Windows下使用Eclipse配置Nutch2图文详解
当前对Nutch在eclipse下的配置文章其实已经有很多了,但是大都和官网一样,配置信息不全,版本不一致。。。因此本文针对当前Nutch最新的版本Nutch 2做一个详细的配置说明。如有遗漏欢迎吐槽。
首先,还是先重温下Nutch是干什么的吧。详见Nutch wiki。本文不加赘述。
- 准备工作:
1. Eclipse安装
本文采用的是Eclipse Juno (4.2) SR1 Packages,下载地址: http://www.eclipse.org/downloads/。
1.1 为Eclipse安装Subclipse插件,用来check out Nutch源码。下载地址: http://subclipse.tigris.org/
1.2 为Eclipse安装IvyDE插件,用来管理项目依赖jar包。 下载地址: http://www.apache.org/dist/ant/ivyde/updatesite.
2. Nutch2.1
2.1 下载地址: http://www.apache.org/dyn/closer.cgi/nutch/。
2.2 解压即可。
3. Cygwin
3.1 下载地址: http://cygwin.com/setup.exe
3.2 设置Cygwin的环境变量,右击"我的电脑" - 属性 - 高级 - 环境变量 - 在系统变量中选择PATH变量,编辑PATH变量,在PATH后面添加C:\cygwin\bin (对应自己Cygwin安装目录的bin文件路径)
- 配置步骤:
1.插件install
Eclipse Juno中安装Subclipse或IvyDE插件的步骤可以参考我的另一篇博客http://blog.csdn.net/ameliawmp/article/details/7859855
2. 使用Subclipse SVN插件Check out Nutch代码。
在Eclipse中打开SVN视图, 菜单项选择Windows - Open Perspective - Other ...点击"SVN资料库研究",在弹出的视图中右击 - 新建 - 资源库位置,在弹出的对话框中加入Nutch的URL:http://svn.apache.org/repos/asf/nutch/trunk/ , 点击"Finish"。
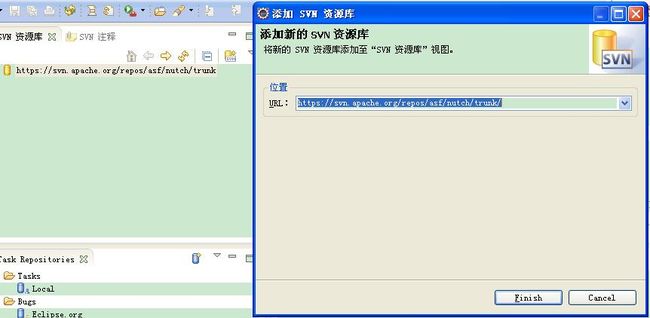
右击URL& check out。
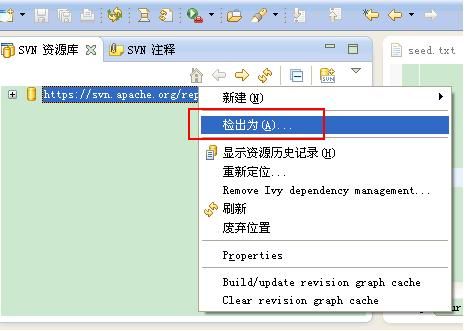
按照图示红框标记步骤Check Out Nutch项目。

在弹出的dialog中选择Java - Java Project - next, 将Check out的工程暂时命名为Nutch2.1 -点击"Next" - 点击"Finish"。
3. 完成Nutch check out。
4. 在Eclipse中配置Nutch。
4.1 切换到Java视图后,右击Nuch2.1工程文件,选择Properties - Java Build Path。
4.2 选择Java Build Path - Source选项卡,选择已有的Nutch2.1/src文件夹,将其Remove掉, 然后点击"Add Folder" - 展开Nutch2.1/src文件夹,分别选中src/bin, src/test, src/java, src/testresources, src/plugin/src/java, src/plugin/src/test(需要一个一个选择)。
4.3 选择Java Build Path - Libraries选项卡,单击"Add Class Folder" - 选择Nutch2.1/Conf文件夹 - 单击“OK”。
