oracle如何拆分以逗号分隔的字符串为多行?
---构建测试表t如下:
select 'a1' x, 'a,b,c,d' y from dual
union all
select 'a2' x, 'e,f,g' y from dual
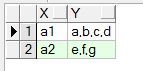
---需求:依据上表中y字段的值,将一行记录拆分为多行,并达到如下效果
--方法1---
with t AS (
select 'a1' x, 'a,b,c,d' y from dual
union all
select 'a2' x, 'e,f,g' y from dual
)
SELECT y, regexp_substr(y||',', '[^,]+', 1, rownum) yy
from (select y from t
WHERE y like '%,%'
) connect by rownum <= length(y) - length(replace(y, ',', ''))+1
该语句的执行结果如下:

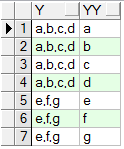
注:当t表中只有一条数据需要拆分时,上述写法适用。但是,因为示例的t表中有多行记录,第二条以及之后的行拆分的数据就不对了。原因是从第2行记录开始,y字段的数据不是从第1个逗号开始拆的,而是第n行(n=从上一行拆分完成后的"行号")开始拆,这样如果第一行的逗号数(即拆分的行数)如果没有超过第二行的逗号数,那么第二行数据拆出的条数就会少,而如果第一行拆分行数多于第二行的逗号数,那么第二行的拆分结果就只能返回为null了,第三行、第四行及之后的数据,同理……(不赘述)。
-----方法2:(可解决上述问题)
with t AS (
select 'a1' x, 'a,b,c,d' y from dual
union all
select 'a2' x, 'e,f,g' y from dual
)
SELECT y, regexp_substr(y, '[^,]+', 1, level) yy
from t
where instr(y, ',') > 0
connect by level <= regexp_count(y, ',') + 1 --oracle11g以上版本可用
and y = prior y
and prior dbms_random.value is not null
执行结果如下: