原文发布于个人博客(好望角),并在博客持续修改更新,此处可能更新不及时。
抽空复习了一下python的语言特性,其中容易忘记、混淆的点特地记录如下。
python 特性
- 运行速度
- python > java > c
- c 适合充分发挥硬件性能的任务,贴近硬件的任务
- python 优点
- 完善的基础代码库
- 高级语言,易理解,代码短而优雅
- python 缺点
- 代码不能加密,如果发布python程序必须发布源代码
- 作为解释型语言,需要相应语言的解释器,“翻译”成目标代码后执行,不可脱离解释器运行。所以效率低……(不过这不是事儿,部署线上应用时网络更慢……)
- cpython 是使用最广的 python 解释器
python 基础
-
输入输出
- a = input(‘写输入提示’) 输入数据的默认类型是字符串
- print()
-
基本数据类型
- 因为是动态语言,不必事先设定好变量类型
- ==地板除 // 相当于取除法结果的整数部分==,常搭配取余运算。
-
编码问题
- 为了能统一表示各种语言,内存中用的是unicode编码,但是为了提升网络传输效率,我们保存的磁盘文件往往应该写成utf-8编码
- 格式化输出
- 可以用占位符(%s) %d %f %s %x
- .format() 函数
- list 和 tuple
- 能用tuple 就多用,它一经建立就不可进行添加、删除等操作,相当于一个只读的list。这样代码更安全,鲁棒;
- 它们内部都可以放多种类型的数据;
- 尽量避免过多地使用 continue 和 break 提前结束循环,因为这样会造成逻辑混乱。
-
dic & list
- 随着数据量的变大,dic 的查询性能优势就会越好的体现出来
- 但是会比较占用内存
- dic 是一种用空间换时间的方法,查询靠hash表完成
-
set
-
相当于dic 的 key ,同样不可放入重复的元素。这里的集合不可改变针对的是不可变元素,如果集合内有可变元素列表是可以改变的。
t1=(1,2,3,[1,2,3]) t1[-1][-1]=4 t1 >>> (1, 2, 3, [1, 2, 4])
-
-
不可变元素
- str、int 、float 、tuple 是不可变元素,对于改变它的操作,本质上是生成了一个新的字符串,应该定义一个新的变量指向这个新的字符串
函数
-
占位符
- pass没有实际意义,用于没想好怎么写的函数体。先把程序框架搭起来
-
返回值
- 函数可以返回多个值。但其实相当于返回一个tuple组,多个变量接受对应位置的返回值。
- 默认的自动返回值是None
-
检查参数
- 在函数体内部首先检查参数的类型是否输入正确是一个好的习惯
-
函数参数类型
- 默认参数放在必选参数后面,默认参数一般是变化小的数。
- 使用默认参数可以有效降低调用函数的难度。
- ==默认参数一定要是不可变对象==,否则每次调用默认参数其实都会改变默认参数的值,程序可能会出错
程序设计能设计成不变对象(例如:str,None等扽那个)是最好的。因为不易导致修改数据带来的错误。而且在多任务的环境下不用加锁,因为数据是不会改变的。
- 当参数数量不确定的时候用可变参数,普通参数nums可以变成可变参数*nums。想将一个列表中数据都传入的时候也可以用 *list , 可变参数传入函数后一一个元组的形式存在。
- 关键字参数**other 可以接受一个dic,即任意个数的带名字的参数。调用的时候和可变参数一样,可以直接传入一个dic
- 命名关键字参数。放在函数参数的最后,用一个 * 将他们与前面的位置参数分隔开。如果有可变参数将命名关键字参数与位置参数分隔开了,就不必再单独用一个 * 隔开他们
- 函数参数定义的顺序必须是:必选参数、默认参数、可变参数、命名关键字参数和关键字参数
- 但是最好不要同时使用多种参数类型,导致程序可解释性太差
-
递归函数
- 理论上,所有的递归函数都可以写成循环的形式。但是写成循环逻辑不清晰
- 递归函数要小心过深的调用会导致堆栈溢出(缺点)
- 采取尾递归的方式,递归函数值只会占用一个栈帧,就不会堆栈溢出了。即,return 的就是递归函数本身,而不是包含递归函数的一个表达式
- 可惜的是,与大多数编程语言一样,python 并没有实现尾递归的优化。任何递归函数都存在栈溢出的风险。
- 一个递归函数例子:汉诺塔!
