十行代码将Redis缓存数据进行分页提取与展示
预览
准备数据
从以前的项目中提取一些数据直接导入MySQL,原先数据库为sqlite3,先将数据转为xls文件格式。

然后使用MySQL可视化工具Navicat for MySQL新建一个数据库,新建一张表,表数据格式与xls格式一致,然后选择导入向导。
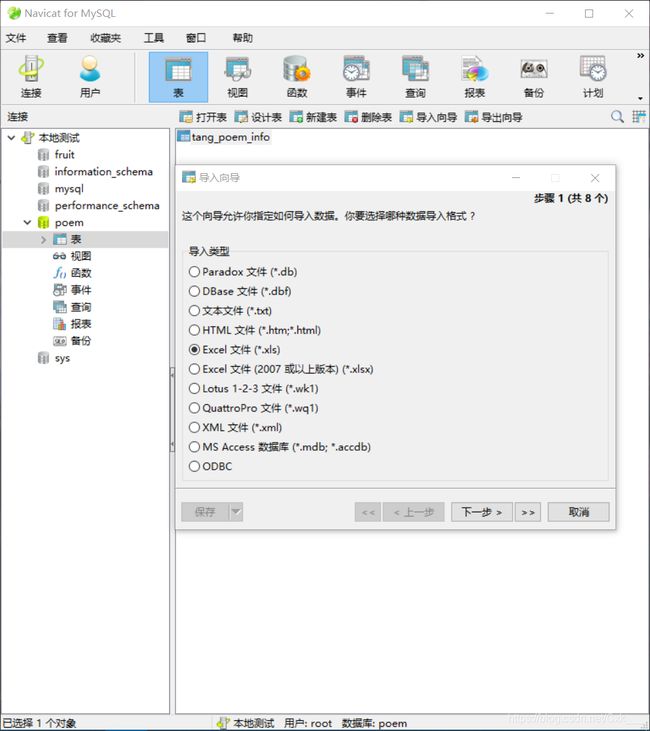
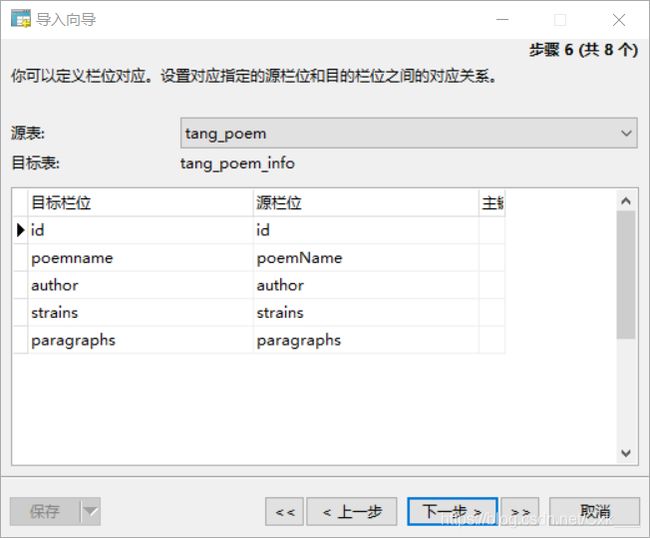
至此数据导入完成,开始尝试将MySQL数据加入Redis缓存。
Redis操作
先开启Redis服务
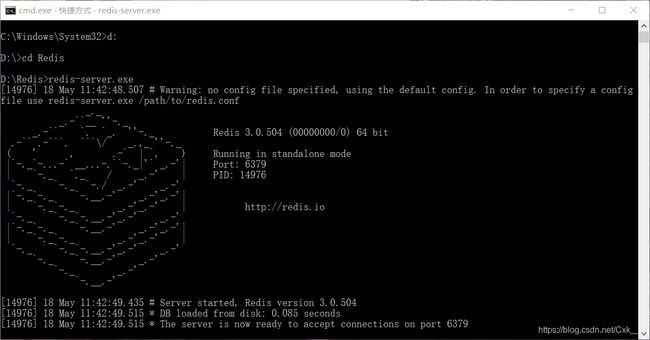
Redis包含五大数据格式,基本能完成大部分所需,本地配置也不需要怎么配置,直接下载安装就可运行。
import redis,time
#redis连接
pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True)
r = redis.Redis(connection_pool=pool)
# String 字符串
# data=find_data()[::-1]
# for i in range(len(data)):
# r.set("dict:chushou:%s"%str(i), str(data[i])) # key是"food" value是"mutton" 将键值对存入redis缓存
# print(str(i)+"ok")
# import ast
# 将字符串转为字典
# 将数据长度放入缓存
# r.set("dict:length",len(data))
# print(r.get("dict:length"))
# for i in range(int(r.get("dict:length"))):
# a=r.get("dict:chushou:%s"%str(i))
# a=ast.literal_eval(a)
# print(a['fruitname'])
# break
# r.set("visit:12306:totals", 1)
# print(r.get("visit:12306:totals"))
# for i in range(0,10):
# # 自增
# r.incr("visit:12306:totals")
# print(r.get("visit:12306:totals"))
# time.sleep(2)
# print(r.get('food'))
# '''
# 参数:
# set(name, value, ex=None, px=None, nx=False, xx=False)
# ex,过期时间(秒)
# px,过期时间(毫秒)
# nx,如果设置为True,则只有name不存在时,当前set操作才执行,同setnx(name, value)
# xx,如果设置为True,则只有name存在时,当前set操作才执行
# '''
#hash 哈希
# r.hset("hash1", "k1", "v1")
# r.hset("hash1", "k2", "v2")
# print(r.hkeys("hash1")) # 取hash中所有的key
# print(r.hget("hash1", "k1")) # 单个取hash的key对应的值
# print(r.hmget("hash1", "k1", "k2")) # 多个取hash的key对应的值
# r.hsetnx("hash1", "k2", "v3") # 只能新建
# print(r.hget("hash1", "k2"))
# list 列表
# def fenye(start,end):
# print(r.lrange('list:chushou',start,end))
# # data=find_data()[::-1]
# # for i in range(len(data)):
# # r.lpush("list:chushou",str(data[i]))
# # r.expire("list:chushou", 2);#设置过期时间为2秒
# # fenye(0,3)
# # time.sleep(3)
# # fenye(0,3)
# print(r.llen("list:chushou")) # 列表长度
# fenye(0,1)
# fenye(6,11)
# r.rpush("list2", 11, 22, 33) # 表示从右向左操作
# print(r.llen("list2")) # 列表长度
# print(r.lrange("list2", 0, -1)) # 切片取出值,范围是索引号0-3
# Blpop 命令移出并获取列表的第一个元素 左移除 右移除 brpop
# print(r.blpop("list2"))
# set 集合
# r.sadd("set1", 33, 44, 55, 66) # 往集合中添加元素
# print(r.scard("set1")) # 集合的长度是4
# print(list(r.smembers("set1"))) # 获取集合中所有的成员
#sortset
