看完这篇,你也可以实现一个360度全景插件
导读
本文从绘图基础开始讲起,详细介绍了如何使用 Three.js开发一个功能齐全的全景插件。
我们先来看一下插件的效果:
如果你对 Three.js已经很熟悉了,或者你想跳过基础理论,那么你可以直接从全景预览开始看起。
本项目的 github地址:https://github.com/ConardLi/tpanorama

一、理清关系
1.1 OpenGL

OpenGL是用于渲染 2D、3D量图形的跨语言、跨平台的应用程序编程接口 (API)。
这个接口由近 350个不同的函数调用组成,用来从简单的图形比特绘制复杂的三维景象。
OpenGLES 是 OpenGL三维图形 API的子集,针对手机、 PDA和游戏主机等嵌入式设备而设计。
基于 OpenGL,一般使用 C或 Cpp开发,对前端开发者来说不是很友好。
1.2 WebGL
WebGL把 JavaScript和 OpenGLES2.0结合在一起,从而为前端开发者提供了使用 JavaScript编写 3D效果的能力。
WebGL为 HTML5Canvas提供硬件 3D加速渲染,这样 Web开发人员就可以借助系统显卡来在浏览器里更流畅地展示 3D场景和模型了,还能创建复杂的导航和数据视觉化。
1.3 Canvas
Canvas是一个可以自由制定大小的矩形区域,可以通过 JavaScript可以对矩形区域进行操作,可以自由的绘制图形,文字等。
一般使用 Canvas都是使用它的 2d的 context功能,进行 2d绘图,这是其本身的能力。
和这个相对的, WebGL是三维,可以描画 3D图形, WebGL,想要在浏览器上进行呈现,它必须需要一个载体,这个载体就是 Canvas,区别于之前的 2dcontext,还可以从 Canvas中获取 webglcontext。
1.4 Three.js

我们先来从字面意思理解下:Three代表 3D, js代表 JavaScript,即使用 JavaScript来开发 3D效果。
Three.js是使用 JavaScript对 WebGL接口进行封装与简化而形成的一个易用的 3D库。
直接使用 WebGL进行开发对于开发者来说成本相对来说是比较高的,它需要你掌握较多的计算机图形学知识。
Three.js在一定程度上简化了一些规范和难以理解的概念,对很多 API进行了简化,这大大降低了学习和开发三维效果成本。
下面我们来具体看一下使用 Three.js必须要知道的知识。
二、Three.js基础知识
使用 Three.js绘制一个三维效果,至少需要以下几个步骤:
创建一个容纳三维空间的场景 —
Sence将需要绘制的元素加入到场景中,对元素的形状、材料、阴影等进行设置
给定一个观察场景的位置,以及观察角度,我们用相机对象(
Camera)来控制将绘制好的元素使用渲染器(
Renderer)进行渲染,最终呈现在浏览器上
拿电影来类比的话,场景对应于整个布景空间,相机是拍摄镜头,渲染器用来把拍摄好的场景转换成胶卷。
2.1 场景
场景允许你设置哪些对象被 three.js渲染以及渲染在哪里。
我们在场景中放置对象、灯光和相机。
很简单,直接创建一个 Scene的实例即可。
_scene = new Scene();2.2 元素
有了场景,我们接下来就需要场景里应该展示哪些东西。

一个复杂的三维场景往往就是由非常多的元素搭建起来的,这些元素可能是一些自定义的几何体( Geometry),或者外部导入的复杂模型。
Three.js 为我们提供了非常多的 Geometry,例如 SphereGeometry(球体)、 TetrahedronGeometry(四面体)、 TorusGeometry(圆环体)等等。
在 Three.js中,材质( Material)决定了几何图形具体是以什么形式展现的。它包括了一个几何体如何形状以外的其他属性,例如色彩、纹理、透明度等等, Material和 Geometry是相辅相成的,必须结合使用。
下面的代码我们创建了一个长方体体,赋予它基础网孔材料( MeshBasicMaterial)
var geometry = new THREE.BoxGeometry(200, 100, 100);
var material = new THREE.MeshBasicMaterial({ color: 0x645d50 });
var mesh = new THREE.Mesh(geometry, material);
_scene.add(mesh);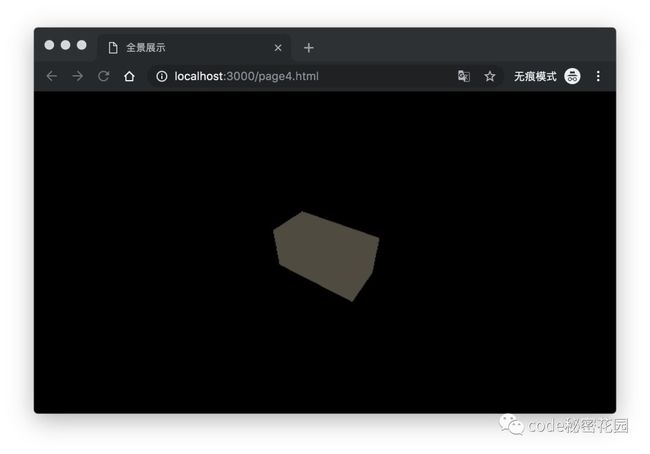
能以这个角度看到几何体实际上是相机的功劳,这个我们下面的章节再介绍,这让我们看到一个几何体的轮廓,但是感觉怪怪的,这并不像一个几何体,实际上我们还需要为它添加光照和阴影,这会让几何体看起来更真实。
基础网孔材料( MeshBasicMaterial)不受光照影响的,它不会产生阴影,下面我们为几何体换一种受光照影响的材料:网格标准材质( StandardMaterial),并为它添加一些光照:
