Apache Hadoop 3.x 最新状态以及升级指南
本文来自 2019年9月23日至26日在纽约举办的 Strata Data Conference,分享者是来自 Cloudera 的 Wangda Tan 和 Wei-Chiu Chuang,会议页面 https://conferences.oreilly.com/strata/strata-ny-2019/public/schedule/detail/77506。
请关注 过往记忆大数据 微信公众号,并在后台回复 hadoop_3 关键字获取本文的 PPT 下载地址。

首先我们来看看 Hadoop 社区的最新情况
在刚刚过去的 2019,外界有很多声音都在说 Hadoop 已死,这是事实还是谎言?
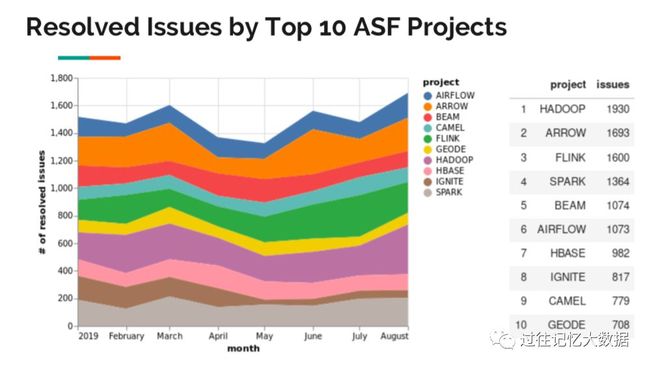
我们以数据来说明吧,上面是截止到 2019年08月 Apache 基金会解决 ISSUE 最多的前十个项目。我们从上图可以看出,Hadoop 项目排在第一位。
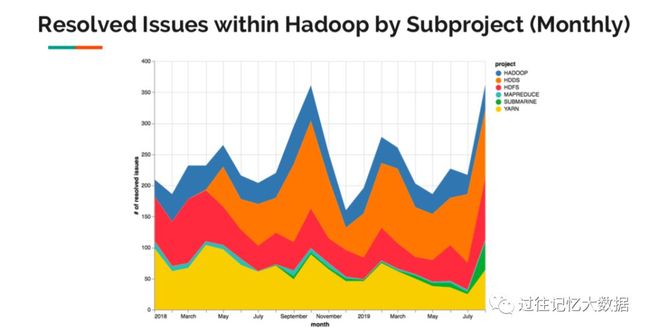
上图是 Hadoop 内部各个子项目的活跃情况,可以看出,Hadoop 项目仍然非常活跃。

上面是 Hadoop 项目在过去13年解决 ISSUE 的个数,可以看出,经过这么多年,Hadoop 社区解决的 ISSUE 并没有减少。
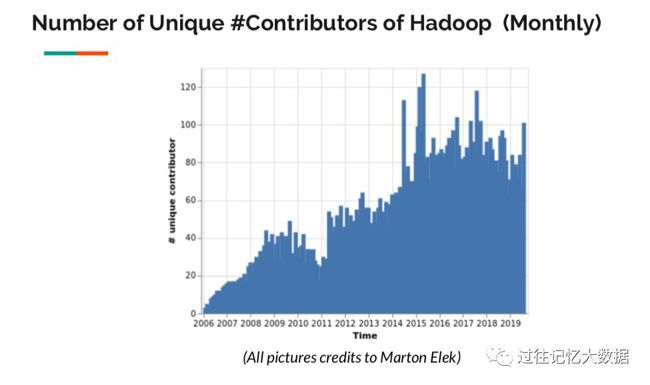
我们再看看 Hadoop Contributors 的趋势,可以看出,Contributors 人数在过去5年并没有减少。
所以说,Hadoop 项目本身其实并没有死,相反,Hadoop 项目还非常活跃。我们也可以看下过往记忆大数据之前关于反驳 Hadoop 已死言论的文章:Hadoop 气数已尽?

好了,说了这么久,我们先来简单的看下 Hadoop 3.x 。
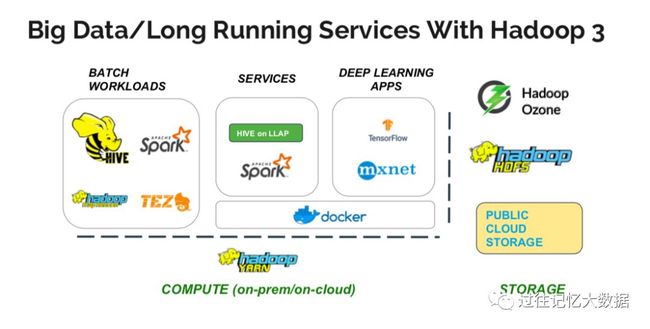
当前的 Hadoop 已经可以很好的支持大数据已经长时间运行的服务了。
Hadoop 3.x 现在更加的关注可扩展性、容器化、成本、云原生以及机器学习这些主题了。

我们再来看看 YARN 模块:

YARN 目前更加关注容器化了,在 Apache Hadoop 3.1.0 已经支持生产级别的 Docker 容器支持了,Hadoop 3.3.0 支持 Docker shell 交互式;

YARN 目前也在支持云原生环境,主要包括自动扩展、智能调度以及减少节点等。

Hadoop 3.0.0 也增强了 YARN 的调度能力。

其他的一些增强包括,比如 3.2.0 版本支持节点属性,所以我们可以基于属性去调度 Container。3.1.0 的放置约束(Placement Constraint)、动态创建队列等。

第二个模块是 Submarine。

很多人可能对 Submarine 并不了解,Submarine 是 Hadoop 的一个全新的模块,2018年开始开发的,它是机器学习的解决方案。充分利用 Hadoop 的 GPU/Docker 特性,运行数据科学家在 Hadoop 上运行深度学习的应用。关于 Submarine 的更多介绍,可以参考过往记忆大数据很早之前的 {Submarine} 在 Apache Hadoop 中运行深度学习框架 文章。

