姓名:车文扬 学号:16020199006
转载至:https://baijiahao.baidu.com/s?id=1593022777941849057&wfr=spider&for=pc,有删节
【嵌牛导读】:机器学习上10种方法
【嵌牛鼻子】:机器学习
【嵌牛提问】:机器学习未来的趋势?
【嵌牛正文】:
1. 线性回归
线性回归可能是统计和机器学习领域最广为人知的算法之一。
以牺牲可解释性为代价,预测建模的首要目标是减小模型误差或将预测精度做到最佳。我们从统计等不同领域借鉴了多种算法,来达到这个目标。
线性回归通过找到一组特定的权值,称为系数 B。通过最能符合输入变量 x 到输出变量 y 关系的等式所代表的线表达出来。
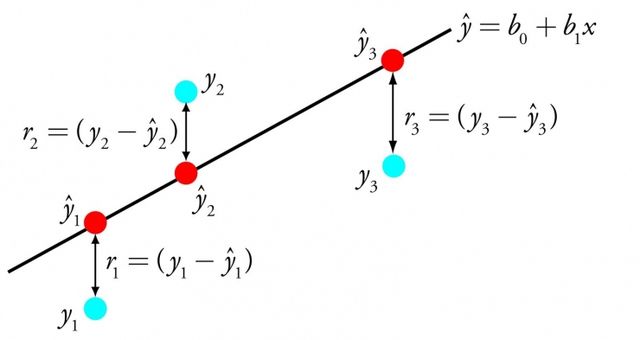
线性回归
例如:y = B0 + B1 * x 。我们针对给出的输入 x 来预测 y。线性回归学习算法的目标是找到 B0 和 B1 的值。
不同的技巧可以用于线性回归模型。比如线性代数的普通最小二乘法,以及梯度下降优化算法。线性回归已经有超过 200 年的历史,已经被广泛地研究。根据经验,这种算法可以很好地消除相似的数据,以及去除数据中的噪声。它是快速且简便的首选算法。
2. 逻辑回归
逻辑回归是另一种从统计领域借鉴而来的机器学习算法。
与线性回归相同。它的目的是找出每个输入变量的对应参数值。不同的是,预测输出所用的变换是一个被称作 logistic 函数的非线性函数。
logistic 函数像一个大 S。它将所有值转换为 0 到 1 之间的数。这很有用,我们可以根据一些规则将 logistic 函数的输出转换为 0 或 1(比如,当小于 0.5 时则为 1)。然后以此进行分类。
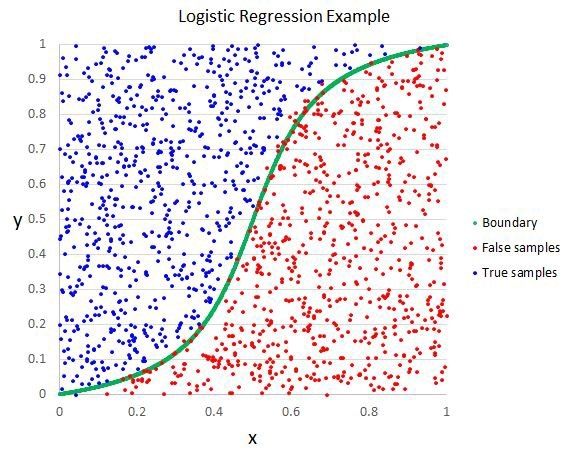
逻辑回归
正是因为模型学习的这种方式,逻辑回归做出的预测可以被当做输入为 0 和 1 两个分类数据的概率值。这在一些需要给出预测合理性的问题中非常有用。
就像线性回归,在需要移除与输出变量无关的特征以及相似特征方面,逻辑回归可以表现得很好。在处理二分类问题上,它是一个快速高效的模型。
3. 线性判别分析
逻辑回归是一个二分类问题的传统分类算法。如果需要进行更多的分类,线性判别分析算法(LDA)是一个更好的线性分类方法。
对 LDA 的解释非常直接。它包括针对每一个类的输入数据的统计特性。对于单一输入变量来说包括:
类内样本均值总体样本变量
线性判别分析
通过计算每个类的判别值,并根据最大值来进行预测。这种方法假设数据服从高斯分布(钟形曲线)。所以它可以较好地提前去除离群值。它是针对分类模型预测问题的一种简单有效的方法。
4. 分类与回归树分析
决策树是机器学习预测建模的一类重要算法。
可以用二叉树来解释决策树模型。这是根据算法和数据结构建立的二叉树,这并不难理解。每个节点代表一个输入变量以及变量的分叉点(假设是数值变量)