var geometry = new THREE.BoxGeometry(200, 100, 100);
var material = new THREE.MeshStandardMaterial({ color: 0x645d50 });
var mesh = new THREE.Mesh(geometry, material);
_scene.add(mesh);
// 创建平行光-照亮几何体
var directionalLight = new THREE.DirectionalLight(0xffffff, 1);
directionalLight.position.set(-4, 8, 12);
_scene.add(directionalLight);
// 创建环境光
var ambientLight = new THREE.AmbientLight(0xffffff);
_scene.add(ambientLight);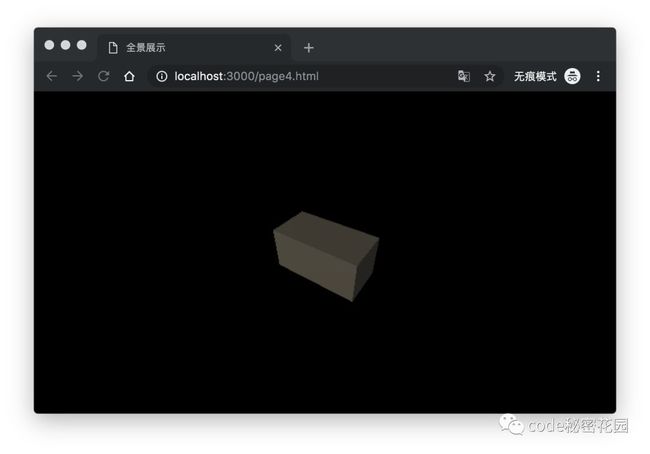
有了光线的渲染,让几何体看起来更具有 3D效果, Three.js中光源有很多种,我们上面使用了环境光( AmbientLight)和平行光( DirectionalLight)。
环境光会对场景中的所有物品进行颜色渲染。
平行光你可以认为像太阳光一样,从极远处射向场景中的光。它具有方向性,也可以启动物体对光的反射效果。
除了这两种光, Three.js还提供了其他几种光源,它们适用于不同情况下对不同材质的渲染,可以根据实际情况选择。
2.3 坐标系
在说相机之前,我们还是先来了解一下坐标系的概念:
在三维世界中,坐标定义了一个元素所处于三维空间的位置,坐标系的原点即坐标的基准点。
最常用的,我们使用距离原点的三个长度(距离 x轴、距离 y轴、距离 z轴)来定义一个位置,这就是直角坐标系。
在判定坐标系时,我们通常使用大拇指、食指和中指,并互为 90度。大拇指代表 X轴,食指代表 Y轴,中指代表 Z轴。
这就产生了两种坐标系:左手坐标系和右手坐标系。
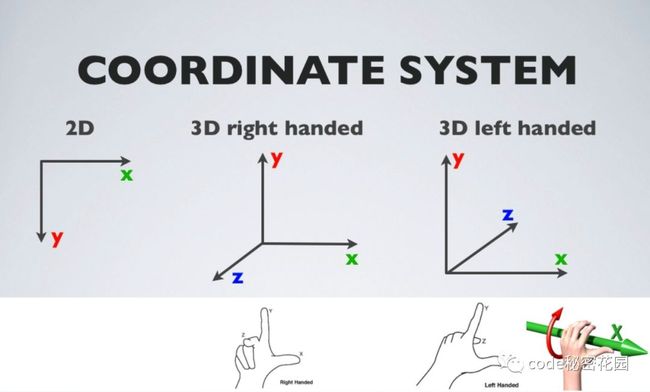
Three.js中使用的坐标系即右手坐标系。
我们可以在我们的场景中添加一个坐标系,这样我们可以清楚的看到元素处于什么位置:
var axisHelper = new THREE.AxisHelper(600);
_scene.add(axisHelper);
其中红色代表 X轴,绿色代表 Y轴,蓝色代表 Z轴。
2.4 相机
上面看到的几何体的效果,如果不创建一个相机( Camera),是什么也看不到的,因为默认的观察点在坐标轴原点,它处于几何体的内部。
相机( Camera)指定了我们在什么位置观察这个三维场景,以及以什么样的角度进行观察。
2.4.1 两种相机的区别
目前 Three.js提供了几种不同的相机,最常用的,也是下面插件中使用的两种相机是:PerspectiveCamera(透视相机)、 OrthographicCamera(正交投影相机)。

上面的图很清楚的解释了两种相机的区别:
右侧是 OrthographicCamera(正交投影相机)他不具有透视效果,即物体的大小不受远近距离的影响,对应的是投影中的正交投影。我们数学课本上所画的几何体大多数都采用这种投影。
左侧是 PerspectiveCamera(透视相机),这符合我们正常人的视野,近大远小,对应的是投影中的透视投影。
如果你想让场景看起来更真实,更具有立体感,那么采用透视相机最合适,如果场景中有一些元素你不想让他随着远近放大缩小,那么采用正交投影相机最合适。
2.4.2 构造参数
我们再分别来看看两个创建两个相机需要什么参数:
_camera = new OrthographicCamera(left, right, top, bottom, near, far);
OrthographicCamera接收六个参数, left,right,top,bottom分别对应上、下、左、右、远、近的一个距离,超过这些距离的元素将不会出现在视野范围内,也不会被浏览器绘制。实际上,这六个距离就构成了一个立方体,所以 OrthographicCamera的可视范围永远在这个立方体内。
_camera = new PerspectiveCamera(fov, aspect, near, far);
PerspectiveCamera接收四个参数, near、 far和上面的相同,分别对应相机可观测的最远和最近距离;fov代表水平范围可观测的角度, fov越大,水平范围能观测到的范围越广;aspect代表水平方向和竖直方向可观测距离的比值,所以 fov和 aspect就可以确定垂直范围内能观测到的范围。
2.4.3 position、lookAt
关于相机还有两个必须要知道的点,一个是 position属性,一个是 lookAt函数:
position属性指定了相机所处的位置。
lookAt函数指定相机观察的方向。
实际上 position的值和 lookAt接收的参数都是一个类型为 Vector3的对象,这个对象用来表示三维空间中的坐标,它有三个属性:x、y、z分别代表距离 x轴、距离 y轴、距离 z轴的距离。
下面,我们让相机观察的方向指向原点,另外分别让 x、y、z为0,另外两个参数不为0,看一下视野会发生什么变化:
_camera = new OrthographicCamera(-window.innerWidth / 2, window.innerWidth / 2, window.innerHeight / 2, -window.innerHeight / 2, 0.1, 1000);
_camera.lookAt(new THREE.Vector3(0, 0, 0))
_camera.position.set(0, 300, 600); // 1 - x为0
_camera.position.set(500, 0, 600); // 2 - y为0
_camera.position.set(500, 300, 0); // 3 - z为0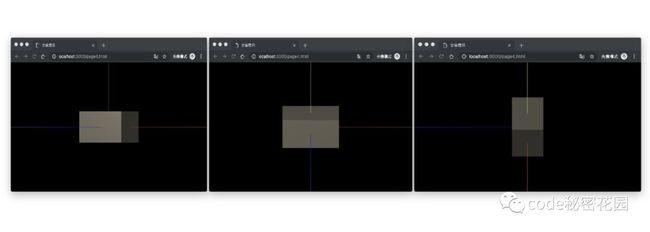
很清楚的看到 position决定了我们视野的出发点,但是镜头指向的方向是不变的。
下面我们将 position固定,改变相机观察的方向:
_camera = new OrthographicCamera(-window.innerWidth / 2, window.innerWidth / 2, window.innerHeight / 2, -window.innerHeight / 2, 0.1, 1000);
_camera.position.set(500, 300, 600);
_camera.lookAt(new THREE.Vector3(0, 0, 0)) // 1 - 视野指向原点
_camera.lookAt(new THREE.Vector3(200, 0, 0)) // 2 - 视野偏向x轴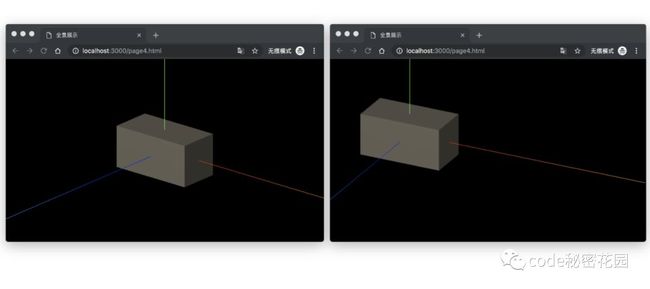
可见:我们视野的出发点是相同的,但是视野看向的方向发生了改变。
2.4.4 两种相机对比
好,有了上面的基础,我们再来写两个例子看一看两个相机的视角对比,为了方便观看,我们创建两个位置不同的几何体:
var geometry = new THREE.BoxGeometry(200, 100, 100);
var material = new THREE.MeshStandardMaterial({ color: 0x645d50 });
var mesh = new THREE.Mesh(geometry, material);
_scene.add(mesh);
var geometry = new THREE.SphereGeometry(50, 100, 100);
var ball = new THREE.Mesh(geometry, material);
ball.position.set(200, 0, -200);
_scene.add(ball);正交投影相机视野:
_camera = new OrthographicCamera(-window.innerWidth / 2, window.innerWidth / 2, window.innerHeight / 2, -window.innerHeight / 2, 0.1, 1000);
_camera.position.set(0, 300, 600);
_camera.lookAt(new THREE.Vector3(0, 0, 0))
透视相机视野:
_camera = new PerspectiveCamera(75, window.innerWidth / window.innerHeight, 0.1, 1100);
_camera.position.set(0, 300, 600);
_camera.lookAt(new THREE.Vector3(0, 0, 0))
可见,这印证了我们上面关于两种相机的理论
2.5 渲染器
上面我们创建了场景、元素和相机,下面我们要告诉浏览器将这些东西渲染到浏览器上。
Three.js也为我们提供了几种不同的渲染器,这里我们主要看 WebGL渲染器( WebGLRenderer)。顾名思义:WebGL渲染器使用 WebGL来绘制场景,其够利用 GPU硬件加速从而提高渲染性能。
_renderer = new THREE.WebGLRenderer();你需要将你使用 Three.js绘制的元素添加到浏览器上,这个过程需要一个载体,上面我们介绍,这个载体就是 Canvas,你可以通过 _renderer.domElement获取到这个 Canvas,并将它给定到真实 DOM中。
_container = document.getElementById('conianer');
_container.appendChild(_renderer.domElement);使用 setSize函数设定你要渲染的范围,实际上它改变的就是上面 Canvas的范围:
_renderer.setSize(window.innerWidth, window.innerHeight);现在,你已经指定了一个渲染的载体和载体的范围,你可以通过 render函数渲染上面指定的场景和相机:
_renderer.render(_scene, _camera);实际上,你如果依次执行上面的代码,可能屏幕上还是黑漆漆的一片,并没有任何元素渲染出来。
这是因为上面你要渲染的元素可能并未被加载完,你就执行了渲染,并且只执行了一次,这时我们需要一种方法,让场景和相机进行实时渲染,我们需要用到下面的方法:
2.6 requestAnimationFrame
window.requestAnimationFrame()告诉浏览器——你希望执行一个动画,并且要求浏览器在下次重绘之前调用指定的回调函数更新动画。
该方法需要传入一个回调函数作为参数,该回调函数会在浏览器下一次重绘之前执行。
window.requestAnimationFrame(callback);若你想在浏览器下次重绘之前继续更新下一帧动画,那么回调函数自身必须再次调用 window.requestAnimationFrame()。
使用者韩函数就意味着,你可以在 requestAnimationFrame不停的执行绘制操作,浏览器就实时的知道它需要渲染的内容。
当然,某些时候你已经不需要实时绘制了,你也可以使用 cancelAnimationFrame立即停止这个绘制:
window.cancelAnimationFrame(myReq);来看一个简单的例子:
var i = 0;
var animateName;
animate();
function animate() {
animateName = requestAnimationFrame(animate);
console.log(i++);
if (i > 100) {
cancelAnimationFrame(animateName);
}
}来看一下执行效果:

我们使用 requestAnimationFrame和 Three.js的渲染器结合使用,这样就能实时绘制三维动画了:
function animate() {
requestAnimationFrame(animate);
_renderer.render(_scene, _camera);
}借助上面的代码,我们可以简单实现一些动画效果:
var y = 100;
var option = 'down';
function animateIn() {
animateName = requestAnimationFrame(animateIn);
mesh.rotateX(Math.PI / 40);
if (option == 'up') {
ball.position.set(200, y += 8, 0);
} else {
ball.position.set(200, y -= 8, 0);
}
if (y < 1) { option = 'up'; }
if (y > 100) { option = 'down' }
}
2.7 总结
上面的知识是 Three.js中最基础的知识,也是最重要的和最主干的。
这些知识能够让你在看到一个复杂的三维效果时有一定的思路,当然,要实现还需要非常多的细节。这些细节你可以去官方文档中查阅。
下面的章节即告诉你如何使用 Three.js进行实战 — 实现一个360度全景插件。
这个插件包括两部分,第一部分是对全景图进行预览。
第二部分是对全景图的标记进行配置,并关联预览的坐标。
我们首先来看看全景预览部分:
三、全景预览
3.1 基本逻辑
将一张全景图包裹在球体的内壁
设定一个观察点,在球的圆心
使用鼠标可以拖动球体,从而改变我们看到全景的视野
鼠标滚轮可以缩放,和放大,改变观察全景的远近
根据坐标在全景图上挂载一些标记,如文字、图标等,并且可以增加事件,如点击事件
3.2 初始化
我们先把必要的基础设施搭建起来:
场景、相机(选择远景相机,这样可以让全景看起来更真实)、渲染器:
_scene = new THREE.Scene();
initCamera();
initRenderer();
animate();
// 初始化相机
function initCamera() {
_camera = new THREE.PerspectiveCamera(75, window.innerWidth / window.innerHeight, 0.1, 1100);
_camera.position.set(0, 0, 2000);
_camera.lookAt(new THREE.Vector3(0, 0, 0));
}
// 初始化渲染器
function initRenderer() {
_renderer = new THREE.WebGLRenderer();
_renderer.setSize(window.innerWidth, window.innerHeight);
_container = document.getElementById('panoramaConianer');
_container.appendChild(_renderer.domElement);
}
// 实时渲染
function animate() {
requestAnimationFrame(animate);
_renderer.render(_scene, _camera);
}下面我们在场景内添加一个球体,并把全景图作为材料包裹在球体上面:
var mesh = new THREE.Mesh(new THREE.SphereGeometry(1000, 100, 100),
new THREE.MeshBasicMaterial(
{ map: ImageUtils.loadTexture('img/p3.png') }
));
_scene.add(mesh);然后我们看到的场景应该是这样的:

这不是我们想要的效果,我们想要的是从球的内部观察全景,并且全景图是附着外球的内壁的,而不是铺在外面:
我们只要需将 Material的 scale的一个属性设置为负值,材料即可附着在几何体的内部:
mesh.scale.x = -1;然后我们将相机的中心点移动到球的中心:
_camera.position.set(0, 0, 0);现在我们已经在全景球的内部啦:

3.3 事件处理
全景图已经可以浏览了,但是你只能看到你眼前的这一块,并不能拖动它看到其他部分,为了精确的控制拖动的速度和缩放、放大等场景,我们手动为它增加一些事件:
监听鼠标的 mousedown事件,在此时将开始拖动标记 _isUserInteracting设置为 true,并且记录起始的屏幕坐标,以及起始的相机 lookAt的坐标。
_container.addEventListener('mousedown', (event)=>{
event.preventDefault();
_isUserInteracting = true;
_onPointerDownPointerX = event.clientX;
_onPointerDownPointerY = event.clientY;
_onPointerDownLon = _lon;
_onPointerDownLat = _lat;
});监听鼠标的 mousemove事件,当 _isUserInteracting为 true时,实时计算当前相机 lookAt的真实坐标。
_container.addEventListener('mousemove', (event)=>{
if (_isUserInteracting) {
_lon = (_onPointerDownPointerX - event.clientX) * 0.1 + _onPointerDownLon;
_lat = (event.clientY - _onPointerDownPointerY) * 0.1 + _onPointerDownLat;
}
});监听鼠标的 mouseup事件,将 _isUserInteracting设置为 false。
_container.addEventListener('mouseup', (event)=>{
_isUserInteracting = false;
});当然,上面我们只是改变了坐标,并没有告诉相机它改变了,我们在 animate函数中来做这件事:
function animate() {
requestAnimationFrame(animate);
calPosition();
_renderer.render(_scene, _camera);
_renderer.render(_sceneOrtho, _cameraOrtho);
}
function calPosition() {
_lat = Math.max(-85, Math.min(85, _lat));
var phi = tMath.degToRad(90 - _lat);
var theta = tMath.degToRad(_lon);
_camera.target.x = _pRadius * Math.sin(phi) * Math.cos(theta);
_camera.target.y = _pRadius * Math.cos(phi);
_camera.target.z = _pRadius * Math.sin(phi) * Math.sin(theta);
_camera.lookAt(_camera.target);
}监听 mousewheel事件,对全景图进行放大和缩小,注意这里指定了最大缩放范围 maxFocalLength和最小缩放范围 minFocalLength。
_container.addEventListener('mousewheel', (event)=>{
var ev = ev || window.event;
var down = true;
var m = _camera.getFocalLength();
down = ev.wheelDelta ? ev.wheelDelta < 0 : ev.detail > 0;
if (down) {
