分布式协议Raft浅析
背景
Paxos协议晦涩难懂,在工程实践中难以得到应用。Raft是一种分布式一致算法,是RaplicationAnd Fault Tolerant的缩写。Raft相对来说容易理解,容易应用到工程实践中去。所以Raft会大行其道。
Raft协议
- Raft的协议主要包含以下3个特性
- leader选举(leader election)
- 主要涉及到3个角色:leader, follower和candidate。leader在Raft协议处于核心地方,数据是单向流动的。从leader->follower。candidate不接受leader发送的心跳。
- candidate:如果follower在规定的时间内没有收到leader的心跳,follower则认为leader已死。 该follower作为candidate,发起投票。如果接收到来自集群的大多数follower的投票,则该candidate被选举为新的leader(如下candidate被选举为leader的过程)
- 一般情况下客户端不会把请求发送到follower。 即使客户端将请求发送到follower, follower会拒绝client的请求,并把leader的ip返回给client 。
- 初始化时,所有的节点都是follower。当一个节点在规定的时间内没有收到leader的心跳,自己会转变成一个candidate,term加1。并向其他的follower发起投票。大多数的follower返回给candidate的投票,该candidate成为leader。
- follower接收leader的replication log。
- 日志复制(log replication): leader将follower执行的指令,心跳,leader的快照和配置(Cold, Cold,new)都通过replication log传递。
- 安全性(safety): 即无论何种情况(例如网络时延,丢包等情况) 最终返回client的结果是一致的。
- leader选举(leader election)
- Raft 简述
- 通过日志的复制(传递)来实现各个机器状态(执行命令)的传递。
- 每个机器(follower)接收leader的日志(是一种'推'的方式)。日志中按顺序存储命令。每个状态机按照顺序执行日志中的命令。日志中的命令(leader从client接收的请求。leader会将请求中的内容写入日志中)
- 如下图图1所示
- Consensus Module接收从客户端发来的请求. Consensus Module会和其他机器(follower)上的Consensus Module连接, 保证其他机器接收的replication log中包含相同顺序的指令(即客户端发送给leader的执行命令)。即每个机器执行的命令顺序是一致的。
- leader从client获取执行的命令, 之后通过replication log传递给其他server(follower)。leader告诉follower replication log是否安全(即log的顺序是否有序一致).如果有序一致,则可以通过follower的State Machine(状态机)执行replication log中的内容。
- leader自己决定client 请求的内容在log中的位置,不需要和其他的follower协商。数据流的顺序是从leader到其他的follower。这个特性决定了Raft的效率要比Paxos的高。
- follower如果和leader无法连接,无法连接的follower会成为candidate(此时term + 1), 向其他的follower发起leader的选举。其他的follower会响应这个candidate发起的投票,收到大多数的投票的candidate会成为新的leader。
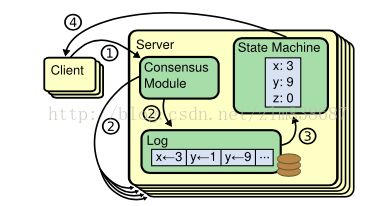
图1: ConsensusModule处理log的一致性
- candidate被选举为leader的过程.如下图2
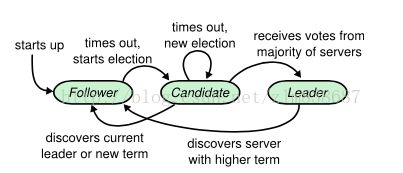
图2:follower作为新的leader的过程
- Folloer和leader的连接超时,该Follower作为candidate会发起一次选举.
- 如果该candidate接收到大多数选票,则该candidate有可能被选举为新的leader
- leader的选举过程
- 正常情况下, leader会通过心跳(心跳不会携带entry log, 客户端发起请求的指令)和它的follower保持联系。如果follower在其周期内没有收到leader发来的心跳,则follower会认为leader已经dead了,它会重新发起选举。
- 此时,没有收到这个leader心跳的follower会增加自己的term,身份从follower改变为candidate。它会给自己投一票,然后发送投票申请到其他follower。(正所谓老大死了,我做老大)

- 发生以下三种情况, b中描述的follower会终止发送投票
- 自己当了老大(leader)
- 其他follower会根据先到先得的原则,给最早发来投票申请的candidate发送投票(vote)。
- 每个follower只能给一个candidate投票。
- 新的leader产生,它会立刻把新的心跳发送给其他follower。并终止正在进行的选举。
- 别人当了老大.
- 如果新leader的term大于候选者(candidate)的term,则candidate认为新的leader是合法的
- 如果新leader的term小于候选者(candidate)的term,则candidate认为新的leader是非法的,自己仍然是candidate的身份.