- 对字符串进行递归删除的时候小心索引错误。
高级特性
- 切片
- 切片操作为什么在对于空字符串只能用S[0:1]不报错,而用s[0]就会报错?
- ==切片操作允许超出索引,或者部分缺失;但是对于数组取值是不可以的!==
- 切片操作能有效代替循环,简化程序
- 迭代
- 判断某变量是否可以迭代 isinstance(s, Iterable)
- 想获得迭代对象的角标可以用 enumerate()函数
- 列表生成式
- 把代码写在一行非常的简洁
>>> [x * x for x in range(1, 11) if x % 2 == 0]
[4, 16, 36, 64, 100]
>>> [m + n for m in 'ABC' for n in 'XYZ']
['AX', 'AY', 'AZ', 'BX', 'BY', 'BZ', 'CX', 'CY', 'CZ']
>>> import os # 导入os模块,模块的概念后面讲到
>>> [d for d in os.listdir('.')] # os.listdir可以列出文件和目录
['.emacs.d', '.ssh', '.Trash', 'Adlm', 'Applications', 'Desktop', 'Documents', 'Downloads', 'Library', 'Movies', 'Music', 'Pictures', 'Public', 'VirtualBox VMs', 'Workspace', 'XCode']
- 生成器
- 可以有效节省程序的内存,一个大的列表,其中的元素随着程序的运行而一个一个的生成。
- 直接将列表生成式的[] 改成()就可以得到一个生成器
- generator 保存的是生成数据的算法,可以通过for循环或者next()函数不断的迭代新生成的数据。
- 可以把生成器做成一个函数的形式调用,他和一般的函数执行顺序不一样。执行一小段,然后返回 yield,下次调用的时候接着上次执行的地方继续往下执行。
- 注意为生成器设置一个程序停止条件。
>>> L = [x * x for x in range(10)]
>>> L
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> g = (x * x for x in range(10))
>>> g
at 0x1022ef630>
# 杨辉三角的迭代生成
# 停止条件和输出格式在调用的时候定义,最大限度地提高函数的重用率
# 列表元素还可以直接加?
def triangles():
l = [1]
while 1:
yield l
l = [1] + [l[n] + l[n + 1] for n in range(len(l) - 1)] + [1]
# 斐波那契数列的迭代生成
# 不需要中间变量的变量赋值方法,节省一点内存
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
return 'done'
- 迭代器
- 可迭代对象list、tuple、dict、set、str、generator,带有yield 的generator function
- 判断是否可迭代 isinstance({}, Iterable)
True - 相比于可迭代对象list ,迭代器iter([])的好处就是可以放入一个任意大的迭代对象,不会占用大量内存。
模块
- 作用域
- 类似_xxx和__xxx这样的函数或变量就是非公开的(private),不应该被直接引用,比如_abc,__abc等。一般的变量就是公开的
- 对于那些不需要外部引用的函数,都可以定义成_private()的private形式,代码更规范
- system
- sys.argv 可以存储命令行调用函数的所有变量(至少会有一个,就是.py的文件名本身)
内置函数
属性操作
| Func | 语法 | 作用 | retype |
|---|---|---|---|
| hasattr | hasattr(object, name) | 判断 对象中是否含有 该属性。 | True / False |
| setattr | setattr(object, name, values) | 给对象的属性 赋值,若属性不存在,先创建再赋值。 | None |
| getattr | getattr(object, name[,default]) | 获取 属性数值。 | 属性存在时,返回 属性数值;否则根据 默认输出值 返回 或 报 AttributeError。 |
| delattr | delattr(object, name) | 删除属性。 | 属性存在则无返回,否则报 AttributeError。 |
函数式编程
- map & reduce
- map(f(),iterable) 相当于把函数f作用在一个可迭代对象中的每一个元素,返回指是对应的处理后的 iterable 。
- 再看reduce的用法。reduce把一个函数作用在一个序列[x1, x2, x3, ..…]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算,其效果就是:
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
- 有用的 nonlocal 声明
- 用于函数套嵌的内部函数。如果内部函数的变量与外部函数的变量重名,相当于在内部函数新建了一个同名变量,内部函数并不能访问修改外部函数的变量。
- 但是只要在内部函数声明 nonlocal ‘变量名’ 就可以让内部函数对外部变量进行==赋值==操作。
- 字典不需要nonlocal 声明就可以在内部函数改变外部字典。
- 可以起到像静态变量的作用,‘只初始化一次,然后不断改变它 ’
- filter 过滤函数
- 与map()函数的用法一致,都是输入量两个参数,第一个是一个函数,第二个是iterable
- 所需要的返回是True or False 返回的是一个iter(惰性计算) ,所以需要套一个list 才能继续工作
- 字符串倒序技巧 str(s)[::-1]
- sorted 排序高阶函数
- 可以接受三个参数(‘排序对象’,key = ‘函数’,reverse = True)
>>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower, reverse=True)
['Zoo', 'Credit', 'bob', 'about']
- 返回函数
- 当某些功能不必立即执行的时候,定义一个内部函数,返回该内部函数。
- 同样的语句调用两次,返回的两个函数也不会是一样的,他们的运行结果也相互独立
- 相关参数和变量都保存在返回的函数中,这种称为“闭包(Closure)”的程序结构拥有极大的威力。++编写起来都是坑++
- ==返回闭包时牢记一点:返回函数不要引用任何循环变量,或者后续会发生变化的变量。==
- lambda 函数
- 冒号前面是函数参数,后面是函数体,运算结果就是函数返回值
- 匿名函数也是一个函数对象,也可以将其复制给一个变量,然后再通过变量调用它
>>> list(map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9]))
[1, 4, 9, 16, 25, 36, 49, 64, 81]
- decorator 装饰器高级函数
- 输入一个函数,返回一个函数。在代码运行的期间动态的为一些函数增加功能
- def wrapper(*args, **kw) 这样的函数能接受任意参数形式的函数作为参数,用在装饰器内部,接收旧函数,返回新函数是最好的选择。
- 一个普通的不需要参数的装饰器都要decorator 双层嵌套,而需要的参数的decorator 需要三层嵌套。
- decorator 会使func.name发生变化,导致某些调用出错。可以在wrapper前面加上@functools.wraps(func)默认的装饰器。起到保持原函数名不变的功能。
- partail 偏函数
- 为了简化我们对于常用函数的调用,可以用fu’nctools.partail() 固定函数的常用参数,返回一个新的函数,调用更方便
>>> import functools
>>> int2 = functools.partial(int, base=2)
>>> int2('1000000')
64
>>> int2('1010101')
85
防坑指南
可变对象与不可变对象
- 不可变对象: int 、string 、float 、tuple
- 可变对象: list 、dict、set
# 例子一
>>> a=b=['hello','world'];a.append('hello')
>>> print(b)
['hello','world','hello']
# 例子二
>>> a=b='hello';a='world'
>>> print(b)
hello
对于可变类型来说,两个变量名指向相同的内存地址的时候相当于给同一个内存地址起了两个名字。如果改变一个变量名的内容,并不会开辟新的内存,而是直接改变原来内存地址中的内容。也就是说对于不可变类型,不同的变量名指向的内存地址永远是相同的。
对于不可变类型来说,两个变量指向相同的内容时拥有共同的内存地址(id(arg) 命令可以查看),但是改变一个变量之后相当于另外开辟一块新内存,其内存 id 会随之改变。
但是起名可变和不可变的原因呢?是相对于函数传参来说的。
def test(a_int, b_list):
a_int = a_int + 1
b_list.append('13')
print('inner a_int:' + str(a_int))
print('inner b_list:' + str(b_list))
if __name__ == '__main__':
a_int = 5
b_list = [10, 11]
test(a_int, b_list)
print('outer a_int:' + str(a_int))
print('outer b_list:' + str(b_list))
>>> inner a_int:6
>>> inner b_list:[10, 11, '13']
>>> outer a_int:5
>>> outer b_list:[10, 11, '13']
