音视频&流媒体
- 音视频流媒体
- 流媒体背景
- 音视频常见术语定义规范
- 音视频组成
- 编码格式
- 音频编码格式
- 视频编码格式
- 存储封装格式
- 视频码率帧率分辨率
- 码率
- 帧率
- 分辨率
- 图像存储格式yuv
- 一幅彩色图像的基本要素是什么
- YUV与像素的关系
- YUV图像格式的内存大小
- 帧率码率与分辨率之间关系
- 一个视频文件的大小为586M播放时长为3分7秒
- 10min流量消耗41587KB
- 输出文件大小公式
- 一帧图像大小
- 音频采样率位数
- I帧P帧B帧IDR帧
- I帧帧内编码帧
- P帧前向预测编码帧
- B帧双向预测内插编码帧
- IDR 帧
- 小结
- GOP
- 编解码
- 硬编解码
- 软编解码
- 数据优化
- 流媒体传输协议
- RTPRTCP
- 小结
- RTMP
- HLS
- HTTP-FLV
- RTPRTCP
- CDN
- 弱网优化
- 丢帧
- 自适应码率
- 实时聊天的挑战
- 常见问题和解决方案
- TODO
音视频&流媒体
是什么促使我要写这一篇音视频入门文章?那是因为和一妹子打赌码率的概念,结果输了;对一个技术人员而言,码率这个种最基本的概率都没整明白,简直是奇耻大辱,开个玩笑。有了这个前提之后,发现,还是得多理解下原理和基础入门知识。
流媒体背景
当下,音视频、流媒体已经无处不在,直播已经火了几年,在后续的时间里面,人们聊天已经不仅仅满足与文字、而是更多的在于“类面对面”交流,能够实时感知对方的表情、动作。为此,有必要跟紧时代潮流,好好梳理梳理流媒体这门功课。
流媒体是什么?流媒体就是指采用流式传输技术在网络上连续实时播放的媒体格式,如音频、视频或多媒体文件。流媒体技术也称流式媒体技术。那么音视频就是流媒体的核心。
音视频常见术语定义规范
音视频组成
一个完整的视频文件,包括音频、视频和基础元信息,我们常见的视频文件如mp4、mov、flv、avi、rmvb等视频文件,就是一个容器的封装,里面包含了音频和视频两部分,并且都是通过一些特定的编码算法,进行编码压缩过后的。
H264、Xvid等就是视频编码格式,MP3、AAC等就是音频编码格式。例如:将一个Xvid视频编码文件和一个MP3音频编码文件按AVI封装标准封装以后,就得到一个AVI后缀的视频文件。
因此,视频转换需要设置的本质就是
- 设置需要的视频编码
- 设置需要的音频编码
- 选择需要的容器封装
一个完整的视频转换设置都至少包括了上面3个步骤。
编码格式
音频编码格式
音频编码格式有如下
- AAC
- AMR
- PCM
- ogg(ogg vorbis音频)
- AC3(DVD 专用音频编码)
- DTS(DVD 专用音频编码)
- APE(monkey’s 音频)
- AU(sun 格式)
- WMA
音频编码方案之间音质比较(AAC,MP3,WMA等)结果: AAC+ > MP3PRO > AAC> RealAudio > WMA > MP3
目前最常见的音频格式有 Mp3、AC-3、ACC,MP3最广泛的支持最多,AC-3是杜比公司的技术,ACC是MPEG-4中的音频标准,ACC是目前比较先进和具有优势的技术。对应入门,知道有这几种最常见的音频格式足以。
视频编码格式
视频编码标准有两大系统: MPEG 和ITU-T,国际上制定视频编解码技术的组织有两个,一个是“国际电联(ITU-T)”,它制定的标准有H.261、H.263、H.263+、H.264等,另一个是“国际标准化组织(ISO)”它制定的标准有MPEG-1、MPEG-2、MPEG-4等。
常见编码格式有:
- Xvid(MPEG4)
- H264 (目前最常用编码格式)
- H263
- MPEG1,MPEG2
- AC-1
- RM,RMVB
- H.265(目前用的不够多)
目前最常见的视频编码方式的大致性能排序基本是: MPEG-1/-2 < WMV/7/8 < RM/RMVB < Xvid/Divx < AVC/H.264(由低到高,可能不完全准确)。
在H.265出来之前,H264是压缩率最高的视频压缩格式,其优势有:
- 低码率(Low Bit Rate):和MPEG2和MPEG4 ASP等压缩技术相比,在同等图像质量下,采用H.264技术压缩后的数据量只有MPEG2的1/8,MPEG4的1/3。
- 高质量的图象 :H.264能提供连续、流畅的高质量图象(DVD质量)。
- 容错能力强 :H.264提供了解决在不稳定网络环境下容易发生的丢包等错误的必要工具。
- 网络适应性强 :H.264提供了网络抽象层(Network Abstraction Layer),使得H.264的文件能容易地在不同网络上传输(例如互联网,CDMA,GPRS,WCDMA,CDMA2000等)。
H.264最大的优势是具有很高的数据压缩比率,在同等图像质量的条件下,H.264的压缩比是MPEG-2的2倍以上,是MPEG-4的1.5~2倍。举个例子,原始文件的大小如果为88GB,采用MPEG-2压缩标准压缩后变成3.5GB,压缩比为25∶1,而采用H.264压缩标准压缩后变为879MB,从88GB到879MB,H.264的压缩比达到惊人的102∶1。低码率(Low Bit Rate)对H.264的高的压缩比起到了重要的作用,和MPEG-2和MPEG-4 ASP等压缩技术相比,H.264压缩技术将大大节省用户的下载时间和数据流量收费。尤其值得一提的是,H.264在具有高压缩比的同时还拥有高质量流畅的图像,正因为如此,经过H.264压缩的视频数据,在网络传输过程中所需要的带宽更少,也更加经济。
目前这些常见的视频编码格式实际上都属于有损压缩,包括H264和H265,也是有损编码,有损编码才能在质量得以保证的前提下得到更高的压缩率和更小体积
存储封装格式
目前市面常见的存储封装格式有如下:
- AVI (.avi)
- ASF(.asf)
- WMV (.wmv)
- QuickTime ( .mov)
- MPEG (.mpg / .mpeg)
- MP4 (.mp4)
- m2ts (.m2ts / .mts )
- Matroska (.mkv / .mks / .mka )
- RM ( .rm / .rmvb)
- TS/PS
AVI : 可用MPEG-2, DIVX, XVID, WMV3, WMV4, AC-1, H.264
WMV : 可用WMV3, WMV4, AC-1
RM/RMVB : 可用RV40, RV50, RV60, RM8, RM9, RM10
MOV : 可用MPEG-2, MPEG4-ASP(XVID), H.264
MKV : 所有
视频码率、帧率、分辨率
码率
码流(Data Rate)是指视频文件在单位时间内使用的数据流量,也叫码率或码流率,通俗一点的理解就是取样率,是视频编码中画面质量控制中最重要的部分,一般我们用的单位是kb/s或者Mb/s。一般来说同样分辨率下,视频文件的码流越大,压缩比就越小,画面质量就越高。码流越大,说明单位时间内采样率越大,数据流,精度就越高,处理出来的文件就越接近原始文件,图像质量越好,画质越清晰,要求播放设备的解码能力也越高。
当然,码率越大,文件体积也越大,其计算公式是文件体积=时间X码率/8。例如,网络上常见的一部90分钟1Mbps码率的720P RMVB文件,其体积就=5400秒×1Mbps/8=675MB。
通常来说,一个视频文件包括了画面(视频)及声音(音频),例如一个RMVB的视频文件,里面包含了视频信息和音频信息,音频及视频都有各自不同的采样方式和比特率,也就是说,同一个视频文件音频和视频的比特率并不是一样的。而我们所说的一个视频文件码流率大小,一般是指视频文件中音频及视频信息码流率的总和。
帧率
帧率也称为FPS(Frames Per Second)- - - 帧/秒。是指每秒钟刷新的图片的帧数,也可以理解为图形处理器每秒钟能够刷新几次。越高的帧速率可以得到更流畅、更逼真的动画。每秒钟帧数(FPS)越多,所显示的动作就会越流畅。
关于帧率有如下几个基础数据:
- 帧率越高,cpu消耗就高
- 秀场视频直播,一般帧率20fps
- 普通视频直播,一般帧率15fps
分辨率
视频分辨率是指视频成像产品所成图像的大小或尺寸。常见的视像分辨率有352×288,176×144,640×480,1024×768。在成像的两组数字中,前者为图片长度,后者为图片的宽度,两者相乘得出的是图片的像素,长宽比一般为4:3.
480P : 640 x 480 个像素点
720P : 1280 x 720 个像素点
1080P : 1920 x 1080 个像素点
然后还需要关注每个像素点的存储格式,每个像素点占用的字节大小。
图像存储格式yuv
一幅彩色图像的基本要素是什么?
1、宽:一行有多少个像素点。
2、高:一列有多少个像素点,一帧有多少行
3、YUV格式还是RGB格式?
4、一行多少个字节??
5、图像大小是多少?
6、图像的分辨率多少?
说白了,一幅图像包括的基本东西就是二进制数据,其容量大小实质即为二进制数据的多少。一幅1920x1080像素的YUV422的图像,大小是1920X1080X2=4147200(十进制),也就是3.95M大小。这个大小跟多少个像素点和数据的存储格式有关。
YUV与像素的关系:
YUV格式,与我们熟知的RGB类似,YUV也是一种颜色编码方法,主要用于电视系统以及模拟视频领域,它将亮度信息(Y)与色彩信息(UV)分离,没有UV信息一样可以显示完整的图像,只不过是黑白的,这样的设计很好地解决了彩色电视机与黑白电视的兼容问题。并且,YUV不像RGB那样要求三个独立的视频信号同时传输,所以用YUV方式传送占用极少的频宽。
YUV格式有两大类:planar和packed。对于planar的YUV格式,先连续存储所有像素点的Y,紧接着存储所有像素点的U,随后是所有像素点的V。对于packed的YUV格式,每个像素点的Y,U,V是连续交替存储的。
YUV,分为三个分量,“Y”表示明亮度(Luminance或Luma),也就是灰度值;而“U”和“V” 表示的则是色度(Chrominance或Chroma),作用是描述影像色彩及饱和度,用于指定像素的颜色。
YUV是利用一个亮度(Y)、两个色差(U,V)来代替传统的RGB三原色来压缩图像。传统的RGB三原色使用红绿蓝三原色表示一个像素,每种原色占用一个字节(8bit),因此一个像素用RGB表示则需要8 * 3=24bit。
如果使用YUV表示这个像素,假设YUV的采样率为:4:2:0,即每一个像素对于亮度Y的采样频率为1,对于色差U和V,则是每相邻的两个像素各取一个U和V。对于单个的像素来说,色差U和V的采样频率为亮度的一半。如有三个相邻的像素,如果用RGB三原色表示,则共需要占用:8 * 3 * 3 = 72bits;如果采用YUV(4:2:0)表示,则只需要占用:8 * 3(Y)+ 8* 3 * 0.5(U)+ 8 * 3 * 0.5(V)= 36bits。只需原来一半的空间,就可以表示原来的图像,数据率压缩了一倍,而图像的效果基本没发生变化。
那么,具体yuv格式所占用的字节数要怎么算呢 ?
YUV图像格式的内存大小
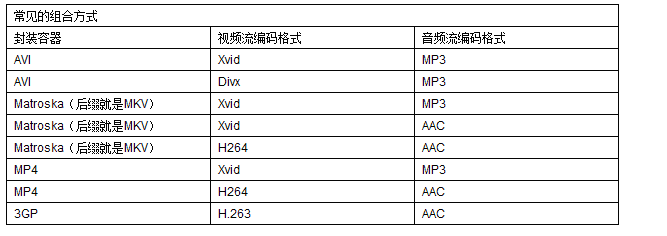
4:4:4 表示色度值(UV)没有减少采样。即Y,U,V各占一个字节,加上Alpha通道一个字节,总共占4字节.这个格式其实就是24bpp的RGB格式了。
4:2:2 表示UV分量采样减半,比如第一个像素采样Y,U,第二个像素采样Y,V,依次类推,这样每个点占用2个字节.二个像素组成一个宏像素.
