0×00 介绍
在互联网这个复杂的环境中,搜索引擎本身的爬虫,出于个人目的的爬虫,商业爬虫肆意横行,肆意掠夺网上的或者公共或者私人的资源。显然数据的收集并不是为所欲为,有一些协议或者原则还是需要每一个人注意。本文主要介绍关于爬虫的一些理论和约定协议,然后相对完整完成一个爬虫的基本功能。
注:想学习Python的小伙伴们
可以
进群:984632579
领取从0到1完整学习资料 视频 源码 精品书籍 一个月经典笔记和99道练习题及答案
0×01 协议
一般情况下网站的根目录下存在着一个robots.txt的文件,用于告诉爬虫那些文件夹或者哪些文件是网站的拥有者或者管理员不希望被搜索引擎和爬虫浏览的,或者是不希望被非人类的东西查看的。但是不仅仅如此,在这个文件中,有时候还会指明sitemap的位置,爬虫可以直接寻找sitemap而不用费力去爬取网站,制作自己的sitemap。那么最好我们看个具体的例子吧,这样更有助于理解robots协议:
-----------------------以下时freebuf的robots.txt-------------User-agent: *Disallow:/*?*
Disallow: /trackback
Disallow: /wp-*/Disallow:*/comment-page-*Disallow:/*?replytocom=*
Disallow: */trackbackDisallow:/?randomDisallow:*/feedDisallow:/*.css$
Disallow: /*.js$
Sitemap: http://www.freebuf.com/sitemap.txt
大家可以看到,这里指明了适用的User-agent头,指明了Disallow的目录,也指明了sitemap,然后我们在看一下sitemap中是什么:

我们大致可以发现这些都是整个网站允许公开的内容,如果这个爬虫作者是对freebuf的文章感兴趣的话,大可不必从头到尾设计爬虫算法拿下整个网站的sitemap,这样直接浏览sitemap节省了大量的时间。
0×02 原则
如果协议不存在的话,我们仍然不能为所欲为,上网随意搜索一下源于爬虫协议的官司,国内外都有。爬虫的协议规则建立在如下的基础上:
1. 搜索技术应该服务于人类,尊重信息提供者的意愿,并维护其隐私权;
2. 网站也有义务保护其使用者的个人信息和隐私不被侵犯。
简单来说,就是构建的爬虫以信息收集为目的是没错的,但是不能侵犯别人的隐私,比如你扫描并且进入了网站的robots中的disallow字段,你就可能涉及侵犯别人隐私的问题。当然作为一般人来讲,我们使用爬虫技术无非是学习,或者是搜集想要的信息,并没有想那么多的侵权,或者是商业的问题。
0×03 确立目标与分析过程
这里我提供一个爬虫诞生要经历的一般过程:
1. 确立需求在,sitemap中挑选出需要挖掘的页面;
2. 依次分析挑选出的页面;
3. 存储分析结果。
但是有时候问题就是,我们的目标网站没有提供sitemap,那么这就得麻烦我们自己去获取自己定制的sitemap。
目标:制作一个网站的sitemap:
分析:我们要完成这个过程,但是不存在现成sitemap,笔者建议大家把这个网站想象成一个图的结构,网站的url之间纵横交错,我们可以通过主页面进行深度优先或者广度优先搜索从而遍历整个网站拿到sitemap。显然我们发现,我们首先要做的第一步就是完整的获取整个页面的url。
但是我们首先得想清楚一个问题:我们获取到的url是应该是要限制域名的,如果爬虫从目标网站跳走了,也就意味着将无限陷入整个网络进行挖掘。这么庞大的数据量,我想不是一般人的电脑硬盘可以承受的吧!