if (m > minFocalLength) {
m -= m * 0.05
_camera.setFocalLength(m);
}
} else {
if (m < maxFocalLength) {
m += m * 0.05
_camera.setFocalLength(m);
}
}
});来看一下效果吧:
3.4 增加标记
在浏览全景图的时候,我们往往需要对某些特殊的位置进行一些标记,并且这些标记可能附带一些事件,比如你需要点击一个标记才能到达下一张全景图。
下面我们来看看如何在全景中增加标记,以及如何为这些标记添加事件。
我们可能不需要让这些标记随着视野的变化而放大和缩小,基于此,我们使用正交投影相机来展现标记,只需给它一个固定的观察高度:
_cameraOrtho = new THREE.OrthographicCamera(-window.innerWidth / 2, window.innerWidth / 2, window.innerHeight / 2, -window.innerHeight / 2, 1, 10);
_cameraOrtho.position.z = 10;
_sceneOrtho = new Scene();利用精灵材料( SpriteMaterial)来实现文字标记,或者图片标记:
// 创建文字标记
function createLableSprite(name) {
const canvas = document.createElement('canvas');
const context = canvas.getContext('2d');
const metrics = context.measureText(name);
const width = metrics.width * 1.5;
context.font = "10px 宋体";
context.fillStyle = "rgba(0,0,0,0.95)";
context.fillRect(2, 2, width + 4, 20 + 4);
context.fillText(name, 4, 20);
const texture = new Texture(canvas);
const spriteMaterial = new SpriteMaterial({ map: texture });
const sprite = new Sprite(spriteMaterial);
sprite.name = name;
const lable = {
name: name,
canvas: canvas,
context: context,
texture: texture,
sprite: sprite
};
_sceneOrtho.add(lable.sprite);
return lable;
}
// 创建图片标记
function createSprite(position, url, name) {
const textureLoader = new TextureLoader();
const ballMaterial = new SpriteMaterial({
map: textureLoader.load(url)
});
const sp = {
pos: position,
name: name,
sprite: new Sprite(ballMaterial)
};
sp.sprite.scale.set(32, 32, 1.0);
sp.sprite.name = name;
_sceneOrtho.add(sp.sprite);
return sp;
}创建好这些标记,我们把它渲染到场景中。
我们必须告诉场景这些标记的位置,为了直观的理解,我们需要给这些标记赋予一种坐标,这种坐标很类似于经纬度,我们叫它 lon和 lat,具体是如何给定的我们在下面的章节:全景标记中会详细介绍。
在这个过程中,一共经历了两次坐标转换:
第一次转换:将“经纬度”转换为三维空间坐标,即我们上面讲的那种 x、y、z形式的坐标。
使用 geoPosition2World函数进行转换,得到一个 Vector3对象,我们可以将当前相机 _camera作为参数传入这个对象的 project方法,这会得到一个标准化后的坐标,基于这个坐标可以帮我们判断标记是否在视野范围内,如下面的代码,若标准化坐标在 -1和 1的范围内,则它会出现在我们的视野中,我们将它进行准确渲染。
第二次转换:将三维空间坐标转换为屏幕坐标。
如果我们直接讲上面的三维空间坐标坐标应用到标记中,我们会发现无论视野如何移动,标记的位置是不会有任何变化的,因为这样算出来的坐标永远是一个常量。
所以我们需要借助上面的标准化坐标,将标记的三维空间坐标转换为真实的屏幕坐标,这个过程是 worldPostion2Screen函数来实现的。
关于 geoPosition2World和 worldPostion2Screen两个函数的实现,大家有兴趣可以去我的 github源码中查看,这里就不多做解释了,因为这又要牵扯到一大堆专业知识啦。?