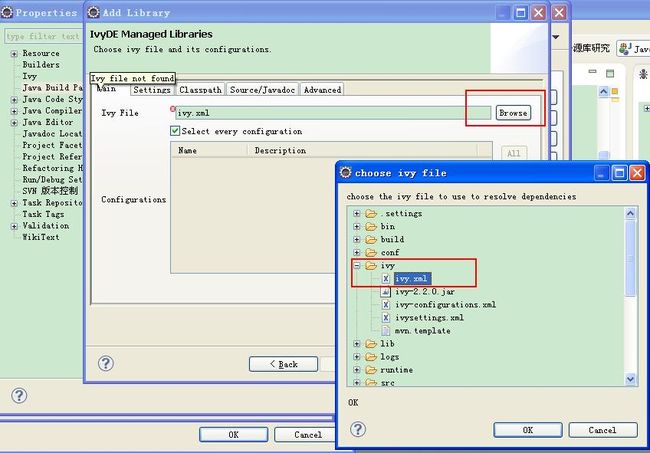
4.4 单击"Add Library" - 选择IvyDE Managed Dependencies - Next - Browse, 在Nutch2.1/Ivy文件夹中选择ivy.xml:
同时选中Configuration中的所有configuration选项。点击"Finish" - 点击“OK”。
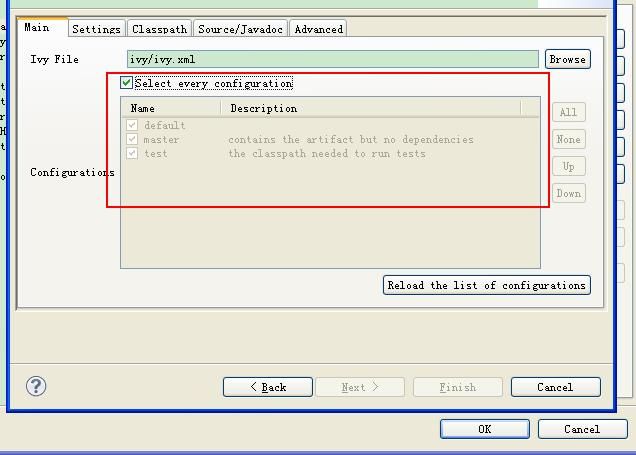
4.5 选择Java Build Path - Order and Export选项卡,选中"Nutch2.1/conf"文件夹,单击"top",将其置顶。这样做的原因是,使用Eclipse能够从该工程的Conf文件夹中获取Nutch配置信息。而不是从其它的地方获取。
4.6 点击"Finish"
此时的Nutch2.1工程会通过Ivy获取需要的Jar包,但是Nutch2.1包中新添加了部分插件,因此除了使用Ivy找到工程需要依赖的jar包以外,我们还需要通过手动的方式,往lib文件夹中添加缺少的jar包,缺少jar包list: 并将如下jar包加入到Java Build Path的Libraries中。

4.7 使用Ant编译Nutch2.1工程。
至此,Nutch2.1工程将不会有缺包问题。打开Ant视图: Windows - Sow Views - Ant, 在Ant面板中右击"Add buildfiles" - 选择Nutch2.1下的build.xml, 在Ant面板中双击该文件,对Nutch2.1进行编译。

4.8 运行Nutch2.1。
右击“Nutch2.1”工程 - 右击"Run As" - new Java Application - Browser选择刚创建的工程Nutch2.1,选择Main函数为org.apache.nutch.crawl.Crawl,如下图所示,
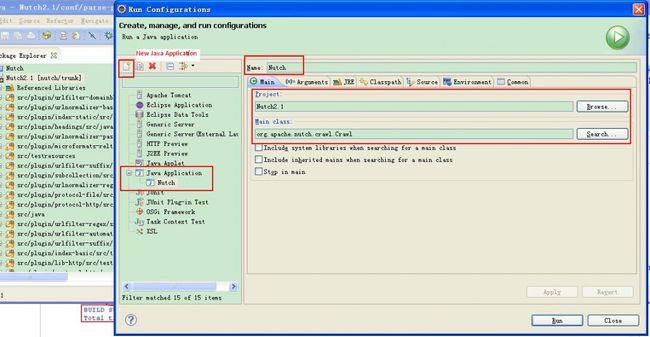
选择Arguments选项卡 - Program arguments中添加"urls - dir crawl -depth 3 -topN 5"。在VM parameters中添加"-Dhadoop.log.dir=logs -Dhadoop.log.file=hadoop.log",Don't forget在Nutch2.1工程目录下创建urls文件夹,并在文件夹中添加seed.txt。seed.txt中当然就是存放你需要crawl的网页的地址啦,
e.g. http://nutch.apache.org。
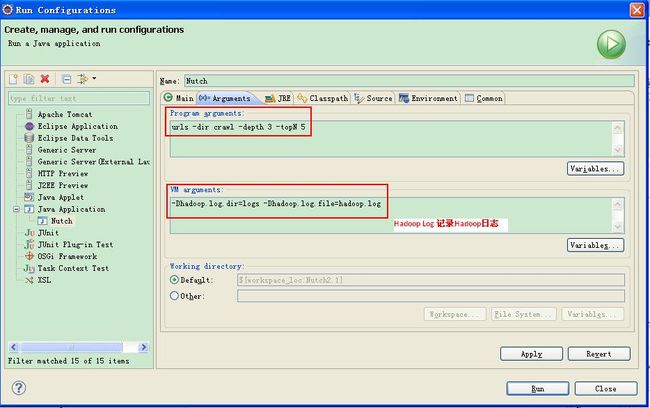
点击"Apply" - 点击"Run"。
至此,Nutch在Eclipse中的配置就差不多了。
但是,要使Nutch在Eclipse中正常运行我们还需要对工程、配置文件做些调整。详见补充&完善部分。
- 补充&完善:
1. Hadoop错误解决
由于操作系统是Windows,而Nutch是在Linux平台上开发,在文件结构,文件存储方式等等等等方面Windows 和Linux是截然不同的,因此在按照官方教程配置后,运行Nutch2.1会出现如下所示的hadoop错误,具体的bug信息:
Exceptionin thread "main"java.io.IOException:Failed to set permissions of path:\tmp\hadoop-test\mapred\staging\test2083949620\.staging to 0700
at org.apache.hadoop.fs.FileUtil.checkReturnValue(FileUtil.java:689)