所谓的可变类型,就是传入函数中,函数中的变化会同步到函数外的变量。类似引用传递(可以把引用理解为一个箭头,这个箭头指向某块内存地址,而引用传递,传递过来的就是这个箭头,当你修改内容的时候,就是修改这个箭头所指向的内存地址中的内容,因为外部也是指向这个内存中的内容的,所以,在函数内部修改就会影响函数外部的内容。)
而不可变类型,传入函数中的操作会事先新创造一个内存地址,所以并不会影响函数外的变量值。类似值传递(表示传递直接传递变量的值,把传递过来的变量的值复制到形参中,这样在函数内部的操作不会影响到外部的变量)。
深拷贝与浅拷贝
- 直接赋值:其实就是对象的引用(别名)。
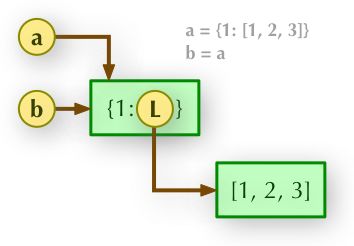
a = [1,2,3,[1,2]]
b = a
b[-1] = [1,2,3]
print(a,b)
>>> [[1,2,3,[1,2,3]],[1,2,3,[1,2,3]]]
- 浅拷贝(copy):拷贝父对象,对象的内部的子对象仍是相同的。

l1=[1,2,3,[1,2,3]]
l2=l1.copy()
l2[-1].append(4) # 子对象仍相同,同步变化
l2.append(5) # 父对象不同,不会同步变化
print(l1,l2)
>>> [[1,2,3,[1,2,3,4]], [1,2,3,[1,2,3,4],5]]
- 深拷贝(deepcopy): copy 模块的 deepcopy 方法,完全拷贝了父对象及其子对象。
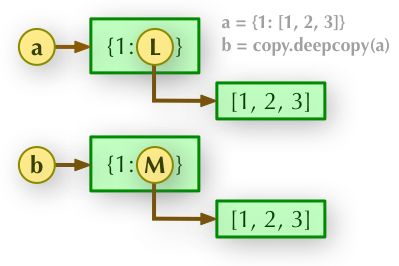
import copy
l1=[1,2,3,[1,2,3]]
l2=copy.deepcopy(l1)
l2[-1].append(4)
print(l1)
>>> [1,2,3,[1,2,3]]
# 深度拷贝是将原对象中所有的值完全复制一份存放在内存中(包括可变数据类型对象)。这样遇到原对象即使是更改,也不会影响其值。
# 复制引用与copy.copy, copy.deepcopy
import copy
a = [1, 2, 3, 4, ['a', 'b']] #原始对象
b = a #赋值,传对象的引用
c = copy.copy(a) #对象拷贝,浅拷贝
d = copy.deepcopy(a) #对象拷贝,深拷贝
a.append(5) #修改对象a
a[4].append('c') #修改对象a中的['a', 'b']数组对象
print( 'a = ', a )
print( 'b = ', b )
print( 'c = ', c )
print( 'd = ', d )
>>> ('a = ', [1, 2, 3, 4, ['a', 'b', 'c'], 5])
>>> ('b = ', [1, 2, 3, 4, ['a', 'b', 'c'], 5])
>>> ('c = ', [1, 2, 3, 4, ['a', 'b', 'c']])
>>> ('d = ', [1, 2, 3, 4, ['a', 'b']])
python 运算符优先级
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 ‘AND’ |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not or and | 逻辑运算符 |
print(100 - 25 * 3 % 4)
>>> 97
IO operations
files operations
-
read([size])文件当前位置起读取size个字节,若无参数size,则表示读取至文件结束为止,整个文件返回为一个字符串对象,文件很大时候 -
readline()每次读出一行内容,所以,读取时占用内存小,比较适合大文件,但是速度慢啊!(内存不够时采用)每次读取返回一个字符串对象。 -
reandlines()读取整个文件所有行,保存在一个列表(list)变量中,每行作为一个元素,但读取大文件会比较占内存。 -
linecache输出某个文件的第n行, 使用示例如下:
text = lincache.getline('a.txt' , 2)
print(text)
keyboard operations
- raw_input([prompt]) 可以读取一行任意字符串 str,将返回 str.strip()
s = raw_input('请输入:')
print('你刚才输入了:'+s)
请输入:hhhh
你刚才输入了:hhhh
- input([prompt]) 在 raw_input([prompt]) 的基础上多了一个接受表达式的功能,可以返回运算结果 。
dict
a = {'s':1 , 'w':1}
b = {'w':1 , 'e':1}
z = {**a , **b}
- dict.update(dictnew) 命令可以用dictnew更新覆盖原有的字典
- 在数字作为字典的key值时候,整数和浮点数是相等的,即 {1:5,1.0:6} == {1:6}
str
-
str.ljust(50,'@')用 @ 将字符串填充为长度 50 ,@填补在字符串的后面。 - 字符串可以通过切片访问,但是不可以通过这种方式赋值。
>>> a = '456123'
>>> a[-3,-1] = 'aaa'