var wp = geoPosition2World(_sprites.lon, _sprites.lat);
var sp = worldPostion2Screen(wp, _camera);
var test = wp.clone();
test.project(_camera);
if (test.x > -1 && test.x < 1 && test.y > -1 && test.y < 1 && test.z > -1 && test.z < 1) {
_sprites[i].sprite.scale.set(32, 32, 32);
_sprites[i].sprite.position.set(sp.x, sp.y, 1);
}else {
_sprites[i].sprite.scale.set(1.0, 1.0, 1.0);
_sprites[i].sprite.position.set(0, 0, 0);
}
现在,标记已经添加到全景上面了,我们来为它添加一个点击事件:
Three.js并没有单独提供为 Sprite添加事件的方法,我们可以借助光线投射器( Raycaster)来实现。
Raycaster提供了鼠标拾取的能力:
通过 setFromCamera函数来建立当前点击的坐标(经过归一化处理)和相机的绑定关系。
通过 intersectObjects来判定一组对象中有哪些被命中(点击),得到被命中的对象数组。
这样,我们就可以获取到点击的对象,并基于它做一些处理:
_container.addEventListener('click', (event)=>{
_mouse.x = (event.clientX / window.innerWidth) * 2 - 1;
_mouse.y = -(event.clientY / window.innerHeight) * 2 + 1;
_raycaster.setFromCamera(_mouse, _cameraOrtho);
var intersects = _raycaster.intersectObjects(_clickableObjects);
intersects.forEach(function (element) {
alert("点击到了: " + element.object.name);
});
});点击到一个标记,进入到下一张全景图:
四、全景标记
为了让全景图知道,我要把标记标注在什么地方,我需要一个工具来把原图和全景图上的位置关联起来:
由于这部分代码和 Three.js关系不大,这里我只说一下基本的实现逻辑,有兴趣可以去我的 github仓库查看。
4.1 要求
建立坐标和全景的映射关系,为全景赋予一套虚拟坐标
在一张平铺的全景图上,可以在任意位置增加标记,并获取标记的坐标
使用坐标在预览全景增加标记,看到的标记位置和平铺全景中的位置相同
4.2 坐标
在 2D平面上,我们能监听屏幕的鼠标事件,我们可以获取的也只是当前的鼠标坐标,我们要做的是将鼠标坐标转换成三维空间坐标。
看起来好像是不可能的,二维坐标怎么能转换成三维坐标呢?
但是,我们可以借助一种中间坐标来转换,可以把它称之为“经纬度”。
在这之前,我们先来看看我们常说的经纬度到底是什么。
4.3 经纬度
使用经纬度,可以精确的定位到地球上任意一个点,它的计算规则是这样的:

通常把连接南极到北极的线叫做子午线也叫经线,其所对应的面叫做子午面,规定英国伦敦格林尼治天文台原址的那条经线称为0°经线,也叫本初子午线其对应的面即本初子午面。
经度:球面上某店对应的子午面与本初子午面间的夹角。东正西负。
纬度 :球面上某点的法线(以该店作为切点与球面相切的面的法线)与赤道平面的夹角。北正南负。
由此,地球上每一个点都能被对应到一个经度和纬度,想对应的,也能对应到某条经线和纬线上。
这样,即使把球面展开称平面,我们仍然能用经纬度表示某店点的位置:

4.4 坐标转换
基于上面的分析,我们完全可以给平面的全景图赋予一个虚拟的“经纬度”。我们使用 Canvas为它绘制一张"经纬网":

将鼠标坐标转换为"经纬度":
function calLonLat(e) {
var h = _setContainer.style.height.split("px")[0];
var w = _setContainer.style.width.split("px")[0];
var ix = _setContainer.offsetLeft;
var iy = _setContainer.offsetTop;
iy = iy + h;
var x = e.clientX;
var y = e.clientY;
var lonS = (x - ix) / w;
var lon = 0;
if (lonS > 0.5) {
lon = -(1 - lonS) * 360;
} else {
lon = 1 * 360 * lonS;
}
var latS = (iy - y) / h;
var lat = 0;
if (latS > 0.5) {
lat = (latS - 0.5) * 180;
} else {
lat = (0.5 - latS) * 180 * -1
}
lon = lon.toFixed(2);
lat = lat.toFixed(2);
return { lon: lon, lat: lat };
}这样平面地图上的某点就可以和三维坐标关联起来了,当然,这还需要一定的转换,有兴趣可以去源码研究下 geoPosition2World和 worldPostion2Screen两个函数。
五、插件封装
上面的代码中,我们实现了全景预览和全景标记的功能,下面,我们要把这些功能封装成插件。
所谓插件,即可以直接引用你写的代码,并添加少量的配置就可以实现想要的功能。
5.1 全景预览封装
我们来看看,究竟哪些配置是可以抽取出来的:
var options = {
container: 'panoramaConianer',
url: 'resources/img/panorama/pano-7.jpg',
lables: [],
widthSegments: 60,
heightSegments: 40,
pRadius: 1000,
minFocalLength: 1,
maxFocalLength: 100,
sprite: 'label',
onClick: () => { }
}container:dom容器的idurl:图片路径lables:全景中的标记数组,格式为{position:{lon:114,lat:38},logoUrl:'lableLogo.png',text:'name'}widthSegments:水平切段数heightSegments:垂直切段数(值小粗糙速度快,值大精细速度慢)pRadius:全景球的半径,推荐使用默认值minFocalLength:镜头最小拉近距离maxFocalLength:镜头最大拉近距离sprite:展示的标记类型label,icononClick:标记的点击事件
上面的配置是可以用户配置的,那么用户该如何传入插件呢?