# Set操作,Set集合就是不允许重复的列表,本身是无序的。
# 有序集合,在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较,
# 所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
# r.zadd("zset1", n1=11, n2=22)
# r.zadd("zset2", 'm1', 22, 'm2', 44)
# print(r.zcard("zset1")) # 集合长度
# print(r.zcard("zset2")) # 集合长度
# print(r.zrange("zset1", 0, -1)) # 获取有序集合中所有元素
# print(r.zrange("zset2", 0, -1, withscores=True)) # 获取有序集合中所有元素和分数
因为Redis自带的list有个很好的分页函数,lrange(‘list:chushou’,start,end),第一个参数是数据的key,第二个是数据开始,第三个参数是数据结尾。比如我们就可以定义以下格式进行分页提取:
#page是第几页
#page_num是每页几个数据
#然后这里end我减去一个元素,因为Redis默认是右包括的,意思是(0,10)就是十一个数据,那么下一页数据(10,20),也包含了10的数据,返回的数据就重复了第10的数据,所以我们把最后一个数据去掉,变成(0,9),(10,19)。
start=page*page_num-page_num
end=page*page_num-1
然后我们这边定义数据缓存时间为120秒,也就是2分钟,2分钟后数据清除,如果不设置的话,长期下来数据缓存将会是一个很大的数量,当然Redis好像可以配置自动清除数据,当缓存达到上限时。
r.expire("list:chushou", 120);#设置过期时间为120秒
MySQL提取数据
这里没什么好说的,pymysql连接数据库执行sql查找全部数据并返回。
import pymysql
#数据库配置
DB_CONFIG = {
'host': '127.0.0.1',
'port': 3306,
'user': 'root',
'password': '123cxk...',
'db': 'poem',
'charset': 'utf8',
'cursorclass': pymysql.cursors.DictCursor
}
#查询
def find_data():
#连接数据库
db = pymysql.connect(**DB_CONFIG)
#使用cursor()方法创建一个游标对象
cursor = db.cursor()
sql = "SELECT * FROM tang_poem_info"
#使用execute()方法执行SQL语句
cursor.execute(sql)
#使用fetall()获取全部数据
res = cursor.fetchall()
cursor.close()
db.close()
return res
总体代码
连接数据库提取数据加入Redis缓存
import pymysql
#数据库配置
DB_CONFIG = {
'host': '127.0.0.1',
'port': 3306,
'user': 'root',
'password': '123cxk...',
'db': 'poem',
'charset': 'utf8',
'cursorclass': pymysql.cursors.DictCursor
}
#查询
def find_data():
#连接数据库
db = pymysql.connect(**DB_CONFIG)
#使用cursor()方法创建一个游标对象
cursor = db.cursor()
sql = "SELECT * FROM tang_poem_info"
#使用execute()方法执行SQL语句
