LinkedHashMap引发的内存泄漏以及解决过程
今天在使用LinkedHashMap的时候踩了一个坑,用了差不多一整天的事件才定位并解决掉,这里记录并于大家分享下经验。放着这么多Map不用非要去碰比较冷门的LinkedHashMap干啥?这跟我的使用场景有关系。先介绍下我选择它的原因。
应用场景:
我们开发了一套网关,一期已经上线,可以进行正常的路由转发、限流保护、动态配置、灰度发布等基础功能了,二期我想给它加入缓存容灾的功能,简单说就是存储200状态的南向报文当它们服务异常时我利用这些缓存来为客户端提供响应。当然细节上并没有这么简单暴力,会对南向host、path、核心参数、http方法、返回状态码等进行动态配置并作为我缓存逻辑的依据,但他们不是我们本期讨论的重点,我所关心的是必须使用“舱壁模式”为每一个南向服务分配内存资源,把它们进行隔离。
泄漏版:
一开始选择用LinkedHashMap是出于以下考虑:
1 LinkedHashMap可以对Map大小进行限制,符合舱壁模式的要求。
2 LinkedHashMap支持LRU(最少使用)释放策略,正好贴合我的应用场景。
3 虽然它不是线程安全的,但是对我的业务并没有影响。如果同一时间内两个线程一起对同一个HttpRequest进行写入,无论谁覆盖谁对于我后面容灾时使用这块缓存都无所谓。
这个是LinkedHashMap核心构造器:
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}我还利用Google的Guava对它进行了一层封装,方面后续使用,代码如下:
/**
* lru即为LinkedHashMap中的accessOrder (用于缓存)
* true:将按照访问顺序; false:按照插入数序
* @param
* @param
*/
public class IsolateHashMap extends ForwardingMap{
private LinkedHashMap isolateMap;//用LinkedHashMap实现
public IsolateHashMap(final int cap, boolean lru){
super();
this.isolateMap = new LinkedHashMap(cap, 0.75f, lru){
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
//如果条件当前size大于cap,就删除最早的(返回true)
return size() > cap;
}
};
}
public IsolateHashMap(final int cap){
super();
this.isolateMap = new LinkedHashMap(cap, 0.75f, true){
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
//如果条件当前size大于cap,就删除最早的(返回true)
return size() > cap;
}
};
}
@Override
protected Map delegate() {
return isolateMap;
}
} 好,信心满满,先压个5分钟试试,一看在业务场景极限差的情况下qps只下降了8-9%左右,对于这层缓存保护来说牺牲这么点性能是可以接受的。
但是!!!!
5分钟后qps开始往下掉了,到了15分钟时候网关层几乎不能提供服务了~~~纳尼,到底哪里出了问题,赶紧看下JVM的情况。
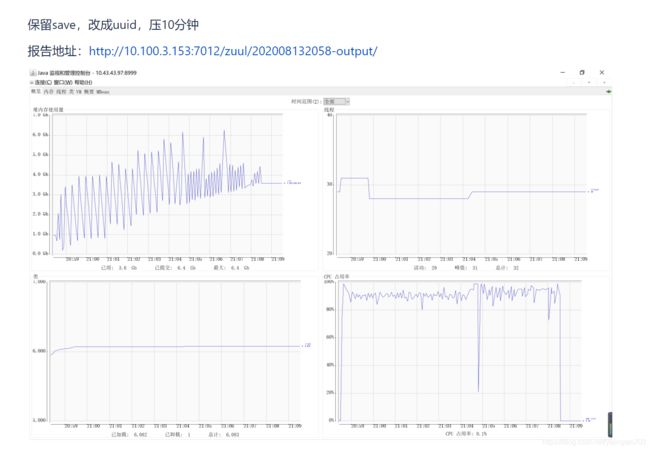
我去,肯定内存泄漏了。
1 看gc总的走向内存越来越高,但是按照我们舱壁模式的设计应该是循环利用的。
2 注意cpu利用率很低的那个点,明显jvm那时在卡顿做FuulGC去了,但是从老年代来看一直增长直到把老年代占满,FuulGC也没有回收掉任何对象。
于是我怀疑我的舱壁写的有问题了,也很好验证,打印下它的size()就知道了

嗯,我给他们配置的限制是5W,结果上百万了,看来并没有按照我们预想的情况限制住,Netty这种高并发情况下出现这种结果肯定是要往并发和线程安全方向去思考原由了。
分析泄漏原因:
查了几篇文章,对我启发最大的是https://www.cnblogs.com/softidea/p/5488012.html和https://stackoverflow.com/questions/1391918/does-java-have-a-linkedconcurrenthashmap-data-structure这两篇,原因在与LinkedHashMap的get方法中的afterNodeAccess方法:
public V get(Object key) {
Node e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
void afterNodeAccess(Node e) { // move node to last
LinkedHashMap.Entry last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry p =
(LinkedHashMap.Entry)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
} 每次get后其实它内部还要对map的顺序进行一次重排,在高并发下就排的稀乱了。
解决思路很简单,给get和put方法加锁,我也正好使用了ForwardingMap对它进行了封装,对上层是无感知的。但是我总觉得应该有更优雅的解决方式,幻想有一个“LinkedConcurrentHashMap”东西,像ConcurrentHashMap那样分段加锁,就可以提高高并发时的执行效率,最终从Guava中找到了Cache这个神器。
优化版:
改造后代码如下:
/**
* 舱壁模式线程安全的缓存
* @param
* @param
*/
public class IsolateHashCache extends ForwardingCache {
private Cache isolateCache;//用LinkedHashMap实现
public IsolateHashCache(int cap, int init, int concurrency){
super();
this.isolateCache = CacheBuilder.newBuilder()
.concurrencyLevel(concurrency)
.initialCapacity(init)
.maximumSize(cap)
.build();
}
@Override
protected Cache delegate() {
return isolateCache;
}
} 性能表现:
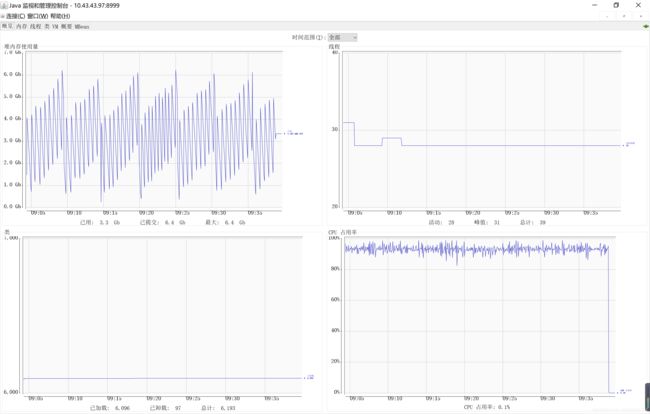
为了不放过一丁点的泄漏,连续压48小时,JVM内存管理仍然稳定并规律。问题解决。
总结:
Guava这个包还是需要好好去研究研究的,不得不说Google对集合高并发这一块设计的真心不错,我这里只是用了冰山一角(LocalCache)的冰山一角(靠它内置的回收机制),它还有大量的未开发的应用场景。