《深入分析JavaWeb 技术内幕》第一章深入Web请求
B/S架构概述
输入一个网址到获得对应的结果,中间都经历了什么过程呢?(没想到第一章就get到一个面试常问题型2333)
用户输入一个URL后,首先查询本地host是否记录了对应的ip地址,如若没有就去DNS服务器上查找,找到地址后向该ip对应服务器发起请求,由该服务器决定返回默认数据给用户。而服务器那边的处理也会些许复杂,因为可能使用了多台服务器,需要由一个负债均衡设备来平均分配所有用户的请求。
不同的架构不同可能采取的技术不一样,但是一些原则是不会变的
- URL:统一资源定位符,发布一个服务或者资源到互联网上,必须拥有独一无二的URL。
- 必须基于HTTP与服务端交互。
- 数据在浏览器中展示。
如何发起一个请求
HTTP请求和如何建立一个Socket连接本质上是一样的。
可以用org.apache.commons的工具包可以干这事。这是一个get请求。
public class TestSocket {
public static void main(String[] args) {
HttpClient client = new HttpClient();
GetMethod getMethod = new GetMethod("https://www.baidu.com");
int code;
try {
code = client.executeMethod(getMethod);
if(code==200){
String res = getMethod.getResponseBodyAsString();
System.out.println(res);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
linux下也有一个curl的命令可以做类似的操作。
![]()
再之后加上-I可以获得http头信息
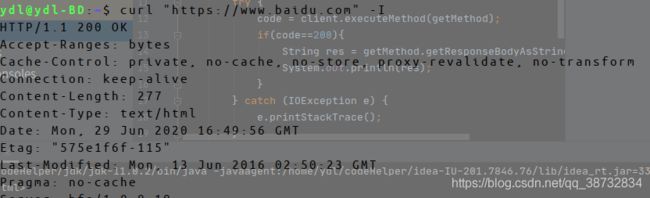 因为加上了cookie还是无法访问一些网页,或许应该还要加上浏览器版本信息之类,才能响应吧?所以俺就不演示了,详细的可以使用curl --help来获取详细帮助。
因为加上了cookie还是无法访问一些网页,或许应该还要加上浏览器版本信息之类,才能响应吧?所以俺就不演示了,详细的可以使用curl --help来获取详细帮助。
HTTP解析
重点关注HTTP Header,它控制着用户浏览器的渲染与服务器执行逻辑。
| 请求头 | 说明 |
|---|---|
| Accept | 告知服务器可以处理的内容类型 |
| Accept-Charset | 用于指定客户端接收的字符集 |
| Accept-Encoding | 指定接受的内容编码格式 |
| Accept_Language | 指定自然语言类型 |
| Host | 指定被请求的Internet主机和端口号 |
| User-Agent | 客户端将它的操作系统、浏览器和其他属性告诉服务器 |
| Connection | 当前连接是否保持 |

| 响应头 | 说明 |
|---|---|
| Server | 服务器的名称 |
| Conten-Type | 用来指明发送给接受者的实体正文的媒体类型 |
| Content-Encoding | 告诉浏览器端,服务器端采用的内容编码格式 |
| Content_Language | 指定自然语言类型 |
| Content-Length | 描述资源所用的自然语言 |
| Keep-Alive | 保持连接的时间 |
常用状态码:
| 状态码 | 说明 |
|---|---|
| 200 | 请求成功 |
| 302 | 临时跳转 |
| 400 | 客户端请求语法错误 |
| 403 | 服务器收到请求但拒绝服务 |
| 404 | 资源不存在 |
| 500 | 服务器发生不可预期的错误 |
DNS域名解析
解析的过程:
1.浏览器本地缓存,有,获取;没有,下一步。
2.本地host文件,有,获取,没有,下一步。
3.网络配置中都会有DNS服务器地址这一项,如果前两步失败,则会将域名发送给LDNS(本地区域名服务器),Linux下可使用cat /etc/resolv.conf查看,Windows下使用ipconfig,有,获取,没有,下一步
4.到Root Server域名服务器请求解析,如果再找不到,就是域名不存在了。
5.根域名服务器返回给本地域名服务器一个所查询域的主域名服务器(gTLD Server).gTLD是国际顶级域名服务器,如.com,.cn,.org等。
6.LDNS再向gTLD发送请求。
7.gTLD再查找并返回此域名对应的Name Server域名服务器的地址,
8.Name Server服务器中存储了域名与IP的映射关系,IP和一个TTL(缓存的时间)时间一起返回。
9.LDNS会缓存这个域名和IP的映射关系。
10.解析结果返回给用户,用户根据TTL值缓存于本地,解析过程结束。
注意Name Server可能分肯多级或者使用一个GTM来负载均衡,这可能会影响到解析的过程。
可使用nslookup命令来跟踪解析过程。linux下还可使用dig命令
windows下可使用ipconfig/flushdns 来刷新缓存,linux下则可使用sudo /etc/init.d/nscd restart。
JVM中也会缓存DNS的解析结果,有两种缓存策略,其一,缓存正确结果,其二缓存错误结果,缓存时间由两个配置项控制,java.security文件中的networkaddress.chache.ttl和networkkaddress.cache.negative.ttl,默认值是-1(永不过期)和10(缓存10秒)
可直接修改配置文件,也可通过启动参数中增加-Dsun.net.inetaddr.tll=xxx来修改默认值,通过InetAddress类动态修改。如果需要用InetAddress类解析域名必须使用单例模式,不然会有严重的性能问题。
解析记录分为:
- A记录,可将多个域名解析到一个IP地址
- MX记录,可将某个域名下的邮件服务器指向自己的Mail Server。
- CNAME记录,为一个域名设置多个别名。
- NS记录,为某个域名指定DNS解析服务器,也就是这个域名有指定的IP地址的DNS服务器取解析。
- TXT记录,为某个域名或主机名设置说明。
CDN工作机制。
CDN就是内容分部网络,它是一种构筑在现有Internet上的一种先进的流量分配网络。将网站发布的内容发布到最接近用户的网络“边缘”,使用户可以就近所得所需资源,提高响应速率。CDN≈镜像+缓存+整体负载均衡
目前CDN都以缓存网站中的静态数据为主,从主站服务器中获取动态数据后,再从CDN上下载这些静态数据,加速数据内容的下载速度。
它可达到以下几个目标:
- 可拓展性,分为性能可拓展(应对数据、用户和事务的可拓展性)和成本可拓展(用低廉的运营成本提供动态的服务能力和高质量的分发)
- 安全性,减少DDos攻击或者其他恶意行为
- 可靠性、响应和执行,服务可用性指能够处理可能的故障和用户体验下降的问题,通过负债均衡及时提供的容错机制。
CDN架构如下图所示:
 以上图均来自原书。1,2是检查本地的DNS缓存和host文件。
以上图均来自原书。1,2是检查本地的DNS缓存和host文件。
负载均衡
对工作任务进行平衡,分摊到多个操作单元上执行,共同完成任务。
通常有三种类型的架构:1.链路负载均衡(参见DNS解析域名的过程) 2.集群负载均衡(分为硬件和软件,硬件,一般一主一备,价格非常昂贵,无法动态扩容,优点的性能高。软件,最为常见,成本非常低,缺点是一次访问请求要经过多次代理服务器增加网络负担) 3.操作系统负载均衡(利用操作系统级别的软中断和硬件中断来达到负载均衡)
负载均衡是由DNS解析来完成的,有它来决定最终访问哪个服务器。
CDN动态加速
在CDN的DNS解析通过动态链路探测来寻找回源最好的一条路径。
由于CDN节点遍布全国,一个用户接入一个节点后,可以选择一条离用户最近的CDN节点到源站链路最好的路径让用户走。比如可以每个节点从源站下载相同大小的文件,总耗时最短的路径就可以保存下来,更新到CDN的Local DNS中,当然时间并非唯一的成本,来由网络成本等。
这一章看完我感觉,这本书的定位应该是用于梳理知识脉络,知识面是足够广的,但是用于入门学习而言太含糊,用于深入而言深度不够。所以有购入打算的朋友,可以斟酌一下。