那么我们的第一步就是编写代码去获取整个页面的url。其实这个例子在上一篇文章中已经讲到过。
0×04 动手
我们的第一个小目标就是获取当前页面所有的url:
首先必须说明的是,这个脚本并不具有普遍性(只针对freebuf.com),并且效率低下,可以优化的地方很多:只是为了方便,简单实现了功能,有兴趣的朋友可以任意重构达到高效优雅的目的
importurllibfrombs4importBeautifulSoupimportredefget_all_url(url):urls = [] web = urllib.urlopen(url)soup =BeautifulSoup(web.read())#通过正则过滤合理的url(针对与freebuf.com来讲)tags_a =soup.findAll(name='a',attrs={'href':re.compile("^https?://")})try:fortag_aintags_a: urls.append(tag_a['href'])#return urlsexcept:passreturnurls#得到所有freebuf.com下的urldefget_local_urls(url):local_urls = [] urls = get_all_url(url)for_urlinurls: ret = _urlif'freebuf.com'inret.replace('//','').split('/')[0]: local_urls.append(_url)returnlocal_urls#得到所有的不是freebuf.com域名的urldefget_remote_urls(url):remote_urls = [] urls = get_all_url(url)for_urlinurls: ret = _urlif"freebuf.com"notinret.replace('//','').split('/')[0]: remote_urls.append(_url)returnremote_urlsdef__main__():url ='http://freebuf.com/'rurls = get_remote_urls(url)print"--------------------remote urls-----------------------"forretinrurls:printretprint"---------------------localurls-----------------------"lurls = get_local_urls(url)forretinlurls:printretif__name__ =='__main__':__main__()
这样我们就得到了该页面的url,本域名和其他域名下:


当然图中所示的结果为部分截图,至少证明了我们上面的代码比较好的解决的url获取的问题,由于这里我们的判断规则简单,还有很多情况没有考虑到,所以建议大家如果有时间,可以把上面代码重构成更佳普适,更加完整的脚本,再投入真正的实际使用。
0×05 sitemap爬虫
所谓的sitemap,我们在上面的例子中又讲到sitemap记录了整个网站的网站拥有者允许你爬取内容的链接。但是很多情况下,sitemap没有写出,那么问题就来了,我们面对一个陌生的网站如何进行爬取(在不存在sitemap的情况下).
当然我们首先要获取sitemap,没有现成的我们就自己动手获取整个网站的sitemap。
再开始之前我们需要整理一下思路:我们可以把整站当成一个错综复杂的图结构,有一些算法基础的读者都会知道图的简单遍历方法:dfs和bfs(深度优先和广度优先)。如果这里读者有问题的话建议先去学习一下这两种算法。大体的算法结构我们清楚了,但是在实现中我们显然需要特殊处理url,需要可以区分当前目标站点域名下的网站和其他域名的网站,除此之外,在href的值中经常会出现相对url,这里也要特别处理。
importurllibfrombs4importBeautifulSoupimporturlparseimporttimeimporturllib2 url ="http://xxxx.xx/"domain ="xxxx.xx"deep =0tmp =""sites = set()visited = set()#local = set()defget_local_pages(url,domain):globaldeepglobalsitesglobaltmp repeat_time =0pages = set()#防止url读取卡住whileTrue:try:print"Ready to Open the web!"time.sleep(1)print"Opening the web", url web = urllib2.urlopen(url=url,timeout=3)print"Success to Open the web"breakexcept:print"Open Url Failed !!! Repeat"time.sleep(1) repeat_time = repeat_time+1ifrepeat_time ==5:returnprint"Readint the web ..."soup = BeautifulSoup(web.read())print"..."tags = soup.findAll(name='a')fortagintags:#避免参数传递异常try: ret = tag['href']except:print"Maybe not the attr : href"continueo = urlparse.urlparse(ret)"""
#Debug I/O
for _ret in o:
if _ret == "":
pass
else:
print _ret
"""#处理相对路径urlifo[0]is""ando[1]is"":print"Fix Page: "+ret url_obj = urlparse.urlparse(web.geturl()) ret = url_obj[0] +"://"+ url_obj[1] + url_obj[2] + ret#保持url的干净ret = ret[:8] + ret[8:].replace('//','/') o = urlparse.urlparse(ret)#这里不是太完善,但是可以应付一般情况if'../'ino[2]: paths = o[2].split('/')fori inrange(len(paths)):ifpaths[i] =='..': paths[i] =''ifpaths[i-1]: paths[i-1] =''tmp_path =''forpathinpaths:ifpath =='':continuetmp_path = tmp_path +'/'+path ret =ret.replace(o[2],ret_path)print"FixedPage: "+ ret#协议处理if'http'notino[0]:print"Bad Page:"+ ret.encode('ascii')continue#url合理性检验ifo[0]is""ando[1]isnot"":print"Bad Page: "+retcontinue#域名检验ifdomainnotino[1]:print"Bad Page: "+retcontinue#整理,输出newpage = retifnewpagenotinsites:print"Add New Page: "+ newpage pages.add(newpage)returnpages#dfs算法遍历全站defdfs(pages):#无法获取新的url说明便利完成,即可结束dfsifpagesisset():returnglobalurlglobaldomainglobalsitesglobalvisited sites = set.union(sites,pages)forpageinpages:ifpagenotinvisited:print"Visiting",page visited.add(page) url = page pages = get_local_pages(url, domain) dfs(pages)print"sucess"pages = get_local_pages(url, domain)dfs(pages)foriinsites:printi
在这个脚本中,我们采用了dfs(深度优先算法),关于算法的问题我们不做深入讨论,实际上在完成过程中我们关键要完成的是对href的处理,在脚本代码中我们也可以看到,url的处理占了大部分代码,但是必须说明的是:很遗憾我们并没有把所有的情况都解决清楚,但是经过测试,上面的代码可以应付很多种情况。所以大家如果有需要可以随意修改使用。
测试:用上面的脚本在网络状况一般的情况下,对我的个人博客(大概100个页面)进行扫描,大概用时2分半,这是单机爬虫。
0×06 Web元素处理
在接下来的这个例子中,我们不再关注url的处理,我们暂且把目光对准web单个页面的信息处理。按照爬虫编写的一般流程,在本例子中,争取每一步都是完整的可操作的。
确立目标:获取freebuf的文章并且生成docx文档。
过程:侦察目标网页的结构,针对特定结构设计方案
脚本实现:bs4模块和docx模块的使用
预备知识:
1.Bs4的基本api的使用,关于beautifulSoup的基本使用方法,我这里需要介绍在下面的脚本中我使用到的方法:
Soup= BeautifulSoup(data)#构建一个解析器Tags= Soup.findAll(name,attr)
我们重点要讲findAll方法的两个参数:name和attr
Name: 指的是标签名,传入一个标签名的名称就可以返回所有固定名称的标签名
Attr: 是一个字典存储需要查找的标签参数,返回对应的标签
Tag.children表示获取tag标签的所有子标签Tag.string表示获取tag标签内的所有字符串,不用一层一层索引下去寻找字符串Tag.attrs[key]表示获取tag标签内参数的键值对键为key的值Tag.img表示获取tag标签的标签名为img的自标签(一个)
在本例子的使用中,笔者通过标签名+id+class来定位标签,虽然这样的方法不是绝对的正确,但是一般情况下,准确率还是比较高的。
2.docx的使用:在使用这个模块的时候,要记清楚如果:
pip install python-docx
easy_install python-docx
两种方式安装都不能正常使用的话,就需要下载tar包自己手动安装
Docx模块是一个可以直接操作生成docx文档的python模块,使用方法极尽简单:
Demo = Document() #在内存中建立一个doc文档
Demo.add_paragraph(data) #在doc文档中添加一个段落
Demo.add_picture(“pic.png”) #doc文档中添加一个图片
Demo.save(‘demo.docx’) #存储docx文档
当然这个模块还可以操作段落的字体啊格式啊各种强大的功能,大家可以从官方网站找到对应的文档。鉴于我们以学习为目的,我就不作深入的排版介绍了
开始:
观察html结构:
need-to-insert-img
我们大致观察一下结构,定位到文章的具体内容需要找到标签,然后再遍历标签的子标签即可遍历到所有的段落,配图资料
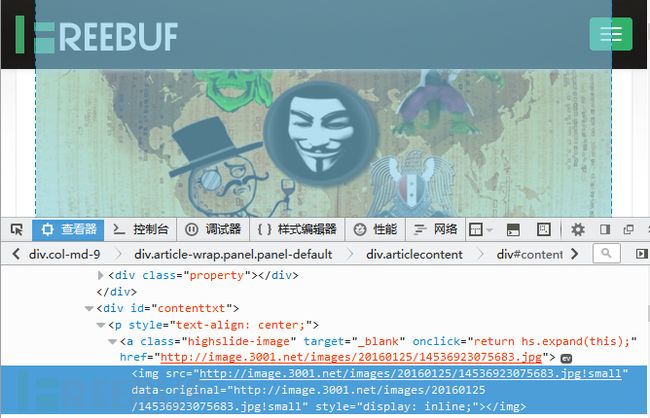
这样定位到图片,那么我们怎么样来寻找
代码
fromdocximportDocumentfrombs4importBeautifulSoupimporturllib url ="http://freebuf.com/news/94263.html"data = urllib.urlopen(url) document = Document() soup = BeautifulSoup(data)article = soup.find(name ="div",attrs={'id':'contenttxt'}).childrenforeinarticle:try:ife.img: pic_name =''printe.img.attrs['src']if'gif'ine.img.attrs['src']: pic_name ='temp.gif'elif'png'ine.img.attrs['src']: pic_name ='temp.png'elif'jpg'ine.img.attrs['src']: pic_name ='temp.jpg'else: pic_name ='temp.jpeg'urllib.urlretrieve(e.img.attrs['src'], filename=pic_name) document.add_picture(pic_name)except:passife.string:printe.string.encode('gbk','ignore') document.add_paragraph(e.string) document.save("freebuf_article.docx")print"success create a document"
当然上面的代码,读者看起来是非常粗糙的,其实没关系,我们的目的达到了,在使用中学习,这也是python的精神。可能大家不熟悉beautifulsoup的使用,这里需要大家自行去读一下beautifulsoup官方的doc,笔者不知道有没有中文版,但是读英文也不是那么麻烦,基本写的还是非常简明易懂。
那么我们可以看一下输出的结构吧!

这是文件夹目录下的文件,打开生成的docx文档以后:


这里我们发现排版仍然是有缺陷,但是所有的内容,图片都按照原来的顺序成功存储在了.docx文件中。