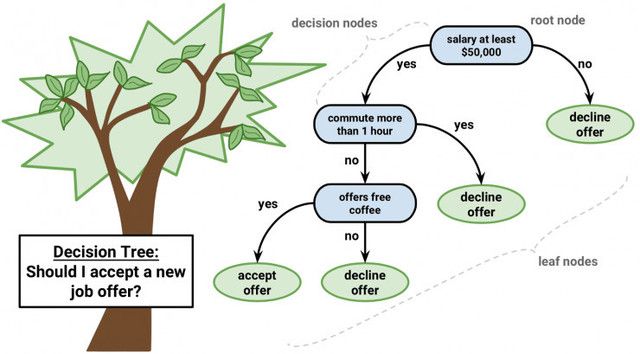
决策树
树的叶节点包括用于预测的输出变量 y。通过树的各分支到达叶节点,并输出对应叶节点的分类值。
树可以进行快速的学习和预测。通常并不需要对数据做特殊的处理,就可以使用这个方法对多种问题得到准确的结果。
5. 朴素贝叶斯
朴素贝叶斯(Naive Bayes)是一个简单,但是异常强大的预测建模算法。
这个模型包括两种概率。它们可以通过训练数据直接计算得到:1)每个类的概率;2)给定 x 值情况下每个类的条件概率。根据贝叶斯定理,一旦完成计算,就可以使用概率模型针对新的数据进行预测。当你的数据为实数时,通常假设服从高斯分布(钟形曲线)。这样你可以很容易地预测这些概率。
贝叶斯定理
之所以被称作朴素贝叶斯,是因为我们假设每个输入变量都是独立的。这是一个强假设,在真实数据中几乎是不可能的。但对于很多复杂问题,这种方法非常有效。
6. K 最近邻算法
K 最近邻算法(KNN)是一个非常简单有效的算法。KNN 的模型表示就是整个训练数据集。很简单吧?
对于新数据点的预测则是,寻找整个训练集中 K 个最相似的样本(邻居),并把这些样本的输出变量进行总结。对于回归问题可能意味着平均输出变量。对于分类问题则可能意味着类值的众数(最常出现的那个值)。
诀窍是如何在数据样本中找出相似性。最简单的方法就是,如果你的特征都是以相同的尺度(比如说都是英寸)度量的,你就可以直接计算它们互相之间的欧式距离。
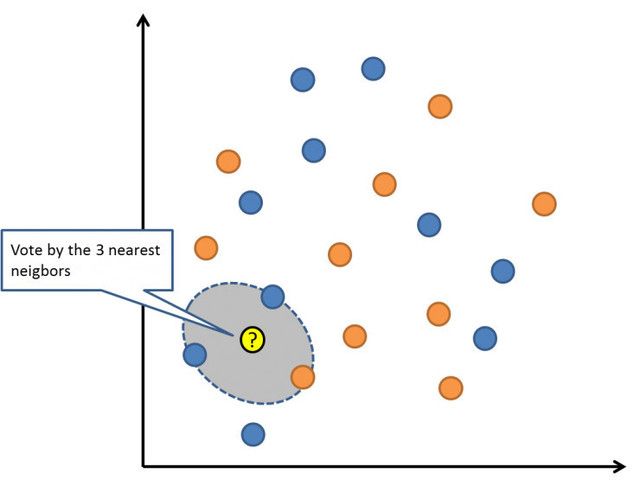
K 最近邻算法
KNN 需要大量空间来存储所有的数据。但只是在需要进行预测的时候才开始计算(学习)。你可以随时更新并组织训练样本以保证预测的准确性。
在维数很高(很多输入变量)的情况下,这种通过距离或相近程度进行判断的方法可能失败。这会对算法的性能产生负面的影响。这被称作维度灾难。我建议你只有当输入变量与输出预测变量最具有关联性的时候使用这种算法。
7. 学习矢量量化
K 最近邻算法的缺点是你需要存储所有训练数据集。而学习矢量量化(缩写为 LVQ)是一个人工神经网络算法。它允许你选择需要保留的训练样本个数,并且学习这些样本看起来应该具有何种模式。
学习矢量量化
LVQ 可以表示为一组码本向量的集合。在开始的时候进行随机选择。通过多轮学习算法的迭代,最后得到与训练数据集最相配的结果。通过学习,码本向量可以像 K 最近邻算法那样进行预测。通过计算新数据样本与码本向量之间的距离找到最相似的邻居(最符合码本向量)。将最佳的分类值(或回归问题中的实数值)返回作为预测值。如果你将数据调整到相同的尺度,比如 0 和 1,则可以得到最好的结果。
如果你发现对于你的数据集,KNN 有较好的效果,可以尝试一下 LVQ 来减少存储整个数据集对存储空间的依赖。
8. 支持向量机
支持向量机(SVM)可能是最常用并且最常被谈到的机器学习算法。
