JPEG解码原理
1.背景介绍
问题定义:为什么要做视频图像的编解码?
我们先来看看,视频资源占用计算:4KP30视频1min,3840218033060* = 42.7GB(每帧大小24.3MB),1分钟4K的视频大概需要42.7GB存储,因此视频图像的编解码十分必要。
我们再看看图像的存储格式和常用分辨率:
模拟信号PAL、NTSC制式已经远去,我们来看数字信号(YUV、RGB888),由于人眼对亮度信号比色度信号更敏感,因此出现了YUV(planar/semi planar)降采样格式:YUV420、YUV422、YUV444
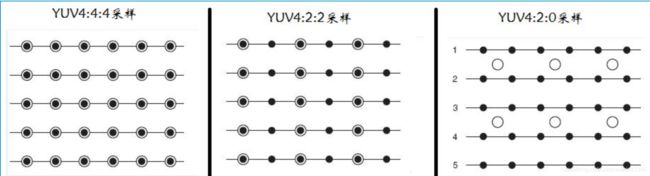
图1 降采样格式,实心点为Y分量,空心圆圈为cb、cr分量
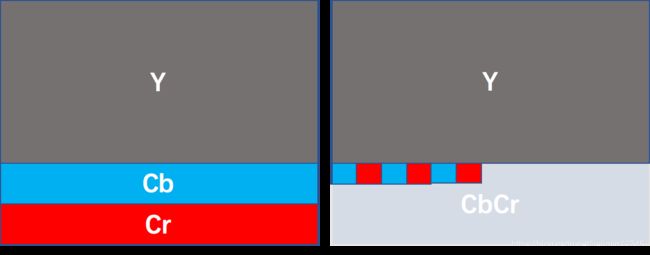
图2 平面格式与交错格式内存存储
2.编解码方法
参考经典数字图像处理教材,常见的编解码方法主要做以下三方面工作:
- 时间/空间冗余,利用时间空间相关性消除
- 编码冗余,通过变长编码(直方图越大的值,分配较小的比特)
- 不相关信息,忽略人眼不敏感的信息
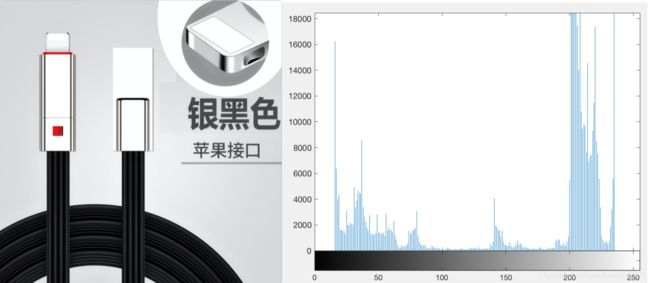
如下图,这张图有大量的平坦区域(空间冗余),并且灰度集中在几个区间(编码冗余)
基本上述分析,如何来从上述三个方面来压缩图像呢?基于两个先验:
人眼对亮度分量的敏感度高于色度分量,轻微的色度变化对视觉体验影响很小
人眼对低频分量的敏感度高于高频分量,轻微的高频变化对视觉体验影响很小
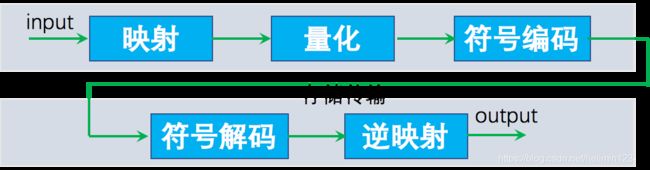
常见的编解码流程如下:
3.JPEG编解码
目前有较多的图像编码标准,如jpeg、bmp、gif、png、webp、heif,我们这里先说jpeg部分,这个编解码标准诞生于20世纪90年代,JPEG标准仅仅说明定义了codec部分,也就是图片如何压缩为字节流以及重新解码为图片的过程,标准没有涉及到文件的存储格式。
1992年颁布了JPEG File Interchange Format(JFIF),目前在互联网上用的最多的jpeg格式,接着又出现了EXIF格式,主要用于数码产品,记录了媒体的时间地点信息。
JPEG文件由一系列字段组成,每个字段都有marker(标记),由0xff开头。
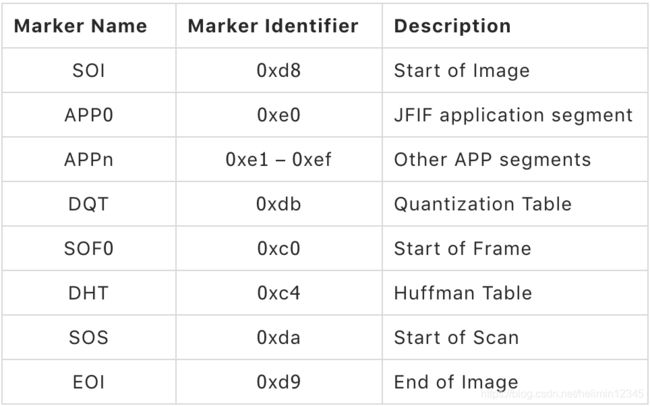
(1)SOF marker(Start of Frame),这个字段定义了文件的起始
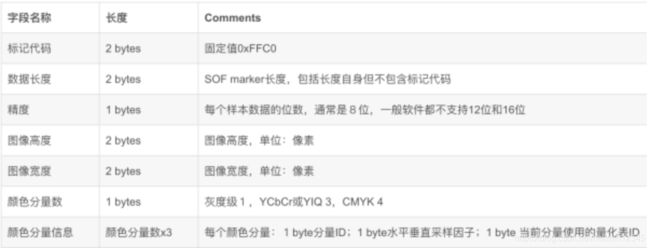
(2)APP0(Application-specific),这个字段定义了JFIF格式
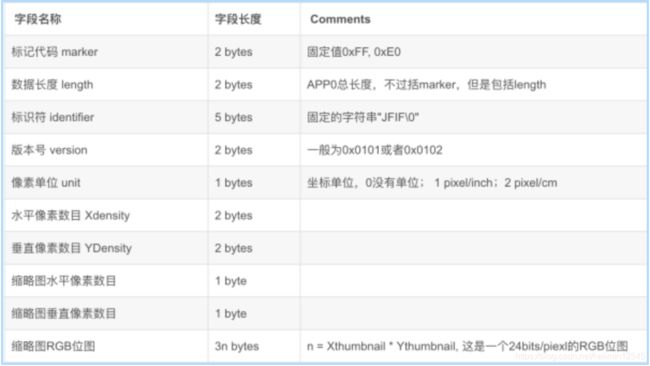
(3)APPn(Application-specific),定义了其它格式,如APP1表示exif格式
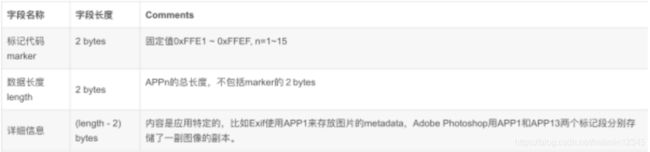
(4)DQT(Define Quantization Table(s)),定义了量化表

下面以jpeg图的二进制数据来分析,通过vim打开后(:%!xxd切换到十六进制),ffd8表示start of image,ffe0表示app0,即是JFIF格式,0043前面的ffdb表示量化表(两个ffdb分别表示亮度和色度分量的量化表),0043表示量化表65字节(64byte量化参数 + 1 byte精度及量化表ID),ffc0表示start of frame,即图像数据。
3.jpeg编解码流程
jpeg编码流程如下:

(1)块划分
将输入数据按8x8划分数据块,源图像如果不是8x8的整数倍,需进行补充

(2)DCT变换
减去128再进行DCT,DCT可接受的范围是[-128,127)
DCT变换,得到64个基底系数,(0,0)位置是直流系数,是64个源数据的均值
DCT在复杂度和失真上是最好的trade-off
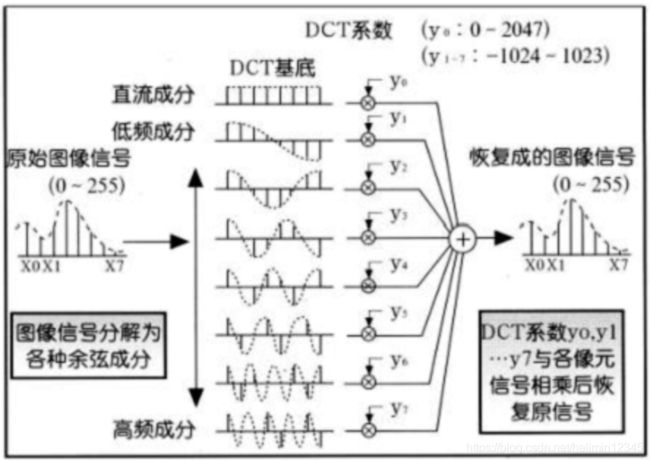
我们暂时先只考虑水平方向上一行数据(8个像素)的情况时的DCT变换,从而来说明其物理意义。如下图所示:
原始的图像信号(最左边的波形)经过DCT变换之后变成了8个波,其中第一个波为直流成分,其余7个为交流成分。由于大多数图像的高频分量比较小,相应的图像高频分量的DCT系数经常接近于0,再加上高频分量中只包含了图像的细微的细节变化信息,而人眼对这种高频成分的失真不太敏感,所以,可以考虑将这一些高频成分予以抛弃,从而降低需要传输的数据量。这样一来,传送DCT变换系数的所需要的编码长度要远远小于传送图像像素的编码长度。到达接收端之后通过反离散余弦变换就可以得到原来的数据,虽然这么做存在一定的失真,但人眼是可接受的,而且对这种微小的变换是不敏感的。
(3)量化
对亮度和色度分量的DCT系数进行量化,使用如下标准量化表,该量化表是从广泛的实验中得出的。当然,也可以自定义量化表
//标准亮度分量量化表
static const unsigned int std_luminance_quant_tbl[DCTSIZE2] = {
16, 11, 10, 16, 24, 40, 51, 61,
12, 12, 14, 19, 26, 58, 60, 55,
14, 13, 16, 24, 40, 57, 69, 56,
14, 17, 22, 29, 51, 87, 80, 62,
18, 22, 37, 56, 68, 109, 103, 77,
24, 35, 55, 64, 81, 104, 113, 92,