在 0.3.0版本,Submarine 带来了很多新功能,如上描述。

在生产环境使用 Hadoop Submarine 的公司主要有网易、领英以及贝壳网等。

好了,现在我们来看看 Hadoop 的第三大模块,存储。
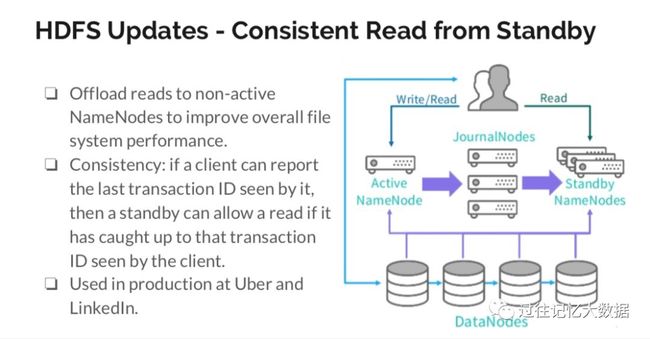
从Standby NN读取数据现在可以做到一致性了,我们可以通过读取 Standby NN 来提升整体系统的性能。如果某个客户端已经拿到了某个 transaction ID,并且 Standby NN 已经同步过这个 transaction ID 的数据,那么Standby NN就允许这个客户端读取这个 transaction ID 的数据。这个功能在优步和领英的生成环境上使用了。

基于路由的 Federation 也有了很大的改进,比如支持安全方面的需求,可扩展性以及对慢子集群的处理。关于基于路由的 Federation可以进一步看下过往记忆大数据之前的文章 Apache Hadoop 的 HDFS federation 前世今生。

HDFS 的其他一些比较重要的特性

云连接器相关的更新。

ABFS 是 Azure Blob FileSystem 的简称,是 Azure 的适用于云的对象存储解决方案。Azure Data Lake Storage Gen2 是一组专用于大数据分析的功能,以 Azure Blob 存储为基础而构建。Hadoop 3.2.0 目前支持连接 Azure Data Lake Storage Gen2。3.2.1 版本更加稳定了。

Hadoop 第四大模块是 Hadoop common。

这个模块正在做的事情包括:TLS 支持 RPC、支持JDK 11等。

最后我们来看看 Hadoop 的 Ozone 模块

Ozone是专门为Hadoop设计的可扩展的分布式对象存储系统。主要由 Hortonworks/Cloudera/Tencent 贡献,过去一年取得了重大进步。



Hadoop 版本发行计划。

Submarine 版本发行计划

Hadoop 3.0.x、Hadoop 2.7.x 及以下版本已经不再支持了。

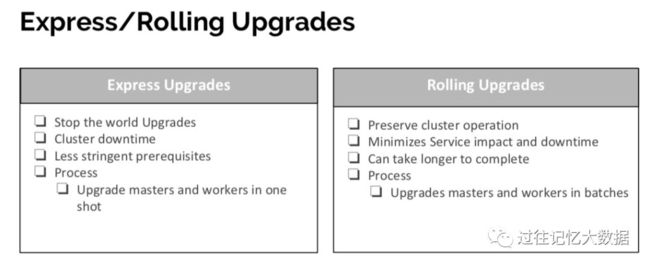
Hadoop 升级方式有两种:Express 和 Rolling,Express 升级过程是停止现有服务,然后使用新版本启动服务;Rolling 升级过程是滚动升级,不停服务,对用户无感知。

大版本的滚动升级存在一些挑战和问题,目前社区对不停机升级集群做了大量的工作,这个工作很快会在最新的 Hadoop 版本一起发布。Hadoop 2升级到3目前推荐使用 Express 升级。不过,滴滴在前段时间发布了其 Hadoop 集群从2不停机升级到3的实践,参见过往记忆大数据的 Hadoop 2.7 不停服升级到 3.2 在滴滴的实践 这篇文章。

兼容性方面 Hadoop 2 客户端的兼容性依然保持,另外 Distcp/WebHDFS 的兼容性也支持。
标记为遗弃的 API 和工具已经被移除了,大量重写 Shell 脚本等。

建议大家使用 Apache Hadoop 2.8.x 来升级到 Apache Hadoop 3.1.x。因为大多数公司生产环境部署了 Apache Hadoop 2.8.x。如果你的 Hadoop 版本为 2.6.x 或者 2.7.x,建议在升级之前多做校验。不过我们也看到有人直接将 Hadoop 2.7.x 升级到 3.x。

升级的其他相关文档可以参见 https://dataworkssummit.com/san-jose-2018/session/ease-of-migration-from-hadoop-2-to-hadoop-3-clusters/。

已经有很多公司升级到 Hadoop 3.x 了。

关于 Hadoop 3.x 升级的事情:Hadoop 3 有很多新特性和优化(具体参见过往记忆大数据之前的 Apache Hadoop 3.0.0 GA版正式发布,可以部署到线上 、Apache Hadoop 3.1.0 正式发布,原生支持GPU和FPGA 文章)。很多企业在生产环境中使用了 Hadoop 3;推荐使用 Express 升级;如果你还没有升级,那赶紧来升级吧。
猜你喜欢
1、过往记忆大数据,2019年原创精选69篇
2、还在玩数据仓库?现在已经是 LakeHouse 时代!
3、爱奇艺大数据实时分析平台的建设与实践
4、Apache Kylin 在一点资讯的实践

过往记忆大数据微信群,请添加微信:fangzhen0219,备注【进群】