windows环境下YOLOV4源码训练自己的数据集
YOLOV4源码对自己的数据训练,除了数据集,其他主要核心修改文件是.data .names .cfg三个文件,对应源码里面的coco.data,coco.names,yolov4.cfg。最后再加一个预训练权重yolov4.conv.137,这些准备好,就可以开始训练了。
为了方便训练和管理,后续将所有的文件放在our_data文件夹。如下图


1 数据集准备
我采取的是VOC数据集的格式。主要以Annotations,ImageSets,JPEGImages三个文件为主。为了方便,将train和valid数据集同同时处理。如图

Annotations,ImageSets,labels,train处理训练数据集。
Annotations_valid,ImageSets_valid,labels,valid处理验证数据集。
Annotations和Annotations_valid里面分别存放train和valid对应的xml文件,ImageSets和ImageSets_valid文件下面都再建一个Main文件夹。

数据集使用labelImg进行标注。将训练图片放入train文件夹,,将验证图片放入valid文件夹。
接下来处理数据集
import xml.etree.ElementTree as ET
import os
classes = ['broken_gate', "scratch_lobes", 'dry_joint',"flinders"] # 这里是你的所有分类的名称
myRoot = r'F:\YOLOV4\C++\darknet\PL_data' # 这里是你项目的根目录
train_xmlRoot = myRoot + r'/Annotations'
train_txtRoot = myRoot + r'/labels'
train_imageRoot = myRoot + r'/train'
valid_xmlRoot = myRoot + r'/Annotations_valid'
valid_txtRoot = myRoot + r'/labels_valid'
valid_imageRoot = myRoot + r'/valid'
def getFile_name(file_dir):
L = []
for root, dirs, files in os.walk(file_dir):
print(files)
for file in files:
if os.path.splitext(file)[1] == '.bmp':
L.append(os.path.splitext(file)[0]) # L.append(os.path.join(root, file))
return L
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(xmlRoot,txtRoot,image_id):
in_file = open(xmlRoot + '\\%s.xml' % (image_id),encoding='utf-8')
out_file = open(txtRoot + '\\%s.txt' % (image_id), 'w',encoding='utf-8') # 生成txt格式文件
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
# image_ids_train = open('D:/darknet-master/scripts/VOCdevkit/voc/list.txt').read().strip().split('\',\'') # list格式只有000000 000001
image_ids_train = getFile_name(train_imageRoot)
# image_ids_val = open('/home/*****/darknet/scripts/VOCdevkit/voc/list').read().strip().split()
image_ids_val = getFile_name(valid_imageRoot)
list_file_train = open(myRoot + r'\ImageSets\Main\train.txt', 'w')
# list_file_val = open('boat_val.txt', 'w')
for image_id in image_ids_train:
list_file_train.write(train_imageRoot + '\\%s.bmp\n' % (image_id))
convert_annotation(train_xmlRoot,train_txtRoot,image_id)
list_file_train.close() # 只生成训练集,自己根据自己情况决定
list_file_val = open(myRoot + r'\ImageSets_valid\Main\valid.txt', 'w')
for image_id in image_ids_val:
list_file_val.write(valid_imageRoot + '\\%s.bmp\n' % (image_id))
convert_annotation(valid_xmlRoot,valid_txtRoot,image_id)
list_file_val.close()修改下面部分,更改跟自己的相关文件路径

将ImageSets和labels文件夹里面的所有txt拷入train文件夹,ImageSets_valid和labels_valid文件夹里面的所有txt拷入valid文件夹。