- 需要占用的内存:w * h * 2
4:2:0 这种采样并不意味着只有Y,Cb而没有Cr分量,这里的0说的U,V分量隔行才采样一次。比如第一行采样 4:2:0 ,第二行采样 4:0:2 ,依次类推…在这种采样方式下,每一个像素占用16bits或10bits空间.
- 内存则是:yyyyyyyyuuvv
- 需要占用的内存:w * h * 3 / 2
4:1:1 可以参考4:2:2分量,是进一步压缩,每隔四个点才采一次U和V分量。一般是第1点采Y,U,第2点采Y,第3点采YV,第4点采Y,依次类推。
帧率、码率与分辨率之间关系
码率和帧率没有半毛钱关系
码率关系着带宽、文件体积
帧率关系着画面流畅度和cpu消耗
分辨率关系着图像尺寸和清晰度
一个视频文件的大小为5.86M,播放时长为3分7秒
1,该文件对应的码率就是
- 5.86 * 1024 * 1024 * 8 / (3 * 60 + 7) = 262872.95657754bps
2,10M独享带宽能支撑的同时在线人数
- 10 * 1024 * 1024 / 262872.95657754 = 39.889078498294
3, 支撑1000人同时在线的系统最少需要的带宽数为
- 262872 * 1000 / (1024 * 1024) = 250.69427490234M
10min,流量消耗41587KB
41587/10*60 = 69KB/s = 69 * 8 Kb/s = 532Kb/s
那么得到码率就是 532Kb/s
输出文件大小公式
一个音频编码率为128Kbps,视频编码率为800Kbps的文件,其总编码率为928Kbps,意思是经过编码后的数据每秒钟需要用928K比特来表示。
文件大小公式:
(音频编码率(KBit为单位)/8 + 视频编码率(KBit为单位)/8)× 影片总长度(秒为单位)= 文件大小(MB为单位)
一帧图像大小
一帧图像原始大小 = 宽像素 * 长像素 ,当然要考虑数据格式,因为数据格式不一样,大小写也不相同,一般数据采用rgb、yuv格式,如rgb32、yuv420、yuv422等。最常用的应当属于yuv420。 因此,计算公式为:
文件的字节数 = 图像分辨率 * 图像量化位数/8
图像分辨率 = X方向的像素数 * Y方向的像素数
图像量化数 = 二进制颜色位数
RGB24每帧的大小是
- size=width×heigth×3 Bit
RGB32每帧的大小是
- size=width×heigth×4
YUV420每帧的大小是
- size=width×heigth×1.5 Bit
举例说明,对于一个1024*768的图像实际的YUV422数据流大小就为:1024 768 2 = 1572864bit
音频采样率、位数
1、声道数:声道数是音频传输的重要指标,现在主要有单声道和双声道之分。双声道又称为立体声,在硬件中要占两条线路,音质、音色好, 但立体声数字化后所占空间比单声道多一倍。
2、量化位数: 量化位是对模拟音频信号的幅度轴进行数字化,它决定了模拟信号数字化以后的动态范围。由于计算机按字节运算,一般的量化位数为 8位和16位。量化位越高,信号的动态范围越大,数字化后的音频信号就越可能接近原始信号,但所需要的存储空间也越大。
3、采样率:也称为采样速度或者采样频率,定义了每秒从连续信号中提取并组成离散信号的采样个数,它用赫兹(Hz)来表示。采样率是指将模拟信号转换成数字信号时的采样频率,也就是单位时间内采样多少点。一个采样点数据有多少个比特。比特率是指每秒传送的比特(bit)数。单位为 bps(Bit Per Second),比特率越高,传送的数据越大,音质越好.
采样率的选择应该遵循奈奎斯特(Harry Nyquist)采样理论( 如果对某一模拟信号进行采样,则采样后可还原的最高信号频率只有采样频率的一半,或者说只要采样频率高于输入信号最高频率的两倍,就能从采样信号系列重构原始信号 )。根据该采样理论, CD激光唱盘采样频率为 44kHz,可记录的最高音频为 22kHz,这样的音质与原始声音相差无几,也就是我们常说的超级高保真音质。通信系统中数字电话的采用频率通常为 8kHz,与原 4k带宽声音一致的。
比特率(音频) = 采样率 x 采用位数 x 声道数.