at org.apache.hadoop.fs.FileUtil.setPermission(FileUtil.java:662)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:509)
at org.apache.hadoop.fs.RawLocalFileSystem.mkdirs(RawLocalFileSystem.java:344)
at org.apache.hadoop.fs.FilterFileSystem.mkdirs(FilterFileSystem.java:189)
at org.apache.hadoop.mapreduce.JobSubmissionFiles.getStagingDir(JobSubmissionFiles.java:116)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:918)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:912)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:396)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1136)
at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:912)
at org.apache.hadoop.mapred.JobClient.submitJob(JobClient.java:886)
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:1323)
at org.apache.nutch.crawl.Injector.inject(Injector.java:281)
at org.apache.nutch.crawl.Crawl.run(Crawl.java:127)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:65)
at org.apache.nutch.crawl.Crawl.main(Crawl.java:55)Nutch2.1中采用的Hadoop是1.1.1版本,经过反复测试发现hadoop1.0.2以上的版本在Windows下跑MapReduce程序都会出现上述问题。 错误产生原因本文不赘述,具体的解决方案就是替换Hadoop的版本(更多推荐j见[email protected])。我采用的是Hadoop1.0.2,实施过程:
(1) 打开ivy.xml。编辑hadoop-core 以及hadoop-test的版本号为1.0.2,如下所示,
(2) 保存ivy.xml,重新按照上述步骤在Java Build Path中点击"Add Library" 选择"ivy managed dependencies"。
(3)按照上述步骤重新使用Ant编译Nutch2.1 (值得注意的地方就是,配置文件修改之后,需要对整个工程编译一次,否则会出现配置文件不正确或是找不到等情况)。
2. Nutch配置文件问题
【问题一】
【解决方案】打开 Nutch2.1/conf/nutch-site.xml . 在nutch-site.xml中添加" http.agent.name" 信息。12:06:19,909 ERROR fetcher.Fetcher - Fetcher: No agents listed in 'http.agent.name' property.