超平面是一条划分输入变量空间的线。在 SVM 中,选择一个超平面,它能最好地将输入变量空间划分为不同的类,要么是 0,要么是 1。在 2 维情况下,可以将它看做一根线,并假设所有输入点都被这根线完全分开。SVM 通过学习算法,找到最能完成类划分的超平面的一组参数。
支持向量机
超平面和最接近的数据点的距离看做一个差值。最好的超平面可以把所有数据划分为两个类,并且这个差值最大。只有这些点与超平面的定义和分类器的构造有关。这些点被称作支持向量。是它们定义了超平面。在实际使用中,优化算法被用于找到一组参数值使差值达到最大。
SVM 可能是一种最为强大的分类器,它值得你一试。
9. Bagging 和随机森林
随机森林是一个常用并且最为强大的机器学习算法。它是一种集成机器学习算法,称作自举汇聚或 bagging。
bootstrap 是一种强大的统计方法,用于数据样本的估算。比如均值。你从数据中采集很多样本,计算均值,然后将所有均值再求平均。最终得到一个真实均值的较好的估计值。
在 bagging 中用了相似的方法。但是通常用决策树来代替对整个统计模型的估计。从训练集中采集多个样本,针对每个样本构造模型。当你需要对新的数据进行预测,每个模型做一次预测,然后把预测值做平均得到真实输出的较好的预测值。
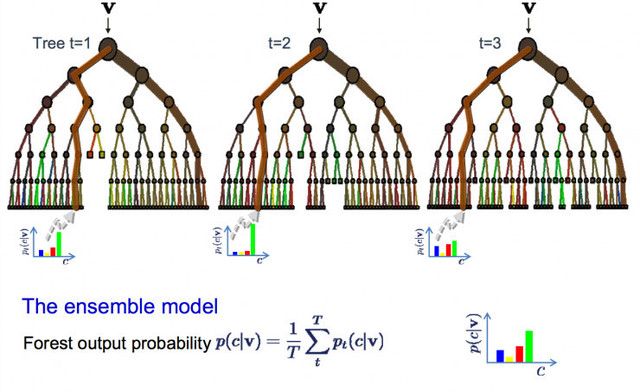
随机森林
这里的不同在于在什么地方创建树,与决策树选择最优分叉点不同,随机森林通过加入随机性从而产生次优的分叉点。
每个数据样本所创建的模型与其他的都不相同。但在唯一性和不同性方面仍然准确。结合这些预测结果可以更好地得到真实的输出估计值。
如果在高方差的算法(比如决策树)中得到较好的结果,你通常也可以通过袋装这种算法得到更好的结果。
10. Boosting 和 AdaBoost
Boosting 是一种集成方法,通过多种弱分类器创建一种强分类器。它首先通过训练数据建立一个模型,然后再建立第二个模型来修正前一个模型的误差。在完成对训练集完美预测之前,模型和模型的最大数量都会不断添加。
AdaBoost 是第一种成功的针对二分类的 boosting 算法。它是理解 boosting 的最好的起点。现代的 boosting 方法是建立在 AdaBoost 之上。多数都是随机梯度 boosting 机器。
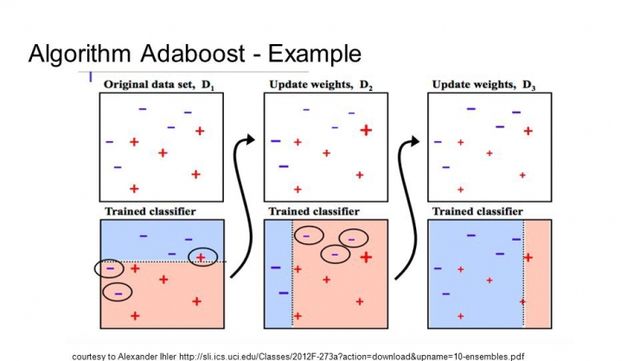
AdaBoost
AdaBoost 与短决策树一起使用。当第一棵树创建之后,每个训练样本的树的性能将用于决定,针对这个训练样本下一棵树将给与多少关注。难于预测的训练数据给予较大的权值,反之容易预测的样本给予较小的权值。模型按顺序被建立,每个训练样本权值的更新都会影响下一棵树的学习效果。完成决策树的建立之后,进行对新数据的预测,训练数据的精确性决定了每棵树的性能。
因为重点关注修正算法的错误,所以移除数据中的离群值非常重要。