以电话为例,每秒3000次取样,每个取样是7比特,那么电话的比特率是21000。 而CD是每秒 44100次取样,两个声道,每个取样是13位PCM编码,所以CD的比特率是44100*2*13=1146600,也就是说CD每秒的数据量大约是 144KB,而一张CD的容量是74分等于4440秒,就是639360KB=640MB。
I帧、P帧、B帧、IDR帧
I帧:帧内编码帧
I帧特点:
- 它是一个全帧压缩编码帧。它将全帧图像信息进行JPEG压缩编码及传输;
- 解码时仅用I帧的数据就可重构完整图像;
- I帧描述了图像背景和运动主体的详情;
- I帧不需要参考其他画面而生成;
- I帧是P帧和B帧的参考帧(其质量直接影响到同组中以后各帧的质量);
- I帧是帧组GOP的基础帧(第一帧),在一组中只有一个I帧;
- I帧不需要考虑运动矢量;
- I帧所占数据的信息量比较大。
P帧:前向预测编码帧
P帧的预测与重构:P帧是以I帧为参考帧,在I帧中找出P帧“某点”的预测值和运动矢量,取预测差值和运动矢量一起传送。在接收端根据运动矢量从I帧中找出P帧“某点”的预测值并与差值相加以得到P帧“某点”样值,从而可得到完整的P帧。又称predictive-frame,通过充分将低于图像序列中前面已编码帧的时间冗余信息来压缩传输数据量的编码图像,也叫预测帧
P帧特点:
- P帧是I帧后面相隔1~2帧的编码帧;
- P帧采用运动补偿的方法传送它与前面的I或P帧的差值及运动矢量(预测误差);
- 解码时必须将I帧中的预测值与预测误差求和后才能重构完整的P帧图像;
- P帧属于前向预测的帧间编码。它只参考前面最靠近它的I帧或P帧;
- P帧可以是其后面P帧的参考帧,也可以是其前后的B帧的参考帧;
- 由于P帧是参考帧,它可能造成解码错误的扩散;
- 由于是差值传送,P帧的压缩比较高。
B帧:双向预测内插编码帧。
B帧的预测与重构:B帧以前面的I或P帧和后面的P帧为参考帧,“找出”B帧“某点”的预测值和两个运动矢量,并取预测差值和运动矢量传送。接收端根据运动矢量在两个参考帧中“找出(算出)”预测值并与差值求和,得到B帧“某点”样值,从而可得到完整的B帧。 又称bi-directional interpolated prediction frame,既考虑与源图像序列前面已编码帧,也顾及源图像序列后面已编码帧之间的时间冗余信息来压缩传输数据量的编码图像,也叫双向预测帧
B帧特点:
- B帧是由前面的I或P帧和后面的P帧来进行预测的;
- B帧传送的是它与前面的I或P帧和后面的P帧之间的预测误差及运动矢量;
- B帧是双向预测编码帧;
- B帧压缩比最高,因为它只反映丙参考帧间运动主体的变化情况,预测比较准确;
- B帧不是参考帧,不会造成解码错误的扩散。
IDR 帧
IDR(Instantaneous Decoding Refresh)–即时解码刷新。
I和IDR帧都是使用帧内预测的。它们都是同一个东西而已,在编码和解码中为了方便,要首个I帧和其他I帧区别开,所以才把第一个首个I帧叫IDR,这样就方便控制编码和解码流程。IDR帧的作用是立刻刷新,使错误不致传播,从IDR帧开始,重新算一个新的序列开始编码。而I帧不具有随机访问的能力,这个功能是由IDR承担。IDR会导致DPB(DecodedPictureBuffer参考帧列表——这是关键所在)清空,而I不会。IDR图像一定是I图像,但I图像不一定是IDR图像。一个序列中可以有很多的I图像,I图像之后的图像可以引用I图像之间的图像做运动参考。一个序列中可以有很多的I图像,I图像之后的图象可以引用I图像之间的图像做运动参考。
对于IDR帧来说,在IDR帧之后的所有帧都不能引用任何IDR帧之前的帧的内容,与此相反,对于普通的I-帧来说,位于其之后的B-和P-帧可以引用位于普通I-帧之前的I-帧。从随机存取的视频流中,播放器永远可以从一个IDR帧播放,因为在它之后没有任何帧引用之前的帧。但是,不能在一个没有IDR帧的视频中从任意点开始播放,因为后面的帧总是会引用前面的帧。
小结
I帧表示关键帧,你可以理解为这一帧画面的完整保留;解码时只需要本帧数据就可以完成(因为包含完整画面).