到此,数据已经准备OK。
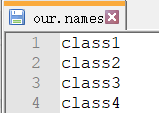
2 .names文件准备
.names保存检测类别名称。将源码里面cfg/coco.names文件,在our_data里面复制一份,更改为our.names。将内容改为我们自己的检测类别。为了举例,这个地方检测类别为4
3 .data文件准备
.data保存相关文件路径。将源码里面cfg/coco.data文件,在our_data里面复制一份,更改为our.data。将对应部分修改
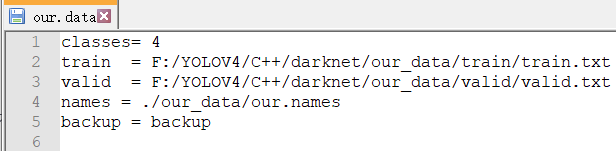
classes:需要检测的类型个数。
train:训练集里面的train.txt路径。(生成在ImageSets-Main)
valid:验证集里面的valid.txt路径。(生成在ImageSets_valid-Main)
names:EL.names的路径。
backup:模型最终保存位置路径。
4 .cfg文件准备
.cfg保存YOLOV4模型结构。将源码里面cfg/yolov4.cfg文件,在our_data里面复制一份,更改为yolov4_our.data。将对应部分修改。修改部分参考:https://blog.csdn.net/weixin_44868057/article/details/106528369。
batch不宜过大,过大显存会爆,导致不能训练
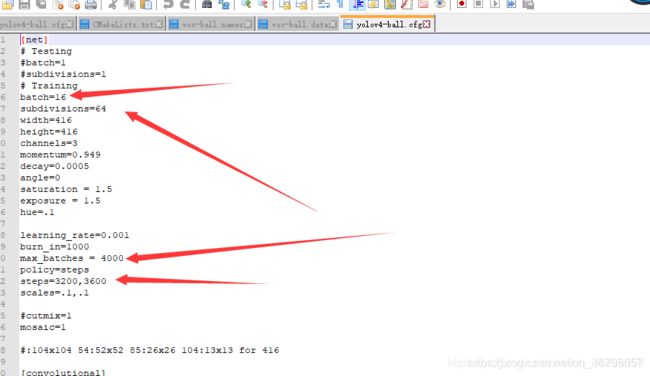
我们还需要改3个地方的classes(我用的是notepad++打开)搜索classes,然后classes前面都有对应的filters,这两个都要改,filters与classes的关系是filters = (classes +5) *3。我们的类别是4,应该设置为27。(这个地方偷懒了,参考了其他博主的图,读者需要注意,修改自己的classes和filters)

5 预训练权重准备
权重下载:链接:https://pan.baidu.com/s/1jFzvYybPYAQ6QCgMkbFBgA 。提取码:hmzw
需要yolov4.conv.137。
至此准备工作已经做完,接下来就是训练。、
6 训练
输入
darknet.exe detector train our_data/our.data our_data/yolov4_our.cfg our_data/yolov4.conv.137 -map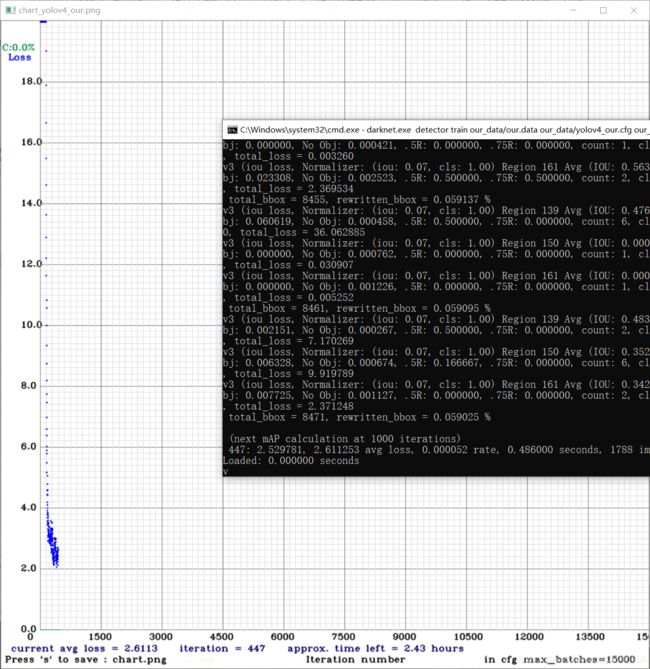
最后在backup文件里面,就有最终的权重。最后就可以选择yolov4_our_best.weights作为最终测试的权重选择。剩下两个,是最终保存的权重和可以接着训练的权重。

参考链接:
https://blog.csdn.net/weixin_44868057/article/details/106528369
https://www.pianshen.com/article/44301150823/