数据库的规范化——让你读懂什么是范式
推荐个在线SQL网站:sqlfiddle,能够满足个人即时学习需要,避免安装数据库实例的麻烦。
参考资料:Wiki百科、百度百科、Google、博客园等,定义性的内容,直接引用了官方介绍。
2019年11月19日 10:32:53
本文参照以下目录进行内容组织:
- 什么是好的数据库设计?
- 函数依赖理论
- 函数依赖的定义
- 完全函数依赖
- 部分函数依赖
- 传递函数依赖
- 关系模型的分解特性
- 模式分解存在的问题
- 保持无损连接性分解
- 保持函数依赖性分解
- 关系的规范化 ^ - ^ 戳我跳转至详情^ - ^
- 第一范式
- 第二范式
- 第三范式
- BCNF
前言: 文章针对“数据库的规范化”这一主题,从四个方面讲述了相关概念,并提供了部分实例帮助大家理解。文章的重点还是—— 范式,有相关数据库理论基础或实践的读者,可以跳过部分内容,直奔主题。
一、什么是好的数据库设计?
可以认为,好的数据库设计,应该是规范的,规范的定义是什么?
数据库规范化,又称正规化、标准化,是数据库设计的一系列原理和技术,以 减少数据库中数据冗余,增进数据的一致性。关系模型的发明者埃德加·科德最早提出范式(Normal Form)这一概念,并于1970年代初定义了第一范式、第二范式和第三范式的概念,还与Raymond F. Boyce于1974年共同定义了第三范式的改进范式——BC范式。
除外还包括针对多值依赖的第四范式,连接依赖的第五范式、DK范式和第六范式。
现在数据库设计最多满足3NF,普遍认为范式过高,虽然具有对数据关系更好的约束性,但也导致数据关系表增加而令数据库IO更易繁忙,原来交由数据库处理的关系约束现更多在数据库使用程序中完成。
以上摘自WIKI百科,关于数据库规范化的描述。官方的描述还是相当生硬的,但是是用简短的话较为全面地进行了概括。简单点说就是,通过使用不同层次的范式,达到在数据库设计中,减少数据冗余,增进数据一致性的目的。
Tips: 实际应用开发中,基于业务和其他因素,如系统架构(数据库架构)设计的需要等,普遍认为最多满足3NF。通过适当的数据库冗余,提高相关业务的处理速度、使后端业务代码更好设计、提高系统整体性能、满足数据库备份的需要、保障数据库安全(异地多活、主备同步、分布式部署等)等。毕竟,实践是检验真理的唯一标准,理论知识仅仅是实践的参考和指导。
二、函数依赖理论
-
函数依赖:
(通俗描述)
描述一个关系时,如学生表,有ID,Name,Dept。一个学号(ID)只能对应一个学生姓名(Name),一个学生只能就读于一个院系(Dept)。因此,当学号确定后,学生的姓名、所在院系也就确定了。用类似数学中的函数描述,就是y=f(x),即,学生的其他信息=f(ID)。这样的关系称为函数依赖,即,ID函数决定Name,Dept,或者说Name,Dept函数依赖于ID。记为:ID->Name,ID->Dept。
-
完全函数依赖:
(学术定义) 在一个关系中,若某个非主属性数据项依赖于全部关键字称之为完全函数依赖。(通俗描述) 例:成绩表(学号,课程号,成绩)关系中,
完全函数依赖:(学号,课程号)→ 成绩,学号 -/→ 成绩,课程号 -/→ 成绩,所以(学号,课程号)→ 成绩 是完全函数依赖 -
部分函数依赖:
(学术定义,严格定义) :在关系模式R(U)中,如果X→Y,并且存在X的一个真子集X0,使得X0→Y,则称Y对X部分函数依赖。
(通俗描述):在一个关系中,通过一组联合的键能唯一确定一个元组,但是通过这组联合键中某一个键就能确定一个元组的时,称存在部分函数依赖。 -
传递函数依赖:
(学术定义) 对于X→Y,如果Y-/→X,且Y→Z成立,那么称Z对X传递依赖,记作X→Z。
(通俗描述) 例如,有学号,宿舍号,住宿费用表关系
三、关系模型的分解特性
-
模式分解存在的问题
现有的关系模式可能存在:数据插入异常、更新异常、删除异常及单模式中数据冗余的情况,需要找到等价的模式,以解决以上存在的问题。
-