P帧表示的是这一帧跟之前的一个关键帧(或P帧)的差别,解码时需要用之前缓存的画面叠加上本帧定义的差别,生成最终画面。(也就是差别帧,P帧没有完整画面数据,只有与前一帧的画面差别的数据).
B帧是双向差别帧,也就是B帧记录的是本帧与前后帧的差别,换言之,要解码B帧,不仅要取得之前的缓存画面,还要解码之后的画面,通过前后画面的与本帧数据的叠加取得最终的画面。B帧压缩率高,但是解码时CPU会比较累~。
PTS:Presentation Time Stamp。PTS主要用于度量解码后的视频帧什么时候被显示出来
DTS:Decode Time Stamp。DTS主要是标识读入内存中的bit流在什么时候开始送入解码器中进行解码。
DTS主要用于视频的解码,在解码阶段使用.PTS主要用于视频的同步和输出.在display的时候使用.在没有B frame的情况下.DTS和PTS的输出顺序是一样的.
GOP
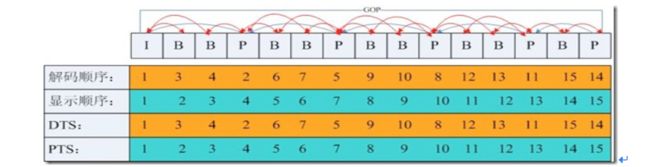
两个I frame之间形成一个GOP,在x264中同时可以通过参数来设定bf的大小,即:I 和p或者两个P之间B的数量。如果有B frame 存在的情况下一个GOP的最后一个frame一定是P.
一般平均来说,I的压缩率是7(跟JPG差不多),P是20,B可以达到50,可见使用B帧能节省大量空间,节省出来的空间可以用来保存多一些I帧,这样在相同码率下,可以提供更好的画质。在码率不变的前提下,GOP值越大,P、B帧的数量会越多,平均每个I、P、B帧所占用的字节数就越多,也就更容易获取较好的图像质量;Reference越大,B帧的数量越多,同理也更容易获得较好的图像质量。
如果一个GOP里面丢了I帧,那么后面的P帧、B帧也将会无用武之地,因此必须丢掉,但是一般策略会保证I帧不丢(如通过tcp协议保证) ,如果采用UDP,那么也会有更多的策略来保证I帧正确传输。
编解码
硬编解码
通过硬件实现编解码,减轻CPU计算的负担,如GPU等
软编解码
如 H264、H265、MPEG-4等编解码算法,更消耗CPU
数据优化
数据优化和编解码算法息息相关,一般而言
视频帧大小
- 一般I 帧的压缩率是7,P 帧是20,B 帧可以达到50 (数据不精确)
- P帧大概是3~4KB (480P, 1200k码率, baseline profile)
音频帧大小
- (采样频率(Hz)* 采样位数(bit)* 声道数)/ 8
- 48000hz大概经过AAC压缩后,应该是12KB/s左右
流媒体传输协议
常用的流媒体协议主要有 HTTP 渐进下载和基于 RTSP/RTP 的实时流媒体协议,这二种基本是完全不同的东西
CDN直播中常用的流媒体协议包括RTMP,HLS,HTTP FLV
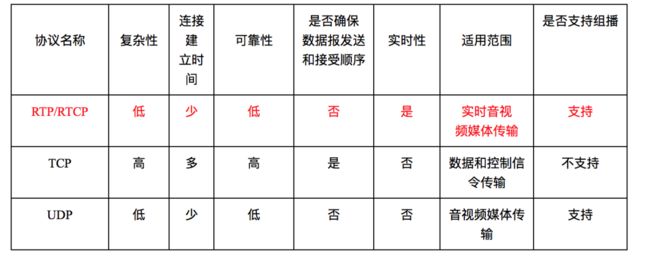
RTP,RTCP
实时传输协议(Real-time Transport Protocol),RTP协议常用于流媒体系统(配合RTCP协议),视频会议和一键通系统(配合H.323或SIP),使它成为IP电话产业的技术基础。RTP协议和RTP控制协议RTCP一起使用,而且它是建立在UDP协议上的。
