62 * 10^6 字节
调整 G1HeapRegionSize 之后,不再出现 G1Old GC。
Event 数据结构以及配置结构
这里再提一下 Event 的结构,每个 Event 都会包括:
- Event 大小
- Event ID
- Event 产生的时间戳
- Event 持续时间
- 产生Event的线程 ID
- 相关 堆栈 ID
除了这些元素,每个 Event 还会有自己的 Payload,承载自己要采集的数据。但是注意一点,不是每个Event都会填充上面的这些字段,只是结构里面有这些字段,但是可能并不会采集。
Event采集,同样有以下这些公共配置:
- enabled,是否启用这个 Event 的采集:true 或者 false
- cutoff:截断,采集多长时间以内的这种 Event,支持单位配置,例如1d, 1h, 1m, 1s, 1ms, 1ns,配置为0则不截断
- stackTrace,是否启用堆栈跟踪:true 或者 false
- period,采集周期(时段):beginChunk(每个 Data Chunk 的开头,在每一个 Data Chunk 写满另起一个的时候,立刻采集一次),everyChunk(每个 Data Chunk 的,在每一个 Data Chunk 写到占用一半空间限制的时候,立刻采集一次),endChunk(每个 Data Chunk 的结束,在每一个 Data Chunk 写满,立刻采集一次),或者配置具体时间,支持单位配置,例如1d, 1h, 1m, 1s, 1ms, 1ns;对于 Data Chunk 的解释,请参考上一节。
- threshold,阈值:Event 持续时间超过这个阈值才会采集,支持单位配置,例如1d, 1h, 1m, 1s, 1ms, 1ns
Event采集详细配置, JDK自带两个模板,在 $JAVA_HOME/lib/jfr 目录下,里面配置格式是一个xml文件,取其中一个配置举个例子,例如:
true
false
0 ns
这个就是 OldObject 采集 Event 的配置,这里配置为启用这个采集,不采集堆栈,不截断。你也可以加上 period 和 threshold 配置,但对这个 Event 没啥效果就是了。这里有个 control 属性,接下来会提到。
我们一般通过 JMC 来配置这些 jfr 文件。打开 窗口->飞行记录模板管理器,将 default.jfc 和 profile.jfc 导入进去,我们来看下 default.jfc。点击编辑,弹出一个快速编辑模板,这里不会配置每一个具体 Event,而是在整体上让你快速配置。这个配置,是基于 default.jfc 里面的 selection 标签还有 condition 标签。举个例子:

这里配置的 Memory Leak Detection 对应其中 Memory Leak Detection 的 selection 标签,可选项有四个,只有 memory-leak-detection 为 off 的时候,memory-leak-detection-enabled 为 false, 这样 OldObjectSample 的 enabled 就为 false,因为 enable 的 control 属性是 memory-leak-detection-enabled。
这就是可以比较笼统的配置的原理。点击 高级,会跳转到所有 Event 的具体配置。在接下来的章节,我们来讲一下所有 Event 的采集详细配置。