保持无损连接性分解
分解后的若干个模式,通过自然连接形成的二维表和未分解之前的二维表是等价的。
-
保持函数依赖性分解
关系分解后,原关系的闭包与分解后关系闭包的并集相等。
(如果原模式上的每一个函数依赖都在其分解后的某一个关系上成立,则这个分解是保持依赖的)
四、关系的规范化
^ - ^ ↑戳我返回目录^ - ^
下图是截至目前,有迹可循的范式,按照最不规范——最规范排序。(UNF->1NF->2NF……DKNF->6NF)

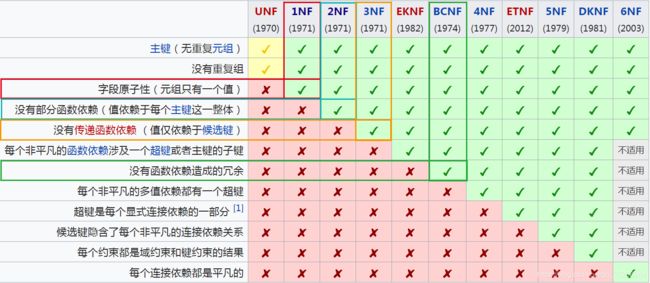
最常用的是1NF、2NF、3NF、(BCNF),这3或4类,下面将通过定义、反例这样的形式帮助大家理解这几类范式。
在讲解之前,还需要将相关的各种概念解释清楚:
表 4.2 学生表 Student
| Name | Sex | Age | Class | ID |
|---|---|---|---|---|
| Tim | 男 | 20 | 一班 | 610124199810202022 |
| Jerry | 男 | 21 | 二班 | 610124199710202100 |
- 实体(Entity)/关系(Relation):现实世界客观存在且可以区分的对象或事物。
如:学生、教师、课程、班级
(对应到数据库中,实体往往指某类事物的集合,也就是数据库表,Table) - 属性(Attribute):实体所具有的特性(对应到数据库,就是 1列)
- 元组(Tuple):表的 一行 就是一个元组
- 分量:元组中的一个属性值。如表4.2中,Student第一个元组对应Name属性的分量是“Tim”
- 域(Domain):属性的取值范围。如:年龄为0-99岁。
- 码(Key)/键(Key)/关键字(Key):由一个或多个属性组成的可以 唯一标识一行 的属性组
- 主键(Primary Key):表中的某个或某组属性,能唯一确定一个元组(1行)
- 外键(Foreign Key):表(关系)中的一个属性或一组属性,是别的表(关系)中的属性,它便是外键(外码)
- 元数:关系模型中,属性的个数。如:表4.2,学生表是一个5元关系表。
- 关系模式:对关系(表)的描述。一个关系模式对应一个关系结构。一般表示为:关系名(属性1,属性2……,属性n)。如:表4.2可以描述为 学生(Name,Sex,Age,Class,ID)。
- 全码(键):一个码包含了所有的属性,就是全码。
- 主属性:候选键中的属性为主属性
- 非主属性:不在候选键中的属性为非主属性
- 超键:除包含一个候选键外,还可以包含其他属性
- 候选码(键):能唯一标识一个元组,并且不含多余属性的属性组。
- 主键:从若干个候选键中指定一个作为主键
| 学号 | 宿舍号 | 住宿费用 |
|---|---|---|
| 001 | A | 900 |
| 002 | B | 1500 |
| 003 | B | 1500 |
学号确定宿舍、宿舍确定费用,且有学号不包含宿舍,宿舍不确定学号,符合传递函数依赖条件。
在以上关系R中,存在添加异常(新建个C宿舍,但是没人住无法添加了)删除异常(学生001退学了宿舍A也就删除掉了)如果存在传递函数依赖,可以拆分为:
| 学号 | 宿舍号 |
|---|---|
| 001 | A |
| 002 | B |
| 003 | B |
| 宿舍号 | 费用 |
|---|---|
| A | 900 |
| B | 1500 |
4.1 第一范式(1NF): 列的原子性(同一列不能有多个值)
正例: 表4.3——学生和课程的关系
| Name | Course |
|---|---|
| Jim | History |
| Jim | Math |
| Jim | Chinese |
| Alice | English |
| Tom | History |
| Tom | Math |
反例1: 单一字段存放了多个值,违反了1NF,Jim现在到底上的哪门课呢?