实时传输控制协议(Real-time Transport Control Protocol或RTP Control Protocol或简写RTCP)是实时传输协议的一个姐妹协议。RTCP为RTP媒体流提供信道外控制。RTCP本身并不传输数据,但和RTP一起协作将多媒体数据打包和发送。RTCP定期在流多媒体会话参加者之间传输控制数据。RTCP的主要功能是为RTP所提供的服务质量提供反馈。
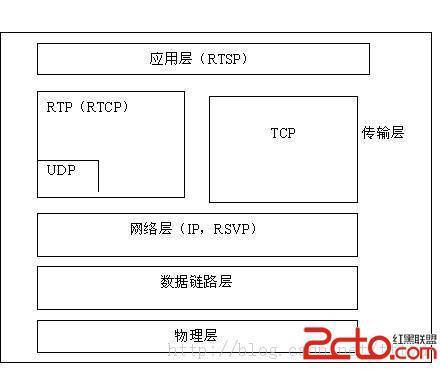
RTSP+RTP经常用于IPTV领域。因为其采用UDP传输视音频,支持组播,效率较高。但其缺点是网络不好的情况下可能会丢包,影响视频观看质量。
小结
RTMP
RTMP(Real Time Messaging Protocol)实时消息传送协议是Adobe Systems公司为Flash播放器和服务器之间音频、视频和数据传输 开发的开放协议。
它有三种变种:
- 工作在TCP之上的明文协议,使用端口1935;
- RTMPT封装在HTTP请求之中,可穿越防火墙;
- RTMPS类似RTMPT,但使用的是HTTPS连接;
总结: RTMP协议基于TCP来实现,每个时刻的数据,收到后立刻转发,一般延迟在1-3s左右
HLS
HTTP Live Streaming(HLS)是苹果公司(Apple Inc.)实现的基于HTTP的流媒体传输协议,可实现流媒体的直播和点播。HLS点播,基本上就是常见的分段HTTP点播,不同在于,它的分段非常小。基本原理就是将视频或流切分成小片(TS), 并建立索引(M3U8).
相对于常见的流媒体直播协议,例如RTMP协议、RTSP协议、MMS协议等,HLS直播最大的不同在于,直播客户端获取到的,并不是一个完整的数据流。HLS协议在服务器端将直播数据流存储为连续的、很短时长的媒体文件(MPEG-TS格式),而客户端则不断的下载并播放这些小文件,因为服务器端总是会将最新的直播数据生成新的小文件,这样客户端只要不停的按顺序播放从服务器获取到的文件,就实现了直播。由此可见,基本上可以认为,HLS是以点播的技术方式来实现直播。由于数据通过HTTP协议传输,所以完全不用考虑防火墙或者代理的问题,而且分段文件的时长很短,客户端可以很快的选择和切换码率,以适应不同带宽条件下的播放。不过HLS的这种技术特点,决定了它的延迟一般总是会高于普通的流媒体直播协议。
总结: HLS协议基于HTTP短连接来实现,集合一段时间数据,生成ts切片文件,然后更新m3u8(HTTP Live Streaming直播的索引文件),一般延迟会大于10s
HTTP-FLV
HTTP-FLV基于HTTP长连接,通RTMP一样,每个时刻的数据,收到后立刻转发,只不过使用的是HTTP协议,一般延迟在1-3s
CDN
CDN架构设计比较复杂。不同的CDN厂商,也在对其架构进行不断的优化,所以架构不能统一而论。这里只是对一些基本的架构进行简单的剖析。