我们可以在插件中声明一些默认配置 options,用户使用构造函数传入参数,然后使用 Object.assign将传入配置覆盖到默认配置。
接下来,你就可以使用 this.def来访问这些变量了,然后只需要把写死的代码改成这些配置即可。
options = {
// 默认配置...
}
function tpanorama(opt) {
this.render(opt);
}
tpanorama.prototype = {
constructor: this,
def: {},
render: function (opt) {
this.def = Object.assign(options, opt);
// 初始化操作...
}
}5.2 全景标记封装
基本逻辑和上面的类似,下面是提取出来的一些参数。
var setOpt = {
container: 'myDiv',//setting容器
imgUrl: 'resources/img/panorama/3.jpg',
width: '',//指定宽度,高度自适应
showGrid: true,//是否显示格网
showPosition: true,//是否显示经纬度提示
lableColor: '#9400D3',//标记颜色
gridColor: '#48D1CC',//格网颜色
lables: [],//标记 {lon:114,lat:38,text:'标记一'}
addLable: true,//开启后双击添加标记 (必须开启经纬度提示)
getLable: true,//开启后右键查询标记 (必须开启经纬度提示)
deleteLbale: true,//开启默认中键删除 (必须开启经纬度提示)
}六、发布
接下来,我们就好考虑如何将写好的插件让用户使用了。
我们主要考虑两种场景,直接引用和 npm install
6.1 直接引用 JS
为了不污染全局变量,我们使用一个自执行函数 (function(){}())将代码包起来,然后将我们写好的插件暴露给全局变量 window。
我把它放在 originSrc目录下。
(function (global, undefined) {
function tpanorama(opt) {
// ...
}
tpanorama.prototype = {
// ...
}
function tpanoramaSetting(opt) {
// ...
}
tpanoramaSetting.prototype = {
// ...
}
global.tpanorama = tpanorama;
global.tpanoramaSetting = panoramaSetting;
}(window))6.2 使用 npm install
直接将写好的插件导出:
module.exports = tpanorama;
module.exports = panoramaSetting;我把它放在 src目录下。
同时,我们要把 package.json中的 main属性指向我们要导出的文件:"main":"lib/index.js",然后将 name、 description、 version等信息补充完整。
下面,我们就可以开始发布了,首先你要有一个 npm账号,并且登陆,如果你没有账号,使用下面的命令创建一个账号。
npm adduser --registry http://registry.npmjs.org如果你已经有账号了,那么可以直接使用下面的命令进行登陆。
npm login --registry http://registry.npmjs.org登陆成功之后,就可以发布了:
npm publish --registry http://registry.npmjs.org注意,上面每个命令我都手动指定了 registry,这是因为当前你使用的 npm源可能已经被更换了,可能使用的是淘宝源或者公司源,这时不手动指定会导致发布失败。
发布成功后直接在 npm官网上看到你的包了。
然后,你可以直接使用 npm install tpanorama进行安装,然后进行使用:
var { tpanorama,tpanoramaSetting } = require('tpanorama');6.3 babel编译
最后不要忘了,无论使用以上哪种方式,我们都要使用 babel编译后才能暴露给用户。
在 scripts中创建一个 build命令,将源文件进行编译,最终暴露给用户使用的将是 lib和 origin。
"build": "babel src --out-dir lib && babel originSrc --out-dir origin",你还可以指定一些其他的命令来供用户测试,如我将写好的例子全部放在 examples中,然后在 scripts定义了 expamle命令:
"example": "npm run webpack && node ./server/www"这样,用户将代码克隆后直接在本地运行 npm run example就可以进行调试了。
七、小结
本项目的 github地址:https://github.com/ConardLi/tpanorama
文中如有错误,欢迎在评论区指正,如果这篇文章帮助到了你,欢迎点赞和关
热 文 推 荐
☞ 探索 Serverless 中的前端开发模式
☞ 传说中图片防盗链的爱恨情仇
☞ 前端 api 请求缓存方案
☞ 一名【合格】前端工程师的自检清单
☞ 面试官:自己搭建过vue开发环境吗?


你也“在看”吗?