| **Name | Course |
|---|---|
| Jim | History,Math,Chinese |
| Alice | English |
| Tom | History,Math |
反例2: 多个字段表达同一个意思,这也是不符合1NF的。
| Name | Course1 | Course2 | Course3 |
|---|---|---|---|
| Jim | History | Math | Chinese |
| Alice | English | ||
| Tom | History | Math |
4.2 第二范式(2NF):消除了非主属性对于码的部分函数依赖(满足1NF且非主键列都完全函数依赖于主键)
通俗点讲,①必须满足1NF②必须有一个主键,且没有包含在主键中的列必须完全依赖于主键,而不能只依赖主键的一部分
举个例子:
| Name | Course | Score |
|---|---|---|
| Tim | Chinese | 70 |
| Tim | Math | 90 |
| Alice | Chinese | 80 |
| Juliea | Math | 80 |
在这张成绩表中,首先满足了1NF,列的原子性。其次,必须有主键,显而易见,(Name+Course)才能唯一确定一个元组,因此,Name+Course为联合主键。Score只有通过Name+Course才能共同确定,仅仅通过Name或Course是不行的。以y=f(x)为例,即,Score=f(Name+Course),Score不能只依赖Name或Course。
4.3 第三范式(3NF):消除了非主属性对于码的传递函数依赖(满足2NF且非主属性列都不传递依赖于主键)
通俗点讲,3NF必须满足,①满足2NF②不能有传递的依赖关系。换句话说,表中的每一列和主键直接相关,不能是间接相关的。再换句话说,通过主键就能直接定位到每一列,而不能是间接才能定位到
举个例子:
| 订单编号 | 订单项目 | 客户ID | 客户名称 |
|---|---|---|---|
| 001 | 水果 | 101 | 张三 |
| 002 | 饮料 | 101 | 张三 |
在这个表中,通过订单编号能确定订单项目名称,如001能确定是水果;
通过订单编号,能确定客户ID,通过客户ID能确定客户名称,当存在这种情况即存在传递依赖时,这个表就不满足3NF了,需要拆分。
可以拆分为:
| 订单编号 | 订单项目 | 客户ID |
|---|---|---|
| 001 | 水果 | 101 |
| 002 | 饮料 | 101 |
| 客户ID | 客户名称 |
|---|---|
| 101 | 张三 |
4.4 BCNF:消除了主属性对于码的部分函数依赖和传递函数依赖(即满足3NF,并且主属性之间没有依赖关系)
通俗点讲,①满足3NF②主属性之间没有依赖关系。
Tips:
3NF和BCNF是在函数依赖的条件下对模式分解所能达到的最大程度。
3NF可能存在主属性对键的部分依赖和传递依赖。
一个模式中的关系模式如果都属于BCNF,
那么在函数依赖范围内,已经实现了彻底的分离,已消除了插入异常和删除异常。
后记:
关于理论性、概念性知识,是比较抽象的,文章使用了学术定义结合通俗描述及实例的方法,讲解了数据库规范化相关知识,侧重点是范式,希望可以帮到各位读者对概念的理解。
如在阅读过程中检查到错、别字,或内容方面的错误,还请提出宝贵意见,以便修改。