TypeError: 'str' object does not support item assignment
-
创建新字典的方法
>>> print({}.fromkeys((1,2,8),(3,4))) {1: (3, 4), 2: (3, 4), 8: (3, 4)}
list
从本质上讲,自带pop() 、append() 函数的列表结构是以 stack 为基础的。
删除列表中的元素
- del 删除某位置的元素。
a = ['a','b','c']
del a[0] #指定删除0位的元素
print(a)
---
> ['b', 'c']
- list.remove() 删除某指定值元素。
a = ['a','b','c']
a.remove('b') #删除第一个匹配的指定元素,直接改变原数组,无返回值。
print(a)
---
> ['a', 'c']
- list.pop() 删除指定位置元素,并且返回它的数值。如果没有参数,默认参数为“-1”。
a = ['a','b','c']
b = ['d','e','f']
# pop的命令,其有返回值,可赋值带出
c = a.pop() #默认删除-1位置元素'c',并将删除元素返回值赋值
d = b.pop(0) #删除0位元素'd',并将删除元素返回值赋值
print(a,b,c,d)
---
> ['a', 'b'] ['e', 'f'] c d
- list的引用才有append()函数,不可直接调用
# 错误用法
[5,6].append(9)
list().append(9)
# 正确用法
a = [5,6]
a.append(9)
正则表达式
- ^ 符号不出现在中括号中,表示匹配开始字符;而出现在中括号中,表示匹配除了中括号中的其他所有字符。
- \w 表示匹配字母、下划线或者数字
- ? 表示正则表达式中的非贪婪模式
Others
- 任何一个内置的
shuffle()函数,返回值类型都为None,它们直接作用在原本的列表上,不会创建新对象。
import random
L = [2,3,4,56,78,9,0]
random.shuffle(L)
print(L)
当 python 中表示复数的时候,复数之间不能比较大小。
python 中表示复数,实部可以是整数、也可以是浮点数; 而虚部是关于X轴的反转程度。
python 静态类变量可以被实例或者类本身访问并且修改。
heapq 是python自带的完全二叉树结构的类型,常用于堆排序(最小堆,不受初始数据顺序影响)
deque 是python中的双端队列结构
检查函数类型时候只写函数名,不加括号;调用函数时侯加括号,返回函数的运行结果值。
python 是弱语言类型, 不用对变量类型进行直接赋值。但如果调用一个未赋值对象会报 NameError 错误。
Python变量访问时有个LEGB原则,也就是说,变量访问时搜索顺序为Local ==> Enclosing ==> Global ==> Builtin,其实很多语言都遵循这个规则。简单地说,访问变量时,先在当前作用域找,如果找到了就使用,如果没找到就继续到外层作用域看看有没有,找到了就使用,如果还是没找到就继续到更外层作用域找,如果已经到了最外层作用域了还是实在找不到就看看是不是内置对象,如果也不是,抛出异常。
自定义类中,如果我们想要返回特定信息。需要改变函数中的 __ str __ 方法
Stackless并非以库的形式和Python整合,Stackless提供的并发建模工具,比目前其它大多数传统编程语言所提供的工具都更加易用: 不仅用于Python自身,也包括Java、C++,以及其它语言。
Scrapy是Python进行网络抓取的第三方库,包含Scrapy引擎,下载器,爬虫,调度器,Item Pipeline以及中间件,并没有沟通隧道(connect)。
常用模块
os 模块
os.listdir(dirname):列出dirname下的目录和文件
os.getcwd():获得当前工作目录
os.curdir:返回当前目录(’.’)
os.chdir(dirname):改变工作目录到dirname
os.path.isdir(name):判断name是不是一个目录,name不是目录就返回false
os.path.isfile(name):判断name是不是一个文件,不存在name也返回false
os.path.exists(name):判断是否存在文件或目录name
os.path.getsize(name):获得文件大小,如果name是目录返回0
os.path.abspath(name):获得绝对路径
os.path.normpath(path):规范path字符串形式
os.path.split(name):分割文件名与目录(事实上,如果你完全使用目录,它也会将最后一个目录作为文件名而分离,同时它不会判断文件或目录是否存在)
os.path.splitext():分离文件名与扩展名
os.path.join(path,name):连接目录与文件名或目录
os.path.basename(path):返回文件名
os.path.dirname(path):返回文件路径
参考
- 廖雪峰的官方网站
- RUNOOB.COM
原文发布于个人博客(好望角),并在博客持续修改更新,此处可能更新不及时。