- 这个周期(term)内没有产生新的老大
- 多个follower成为新的candidate,没有新的leader产生(即每个candidate都没有收到绝大多数(超过一半)的投票)。会进入无限死循环的过程。
- 为了避免1的情况发生,Raft的follower和Leader的timeout时间是随机的(150-300ms)。避免多个follower同时进入candidate状态。所以正常情况下,只有一个follower会进入candidate的身份。
- 还有一种解决方案,就是每个candidate都有rank(联系实际生活,每个想当老大的地位不同,地位越高,越容易成为新的老大。厂长退休,很多副厂长转正成为厂长)
- 自己当了老大(leader)

- 日志复制(log replication)
- leader处理客户端发来的指令(command),该指定最后被replicated state machine执行。leader会把该指令放在replication log中,通过rpc并发的发送给各个follower。如果replication log被安全的发送给各个follower(类似tcp/ip握手协议,follower需要应答leader),leader的指令(command)会被leader的replicated state machine执行(committed),并把执行结果返回给client.
- Raft按照以下规则构建Log Machine Property
- two log entries 在不同的log(leader传递给各个follower的replication log)有相同的index(指令在log中的位置)和term,则这两个log entries存储相同的指令。
- two log entries在不同的log(leader传递给各个follower的replication log)有相同的index和term,则这两个log entries在各个follower执行的顺序是一致的。
- 如果发生不一致的情况,leader会强制把replication log推给follower。也就是说follower的replication log被leader的replication log覆盖,保证follower的执行顺序和leader一致。也就是保证了其安全性。
- AppendEntries consistent check会检查leader和follower的log是否一致.如果不一致,leader会减少nextIndex,即指针会移动到上次分发log的index,并且重试AppendEntries RPC,直到follower的log和leader的log保持一致。
- leader不会删除或者覆盖自己已经commit的log。没有commit的log 也可能被leader删除。
- 正常情况下,一次AppendEntries RPC过程就可以完成leader和follower的日志复制
- candidate会发送选票到各个follower,如果follower的log比candidate的log更新,则follower会拒绝candidate的投票。
- 判断是否新日志的规则
- 首先判断term的值,term越大越新
- 如果term相同,log越大越新
- 安全协议
- leaderu是第u term阶段的leader, leadert是第t term阶段的leader。termu > termt
- commit log在leaderu选举阶段是不会出现在leaderu的log中的(联系现实生活,大选阶段是宣传和造势的阶段,不是干事的阶段:)。之所以进行选举,是因为term u阶段follower无法和leader在规定的时间内进行连接。所以上一个阶段的commit log是无法到leaderu的log中。

- t term阶段大多数的follower会收到leadert发送的commit log。在u term阶段大多数的follower会收到candidateu(以后的leaderu)发来的选票。所以这个过渡阶段有些follower既会收到leader_u的commit log,也会收到candidate_u的选票。此时该follower会处于矛盾状态。
- 如果t term阶段commit log的时间比u term阶段的选票时间要早,则接收该commit log。否则拒绝该commit log。因为u term在时间上比 t term更'新'。
- 即使拒绝了t term阶段的commit log.上一个阶段的follower(voter)也会存储leadert发来的commit log。
- follower将选票投给了新的leader, 也就是leaderu。leaderu需要把log更新到最新。此时会产生两种矛盾情况发生。
- leaderu的log必须大于等于follower(即接收到选票有接收到commit log的follower)的log大小。也就是说leaderu的log是包含follower 的commit log
- 所以u term 阶段的log必须包含t term阶段的所有的commit log
- Log Machine Property保证新的leader产生的log包含了老的term阶段产生的log
- follower(candidate) crash
- 如果follower(candidate)crash, leader发送到follower(candidate)的AppendEntries RPC请求或者其他candidate发来的投票请求(RequestVote)都会失败。失败后,Raft会重试上述方式。crash的follower重启后,会成功处理RPC请求。
- 如果crash发生在RPC请求之后,response之前,follower会收到相同的RPC,由于RPC是幂等的,后来的RPC请求follower会忽略。
- Raft的时间限制
broadcastTime <= electionTimeout <= MTBF
- broadcastTime: leader发送请求到各个follower, 并且各个follower response的时间。
- electionTimeout:是选举时间。一般设置为0.5ms-20ms之间。
- MTBF:机器损坏的周期。
- Raft对集群中成员变化的处理
- Raft集群中成员的增减导致集群配置的改变,这种改变可能导致在同一个term(阶段)中存在两个leader。
- 一些系统会在第一阶段禁用旧的配置,这个阶段client无法连接cluster。第二阶段启用新的配置。
- Raft采用过度阶段(joint consensus Cold,new)保证顺序安全。即不会反正存在两个配置,导致集群执行的命令是不一致的。
- 每个follower会收到新老两个配置。
- 任何一个收到新老两个配置的机器(follower),可以作为一个leader提供服务。
- 新老两个配置在集群中大多数的follower中都存在。
- Raft采用的过度阶段协议允许在该阶段内client连接服务器。
- Cluster configuration 以特定形式存储在replication log中。当leader收到请求的配置从Cold到Cnew的过程中时, Cold,new过度阶段协议会以特定形式存储在replication log中,之后会把log传递给各个follower。
- 当一个leader crash的时候,新的leader可能采用Cold或者Cold,new作为配置,也就是说新的leader不可能采用Cnew作为整个集群的配置。
- Raft的过度协议决定了拥有Cold,new的follower才可以作为新的leader。之后新的leader采用Cnew作为整个集群新的配置,并把新的配置通过replication log传递给各个follower。
- 过度协议(joint consensus)可能会带来的问题
- 新的follower加入时间比较长,这段时间内replication log可能无法commit log。此时Raft会把新加入的member当做非投票的member。
- Cnew中不包含leader时,新的leader会从Cold中选举。
- Cnew配置中,cluster的多个节点处于不可用状态。这些阶段收不到心跳,这时会产生新一轮的选举,新的leader会产生。不可用的节点处于不可用状态。
- 日志的压缩
- Raft采用快照的方式压缩replication log。系统的整个状态都会以快照的方式存储在可用的存储中。之后当前时刻的整个日志都会丢弃。之前的snapshot也会被删除。
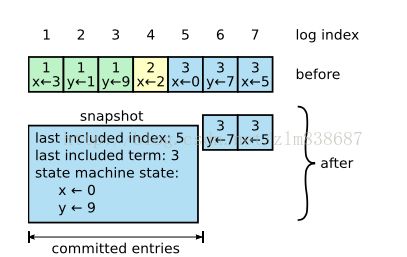
图3:日志的snapshot方式
- commit log(1->5)有新的快照。x<-0, y<-9。snapshot最后会包含下term处理的index和term。
- 新加入的节点或者异常的节点,leader会把snapshot发送给它,使这个节点更新到最新的状态。
- 这种处理方式仍然保留了数据流是从leader到follower的过程。只不过follower根据leader的snapshot,自己组织数据。
- 快照方式仍然存在两个问题
- 什么时刻打快照。太频繁会浪费磁盘的性能。通用的方式是当replication log大小达到一定大小时,打一个快照。
- 打快照会浪费很多处理正常请求的时间。解决方案是:Copy-on-write方式。
- Raft和Paxos的区别
- Raft比Paxos更容易理解,代码实现更简单(有点像做广告,比较虚)
- 配置更新(新的节点加入或者故障节点移除), paxos会采用两阶段协议,第一个阶段先禁止client连接cluster,之后把新的配置更新到follower节点。Raft协议采用过度阶段。即当leader收到Cold,Cnew两个配置之后,进入过度节点(joint consensus)。leader会把Cold,new通过replication log传递给各个follower。
- Raft协议是单向数据流。强调了leader的核心作用。弱化了follower的功能。
- zk有10种消息类型;Raft有4中消息类型,2中RPC请求,2中RPC应答。
现有系统的思考和借鉴
- 当前蘑菇街数据平台离线计算ETL的主要工具是hdata。hdata在处理小规模数据(百万级别的数据)性能表现尚可。但是处理大规模数据,其单机性能的短板就暴露出来的。所以hdata分布式就呼之欲出了。
- 目前分布式系统大概有两种组织形式
- 有中心节点的模式,即master-slave模式。该模式是业界很多分布式系统的常规模式,如hadoop NameNode和dataNode;Raft的Leader和Follower。采用中心节点模式相对来说简单,客户端直接和中心节点连接。中心节点控制各个子节点。
- 非中心节点模式。即所谓的p2p模式。本人才疏学浅,p2p模式还没有研究过。
- hdata分布式的考虑
- Master节点:Master是一个相对瓶颈的节点,所以master节点进行分配'轻'一点的工作。结合hdata的现状,master节点主要任务是分片,收集进度和维护和各个worker节点的心跳。
- 分片:分片相对来说是比较'轻'的任务。假设集群有1个master,5个worker。假设读取mysql的分片, 根据主键计算出max(id), min(id)。之后根据每次获取的条数,如10000条。计算每个worker的分片。以此类推。
- 计算出第一个worker获取的分片为min(id) <= id < min(id) + 10000;
- 第二个worker获取的分片为:min(id) + 10000 < id
- 第三个worker获取的分片为:min(id) + 20000 <= id < min(id) + 30000;
- 第五个worker获取的分片为:max(id) - 10000 < id <= max(id);
- 第四个worker获取的分片为:max(id) - 20000 < id <= max(id) - 10000;
- worker定期向master汇报worker的状态。
- worker定期向master汇报自己的进度。master汇总各个worker的进度,向client汇报整个job的进度。
- 分片:分片相对来说是比较'轻'的任务。假设集群有1个master,5个worker。假设读取mysql的分片, 根据主键计算出max(id), min(id)。之后根据每次获取的条数,如10000条。计算每个worker的分片。以此类推。
- worker节点负责具体的读取和写入操作
- 【todo】如果一个worker 执行了一部分后crash了,要考虑怎么回滚已经write的数据,将分片重新分配到其他的worker上。
- Master节点:Master是一个相对瓶颈的节点,所以master节点进行分配'轻'一点的工作。结合hdata的现状,master节点主要任务是分片,收集进度和维护和各个worker节点的心跳。
参考资料
- raft_分布式协议简单说明
- Diego Ongaro and John Ousterhout Stanford University In Search of an Understandable Consensus Algorithm (Extended Version)