http.agent.name
My Nutch Spider
【问题二】
Exception in thread "main" java.lang.IllegalArgumentException: plugin.folders is not defined
at org.apache.nutch.plugin.PluginManifestParser.parsePluginFolder(PluginManifestParser.java:78)
at org.apache.nutch.plugin.PluginRepository.(PluginRepository.java:71)
at org.apache.nutch.plugin.PluginRepository.get(PluginRepository.java:95)
at org.apache.nutch.searcher.QueryFilters.(QueryFilters.java:57)
at org.apache.nutch.searcher.IndexSearcher.init(IndexSearcher.java:79)
at org.apache.nutch.searcher.IndexSearcher.(IndexSearcher.java:63)
at org.apache.nutch.searcher.NutchBean.init(NutchBean.java:138)
at org.apache.nutch.searcher.NutchBean.(NutchBean.java:104)
at org.apache.nutch.searcher.NutchBean.(NutchBean.java:82)
at SearchApp.main(SearchApp.java:23) 【解决方案】修改plugin.folder的路径为当前工程的plugin所在路径。打开 Nutch2.1/conf/nutch-default.xml ,找到 plugin.folders ,将其改成为如下代码所示:
plugin.folders
./src/plugin
Directories where nutch plugins are located. Each
element may be a relative or absolute path. If absolute, it is used as is. If relative, it is searched for on the
classpath.
修改完成后,记得保存&重新编译工程。
3. Parse网页问题
【问题一】
12:37:45,832 WARN parse.ParseUtil - Error parsing http://nutch.apache.org/ with org.apache.nutch.parse.html.HtmlParser@1d8d39f
java.util.concurrent.ExecutionException: java.lang.NoClassDefFoundError: org/cyberneko/html/LostText
at java.util.concurrent.FutureTask$Sync.innerGet(FutureTask.java:232)
at java.util.concurrent.FutureTask.get(FutureTask.java:91)
at org.apache.nutch.parse.ParseUtil.runParser(ParseUtil.java:162)
at org.apache.nutch.parse.ParseUtil.parse(ParseUtil.java:93)
at org.apache.nutch.parse.ParseSegment.map(ParseSegment.java:97)
at org.apache.nutch.parse.ParseSegment.map(ParseSegment.java:1)
at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:50)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:436)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:372)
at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:212)
Caused by: java.lang.NoClassDefFoundError: org/cyberneko/html/LostText
at org.cyberneko.html.HTMLTagBalancer.(HTMLTagBalancer.java:259)
at org.cyberneko.html.HTMLConfiguration.(HTMLConfiguration.java:173)
at org.cyberneko.html.parsers.DOMFragmentParser.(DOMFragmentParser.java:129)
at org.apache.nutch.parse.html.HtmlParser.parseNeko(HtmlParser.java:229)
at org.apache.nutch.parse.html.HtmlParser.parse(HtmlParser.java:212)
at org.apache.nutch.parse.html.HtmlParser.getParse(HtmlParser.java:147)
at org.apache.nutch.parse.ParseCallable.call(ParseCallable.java:35)
at org.apache.nutch.parse.ParseCallable.call(ParseCallable.java:1)
at java.util.concurrent.FutureTask$Sync.innerRun(FutureTask.java:303)
at java.util.concurrent.FutureTask.run(FutureTask.java:138)
at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:886)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:908)
at java.lang.Thread.run(Thread.java:619)
Caused by: java.lang.ClassNotFoundException: org.cyberneko.html.LostText
at java.net.URLClassLoader$1.run(URLClassLoader.java:202)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:190)
at java.lang.ClassLoader.loadClass(ClassLoader.java:307)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:301)
at java.lang.ClassLoader.loadClass(ClassLoader.java:248)
... 13 more 【解决方案】修改parse网页的默认插件,打开 Nutch2.1/conf/parse-plugin.xml ,将" mimiType name" 为" text/htm l" 和" application/xhtml+xml" 的 plugin id 由 "parse-html" 改为 "parse-*tika*"
上述问题解决后,再次运行Nutch2.1,console显示crawl信息:
13:46:40,439 INFO crawl.LinkDb - LinkDb: finished at 13:46:40, elapsed: 00:00:10
13:46:40,439 INFO crawl.Crawl - crawl finished: crawl运行成功。Done!!!
- 参考:
1. Nutch wiki:http://wiki.apache.org/nutch/FrontPage
2. Nutch in Eclipse教程:http://wiki.apache.org/nutch/RunNutchInEclipse
3. Nutch mail list:http://nutch.apache.org/mailing_lists.html。加入Nutch的邮件用户列表——遇到问题就发email,解决问题绝佳地方。