CDN主要包含:源站、缓存服务器、智能DNS、客户端等几个主要组成部分。
源站:是指发布内容的原始站点。添加、删除和更改网站的文件,都是在源站上进行的;另外缓存服务器所抓取的对象也全部来自于源站。对于直播来说,源站为主播客户端。
缓存服务器:是直接提供给用户访问的站点资源,由一台或数台服务器组成;当用户发起访问时,他的访问请求被智能DNS定位到离他较近的缓存服务器。如果用户所请求的内容刚好在缓存里面,则直接把内容返还给用户;如果访问所需的内容没有被缓存,则缓存服务器向邻近的缓存服务器或直接向源站抓取内容,然后再返还给用户。
智能DNS:是整个CDN技术的核心,它主要根据用户的来源,以及当前缓存服务器的负载情况等,将其访问请求指向离用户比较近且负载较小的缓存服务器。通过智能DNS解析,让用户访问同服务商下、负载较小的服务器,可以消除网络访问慢的问题,达到加速作用。
客户端:即发起访问的普通用户。对于直播来说,就是观众客户端。
弱网优化
弱网优化的策略包括如下:
播放器Buffer
丢帧策略 (优先丢P帧,其次I帧,最后音频)
自适应码率算法
双向链路优化
音频FEC冗余算法(20%丢包率)
丢帧
在弱网情况下,为了达到更好的体验,可能会采取丢帧的策略,但是丢帧,怎么丢呢?丢音频帧还是视频帧呢 ? 因为视频帧比较大,并且视频帧前后是有关联的;音频帧很小,关键是音频帧是连续采样的,丢了音频帧,那声音就会明显出现瑕疵。为此,一般的丢帧策略是丢视频帧
自适应码率
在弱网情况下,另外一种靠谱的策略是自适应码率算法,通过设置码率降级为多个档次,这样,当网络不好的情况下,通过降低码率进行预测,如果码率降低后,还不够buffer缓冲,那么继续降低一个档次,是一个循环探测的过程,如果再次降级一个档次后,发现buffer缓冲足够了,那么说明当前网络能够适应这个码率,因此就会采取当前码率。同理,升档也是一样的。但是这个属于厂商的核心算法,
实时聊天的挑战
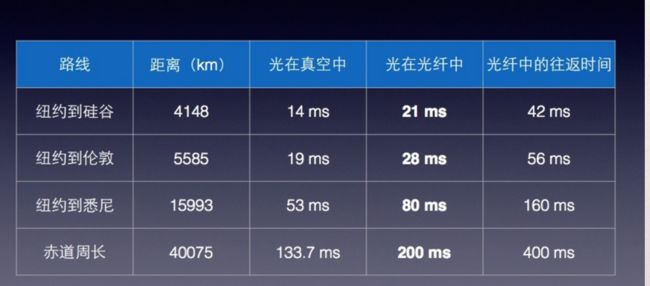
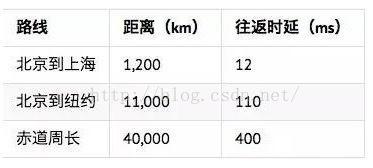
简单估算一下大概的网络延时。众所周知,光在真空中的速度约为300,000km/s,而在其他介质中光 速会大大降低,所以在普通光纤中,工程上一般认为传输速度是200,000km/s。从现实上来说,可以参考如下:
实时聊天的挑战主要在于以下几点:
实时性: 600ms以内
网络的不对称性
距离
常见问题和解决方案
出现花屏、绿屏问题
- 采集问题、编解码问题、声网传输丢帧问题
声画不同步
- 采集问题,或者公有云SDK问题
画面有时候有点糊
- 弱网,码率的自适应
有声音没有画面
- 弱网,触发了丢帧策略
画面播放有时候卡顿
- CPU消耗过高导致卡顿,比如AR模块
- 弱网
网络连接不上
- 弱网
- 或者代码有Bug,或者公有云SDK有Bug
出现马赛克现象?
- 是否类似花屏 ?
TODO
其他常见指标 和 问题解决方案