cursor.execute(sql)
#使用fetall()获取全部数据
res = cursor.fetchall()
cursor.close()
db.close()
return res
import redis,ast
pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True)
r = redis.Redis(connection_pool=pool)
# list 列表
def fenye(page,page_num):
poems=[]
#包含,后面结尾我们少一条数据
start=page*page_num-page_num
end=page*page_num-1
for i in r.lrange('list:tang_poem',start,end):
#因为Redis加入list默认是字符串格式,我们对提取的数据进行转字典处理
a=ast.literal_eval(i)
poems.append(a)
#返回数据列表,缓存数据大小
return poems,r.llen("list:tang_poem")
def write_Redis():
data=find_data()[::-1]
# print(len(data)) #23909
for i in range(0,len(data)):
r.lpush("list:tang_poem",str(data[i]))
r.expire("list:tang_poem", 120);#设置过期时间为120秒
查看数据

flask
from flask import Flask, render_template
app = Flask(__name__)
@app.route('/')
def index():
page=1
page_num=10
poems=fenye(page,page_num)[0]
#检查缓存是否为空,如果为空,从数据库写入Redis
if poems==[]:
write_Redis()
poems = fenye(page, page_num)[0]
poems_len=int(fenye(page,page_num)[1]/10)
context={
'poems':poems
}
return render_template('fenye.html',**context,poems_len=poems_len,page=page)
@app.route('//' )
def page(page):
page=page
page_num=10
poems=fenye(page,page_num)[0]
poems_len=int(fenye(page,page_num)[1]/10)
context={
'poems':poems
}
return render_template('fenye.html',**context,poems_len=poems_len,page=page)
if __name__ == '__main__':
app.run(debug=True)
HTML
fenye.html
<html lang="en">
<head>
<meta charset="UTF-8">
<title>唐诗大全title>
head>
<body>
<table align="center" border="1" cellspacing="0">
<thead align="center">
<tr>
<th>序号th>
<th>诗名th>
<th>作者th>
<th>声调th>
<th>诗句th>
tr>
thead>
<tbody align="center">
{% for poem in poems %}
<tr>
<td>{{ poem.id }}td>
<td>{{ poem.poemname }}td>
<td>{{ poem.author }}td>
<td>{{ poem.strains }}td>
<td>{{ poem.paragraphs }}td>
tr>
{% endfor %}
tbody>
table>
<p align="center">
<input type="button" value="上一页" onclick='location.href=("/{{page-1}}/")'/>
{{page}}/{{poems_len}}页
<input type="button" value="下一页" onclick='location.href=("/{{page+1}}/")'/>
p>
body>
html>