行人重识别02-03:fast-reid(BoT)-白话给你讲论文-翻译无死角
以下链接是个人关于fast-reid(BoT行人重识别) 所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:a944284742相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。
行人重识别02-00:fast-reid(BoT)-目录-史上最新无死角讲解
本 论 文 名 为 : B a g o f T r i c k s a n d A S t r o n g B a s e l i n e f o r D e e p P e r s o n R e − i d e n t i f i c a t i o n \color{red}{本论文名为: Bag of Tricks and A Strong Baseline for Deep Person Re-identification} 本论文名为:BagofTricksandAStrongBaselineforDeepPersonRe−identification
Abstract
该片论文主要探索了一个简单却有效的行人重识别基线。在近些年,由于深度学习的出现,让重识别达到一个很高的精度。但是目前精度最高的算法,都是通过设计复杂的网络结构,多个分支的特征进行连接,在论文中,对于训练的技巧都是简单给出。这篇论文将总结训练技巧对模型精度的影响,并且给出实验数据(在ReID中)。通过组合一些技巧,只使 global features 用模型在 Market1501 数据集上达到了 94.5% rank-1 与 85.9% mAP。我们的代码与模型发布在:https://github.com/michuanhaohao/reid-strong-baseline
1. Introduction
为了进行比较,我们调研了去年在 ECCV2018 以及 CVPR2018 顶会上发表的文章。展示如Figure 1:

图解:这里是在 Market1501 以及 DukeMTMC-reID 数据集展示的是不同的 baseline,是我们的模型和其他的模型对比的结果。
在 Market1501 数据集上,只有 两个 baselines 超过了 90% rank-1 的准确率,四个 baselines 低于 80%。在 DukeMTMC-reID 数据集,所有的 baseline 都没有超过 80% rank-1 准确率或者 65% mAP。我们认为一个强大的基线对于促进研究的发展非常重要,所以我们使用一个强大技巧改进了这些基线,并且我们的代码已经被开源。
此外,我们也发现有些作品与其他艺术方法进行比较是不公平的。详细的说,改进主要来自训练技巧而不是方法本身。但是这些技巧很低调的在论文中提到,所有读者忽略了他。这会使这种方法的有效性被夸大,我们建议审稿的时候,应该也把这些考虑在内。
除了上述原因,另外在工业方面,一般企业都更加喜欢简单有效的模型,而不是多个 local features 进行连接,或者分为多个阶段。为了追求较高的精度,学术界常常结合多个局部特征或利用姿态估计或分割模型中的语义信息。这样的方式,为算法带来了很多额外的消耗。大的特征也降低了检索的速度。因此我们希望使用一些技巧去改变行人重识别模型(只使用global
features),达到一个比较高的精度。论文总结如下:
1.我们调查了许多在顶级会议上发表的作品,发现其中大多数的扩展基线都很差。
2.对于学数界,我们提供了一个更加强大的 baseline,促进ReID的研究。
3.对于社区,们希望能给评论者一些参考,告诉他们哪些技巧会影响ReID模式的性能我们建 议,在比较不同方法的性能时,审阅人员需要考虑这些技巧
4.对于行业来说,我们希望提供一些有效的技巧来获得更好的机型而不需要太多的额外消耗。
幸运的是,在一些论文或开源项目中已经出现了许多有效的培训技巧。我们根据这些技巧,在多个数据集上对他们进行了评估。经过大量的实验,我们选择了 6 个技巧在这篇文章中进行介绍,其中包含了我们修改或者设计的。我们将这些技巧添加到一个广泛使用的基线中,以获得修改后的基线,在 Market1501 数据集达到了 94.5% rank-1以及 85.9% mAP。此外,我们发现不同的工作选择了不同的图片大小以及 batch 大小,作为补充,我们还探讨了它们对模型性能的影响。综上所述,本文的贡献如下:
1.针对于行人重识别,我们收集了一些训练技巧,我们设计了一个新的建构,叫做BNNeck,另外,我们在两个数据集上对这些技巧进行了评估。
2.我们提出了一个强大的 ReID baseline。其在 Market1501 数据集上达到了94.5% rank-1 与 85.9% mAP,其结果是通过 ResNet50 作为主干网络提取 g
lobal features 进行预测的,据我们所知,这是global features在ReID本人身上获得的最佳表现。
3.另外,我们评估了图像大小以及 batch size 对模型的影响。
2. Standard Baseline
我们遵循一个广泛使用的开源代码作为我们的标准基线,这些 baseline 都是使用 ResNet50 作为主干网络构建的,在训练阶段,这些方法包括了如下步骤:
1.使用 ResNet50(初始化权重来自于 ImageNet 的预训练模型),然后改变其全链接层为N。N 表示训练数据的 ID 数目。
2.我们随机采样 P 个身份ID,并且对每个ID采集 K 张,最后一个batch size B = P * K,在这篇论文中,我们设置P=16,K=4
3.我们改变每张图像的大小为 256 × 128,并且使用 0 值填充 10 个像素,然后使用随机剪切的方式,重新剪切 256 × 128 大小的图像。
4. 每张图像以 0.5 的概率值,随机进行水平反转。
5. 每幅图像都被解码为[0,1]中32位浮点原始像素值,然后我们通过减去0.485,0.456,0.406,再除以来对RGB通道进行归一化分别为0.229、0.224、0.225。
6.模型输出的ReID features f 进行预测 logits p。
7.ReID features f 被用于计算 triplet loss,logits p 用于计算交叉损失熵, triplet loss 的 margin m 设置为0.3
8.采用Adam方法对模型进行优化。初始学习率设为0.00035,在第40个epoch和第70个epoch分别降低0.1。总共有120个epoch
3. Training Tricks
这个章节主要介绍一些对ReID有影响的技巧,大多数这样的技巧可以在不改变模型架构的情况下扩展标准基线。The Fig. 2 展示了训练策略和本部分中出现的模型架构,如下 Fig. 2:

3.1. Warmup Learning Rate
学习率的衰策略对于 ReID 模型具有较大的影响,标准的基线都是使用一个比较大,不变的常数作为初始学习率。在[2]中,为了获得更好的性能,采用了一个预热策略来引导网络。在实践中,如下图Fig. 3所示:

我们用了10个epoch线性地将学习速率从 3.5 × 1 0 − 5 3.5×10^{-5} 3.5×10−5 增加到 3.5 × 1 0 − 4 3.5×10^{-4} 3.5×10−4, 然后在训练到 40th epoch 和 70th epoch 学习率分别衰减为 3.5 × 1 0 − 5 3.5×10^{-5} 3.5×10−5 以及 3.5 × 1 0 − 6 3.5×10^{-6} 3.5×10−6。学习率 l r ( t ) lr(t) lr(t) 在 epoch t t t 的计算如下:
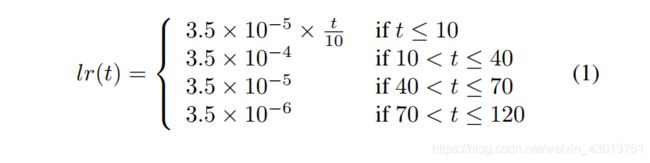
3.2. Random Erasing Augmentation
在ReID中,这些图片经常被一些物体遮挡。为了解决这个问题,同时改善模型的泛化能力。Zhong 等人,[27]提出了一种名为随机擦除(REA)的数据增强方式。在实验中,对于在 batch 中的一张图像 I I I,它发生随机擦除的概率是 p e p_e pe, 它保持不变的概率是 1 − p e 1 - p_e 1−pe。然后 REA 在图像 I I I z中随机选择一个矩形 I e I_e Ie(大小为 W e , H e W_e,H_e We,He),然后使用随机的一个值擦代替这些像素。假设图像 I I I 以及其内的区域 I e I_e Ie 面积分别为 S = W × H S=W \times H S=W×H , S e = W e × H e S_e=W_e \times H_e Se=We×He。使用 r e = S e S r_e=\frac{S_e}{S} re=SSe 表示擦除区域的占比。例外,矩形 I e I_e Ie 的边长是 r 1 r1 r1 到 r 2 r2 r2 之间的一个随机值。为了确定一个区域,REA 随机初始化一个 point p o i n t = ( x e , y e ) point=(x_e,y_e) point=(xe,ye)。如果 x e + W e < = W x_e+W_e <= W xe+We<=W 且 y e + H e < = H y_e+H_e <= H ye+He<=H,则选择这个区域。 否则,我们重复上述过程,直到一个适当的 I e I_e Ie 被选择。根据选定的擦除区域 I e I_e Ie,将 I e I_e Ie 中的每个像素赋值为图像 I I I 的平均值。
在实验中,我们设置超参数 p = 0.5 , 0.02 < S e < 0.4 , r 1 = 0.3 , r 2 = 3.33 p = 0.5, 0.02

3.3. Label Smoothing
ID Embedding (IDE) [25]网络是行人重识别的基本底线,IDE的最后一层,输出图像的ID的概率值。隐层神经元的大小和训练 ID 的数目一致。给一张图像, y y y表示图像的真实ID, p i p_i pi 表示通过预测类别 i i i 的 logit 值,交叉熵损失计算为下:
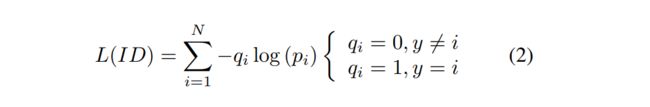
因为分类的类别是由person ID决定的,文将这种丢失函数称为ID loss。
但是person ReID可以看作是一次性的学习任务,因为测试集的person id还没有出现在训练集中。因此,防止ReID模型过度拟合训练id是非常重要的。在[17]中提出的标签平滑(LS)是一种广泛应用的防止分类任务过拟合的方法。它将气的结构改为:
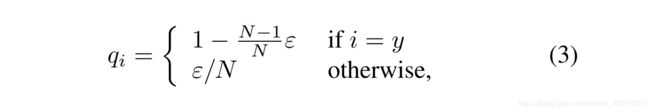
其中, ε ε ε 为一个小常数,以鼓励模型对训练集不太自信。在本研究中,将其设置为0.1。当训练集不是很大时,LS可以显著提高模型的性能。
3.4. Last Stride
较高的空间分辨率往往会丰富特征的粒度。在[16]中,Sun等人去除了骨网中最后一次空间下采样操作,增加了feature map的大小。为方便起见,我们将主干网中的最后一次空间下采样操作表示为最后一次步进。ResNet50的最后一步将是将ResNet50的主干输入到256×128大小的图像中,输出空间大小为的feature map 8×4。如果将last stride从2改为1,则可以得到空间尺寸更高的feature map(16×8)。
3.5. BNNeck
大部分作品将ID loss和triplet loss结合在一起来训练ReID模型。如下图5(a)所示,在标准基线中,ID丢失和三联体 loss 约束了同一 feature f,但这两种loss在 embedding 空间中的目标不一致:

如图6(a)所示,ID loss构造了几个超平面将嵌入空间分离为不同的子空间。每个类的特征分布在不同的子空间中。在这种情况下,余弦距离比欧氏距离更适合推理阶段的 ID loss 优化模型。另一方面,如下6(b)所示:

在欧几里得空间中,triplet loss 增强了类内紧性和类间可分性。由于 triplet loss 不能提供全局最优约束,类间距离有时小于类内距离。常用的方法是将ID损失和 triplet loss 结合起来对模型进行训练。这种方法让模型学习更多的区别特征。而对于嵌入空间中的图像对,ID loss 主要是优化余弦距离,而 triplet loss 主要是优化欧几里得距离。如果我们同时使用这两种损失,他们的目标可能是不一致的。在训练过程中,一种可能的现象是一种损失减少,而另一种损失振荡甚至增加。
为了克服上述问题,我们设计了一个名为BNNeck的结构,如图5(b)所示。BNNeck只在特性之后(在分类器FC层之前)添加了一个批处理标准化(BN)层。将BN层之前的特征记为 f t f_t ft,我们让 f t f_t ft通过一个BN层,得到归一化的特征 f i f_i fi¥。在训练阶段,分别使用 f t f_t ft 和 f i f_i fi 计算 triplet loss 和ID loss。归一化平衡了 f i f_i fi 的各个维度。这些特征在超球面附近呈高斯分布。这种分布使得ID损失更容易收敛。另外,BNNeck减少了ID loss 对 f t f_t ft 的约束,ID loss 的约束越小,使得 triplet loss 更容易同时收敛。第三,标准化保持了同一人特征的紧凑分布。
由于超球面对于坐标轴的原点几乎是对称的,BNNeck的另一个技巧是消除分类器FC层的偏差。它约束分类超平面通过坐标轴的原点。我们使用[4]中提出的 Kaiming 初始化方法来初始化FC层。
在推理阶段,我们选择 f i fi fi 去做重识别的任务。余弦距离度量比欧氏距离度量具有更好的性能。如下表1中的实验结果表明,BNNeck可以大幅度提高ReID模型的性能。

3.6. Center Loss
Triplet loss 的计算方式如下:
L T r i = [ d p − d n + α ] + L_{Tri} = [d_p - d_n + α]_+ LTri=[dp−dn+α]+
其中 d p d_p dp 和 d n d_n dn 为正对和负对的特征距离。最小值为3个点损失的边际, [ z ] + = m a x ( z , 0 ) [z]+ = max(z, 0) [z]+=max(z,0),本文将最小值设为0.3。但是,Triplet loss 只考虑 d p d_p dp 和 d n d_n dn 的差异,而忽略了它们的绝对值。例如,当 d p d_p dp = 0.3, d n d_n dn = 0.5时,三联体损失为0.1。另一种情况,当 d p d_p dp = 1.3, d n d_n dn = 1.5时,三重态损失也为0.1。三重损失由随机采样的两个人id确定。在整个训练数据集中很难保证 d p d_p dp < d n d_n dn。
Center loss [20]在学习每一类深度特征中心的同时,对深度特征与其对应的类中心之间的距离进行惩罚,弥补了 Triplet loss 的不足。Center loss 函数公式为:
L c = 1 2 ∑ j = 1 B ∣ ∣ f t j − c y i ∣ ∣ 2 2 ] L_c = \frac{1}{2} \sum^B_{j=1}||f_{t_j}-c_{y_i}||_2^2] Lc=21j=1∑B∣∣ftj−cyi∣∣22]
其中 y j y_j yj是一个小批中的第j个图像的标签。 c y j c_{y_j} cyj为深部特征yith类中心。 B B B是批量大小的数量。这个公式有效地描述了阶级内部的变化。最小化中心损失可增加级内紧凑性。我们的模型共包含以下三种损失:
L = L I D + L T r i p l e t + β L C L=L_{ID} + L_{Triplet} + βL_C L=LID+LTriplet+βLC
β β β是中心损失的平衡权重。在我们的实验中,参数设置为0.0005。
结语
剩下的是一些实验对比,我就不做翻译了,有兴趣的同志可以自己去好好看下实验结果