49, 64, 78, 87, 103, 121, 120, 101,
72, 92, 95, 98, 112, 100, 103, 99
};
//标准色度分量量化表
static const unsigned int std_chrominance_quant_tbl[DCTSIZE2] = {
17, 18, 24, 47, 99, 99, 99, 99,
18, 21, 26, 66, 99, 99, 99, 99,
24, 26, 56, 99, 99, 99, 99, 99,
47, 66, 99, 99, 99, 99, 99, 99,
99, 99, 99, 99, 99, 99, 99, 99,
99, 99, 99, 99, 99, 99, 99, 99,
99, 99, 99, 99, 99, 99, 99, 99,
99, 99, 99, 99, 99, 99, 99, 99
};
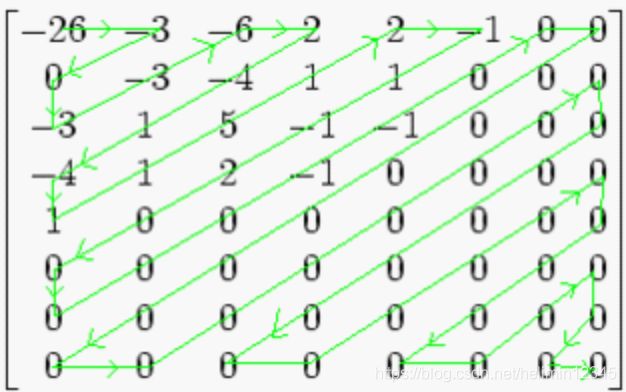
量化表搞掉了很多高频量,对DCT变换进行量化后得到量化结果,会出现大量的0,使用Z形扫描,可以将大量的0连到一起,减小编码后的大小。越偏离左上方,表示频率越高,这里其实是通过量化,将图像的高频信息干掉了。
(4)DC和AC分量编码
DC进行DPCM编码,AC进行RLC编码,这两种编码都有中间格式,进一步减小存储量,原理可自行wiki
(5)熵编码
在得到DC系数的中间格式和AC系数的中间格式之后,为进一步压缩图像数据,有必要对两者进行熵编码,通过对出现概率较高的字符采用较小的bit数编码达到压缩的目的。JPEG标准具体规定了两种熵编码方式:Huffman编码和算术编码。JPEG基本系统规定采用Huffman编码。
Huffman编码:对出现概率大的字符分配字符长度较短的二进制编码,对出现概率小的字符分配字符长度较长的二进制编码,从而使得字符的平均编码长度最短。Huffman编码的原理请参考数据结构中的Huffman树或者最优二叉树。
Huffman编码时DC系数与AC系数分别采用不同的Huffman编码表,对于亮度和色度也采用不同的Huffman编码表。因此,需要4张Huffman编码表才能完成熵编码的工作。具体的Huffman编码采用查表的方式来高效地完成。然而,在JPEG标准中没有定义缺省的Huffman表,用户可以根据实际应用自由选择,也可以使用JPEG标准推荐的Huffman表。或者预先定义一个通用的Huffman表,也可以针对一副特定的图像,在压缩编码前通过搜集其统计特征来计算Huffman表的值。
下一篇再来讲jpeg编解码库libjpeg turbo的使用。
5.参考
[1] https://en.wikipedia.org/wiki/JPEG
[2] https://blog.csdn.net/carson2005/article/details/7753499