前言
线性表是指数据之间是一对一的关系,比如数组和链表都属于这一范畴。数组和链表又代表了两种存储方式:顺序存储和链式存储。部分知识已在Java集合源码分析之基础(一):数组与链表中阐述,这里不再赘述,本文是对这些概念的补充,以及给出可参考的Java代码实现。
顺序存储
顺序存储在大多数语言中定义为数组。它的特点就是地址连续,大小固定。下面,我们从增、删、查三个方面说明它的操作性。首先,我们声明了一个数组,并赋值了一些初始值,如下所示:

- 增
- 如果要在空闲位置插入数据,例如位置6,数据插入后无需任何额外操作,此时时间复杂度为O(1),如下所示:

- 如果要在中间某个位置插入数据,例如想把数据6插入到5和7之间,那么7及之后的数据都需要向后移动一位,如下所示:

此时时间复杂度就不再是O(1)了。我们先用java代码实现它,示例如下:
public static void main(String[] args) {
int[] arr = {1,2,5,7,9,11,0,0};
int len = arr.length;
// 在arr[3]插入6,注意边界,最后的数据会被删除
for (int i = len-1; i >= 3; i--) {
arr[i] = arr[i-1];
}
arr[3] = 6;
for (int i = 0; i < len; i++) {
System.out.print(arr[i]);
System.out.print(", ");
}
}
运行后打印结果如下:
2, 5, 6, 7, 9, 11, 0,
最坏情况下,要把元素插入到位置0,需要执行n-1次操作,所以时间复杂度为O(n)。
- 删
删除操作正好和插入相反,删除一个数据后,后边的数据都要向前移动一位,所以它的最坏时间复杂度也是O(n)。
- 查
这里查分两种情况,一种是获取某一位置的数据,一种是查找一个值。
- 获取某个位置元素
对一个数组而言,数组的每个位置都可以通过位置0与偏移量计算出来,例如要获取位置6的地址,只需要:
a[6] = a[0] + 6*{数据长度}
所以它对应的时间复杂度为O(1)。
- 查找值
遗憾的是,数组仅记录下标,却不记录数据本身位置,而且数组的数据也不是有序的(可以插入时排序,但这不是必需),我们要查询一个元素是否存在于数组中,需要对它进行遍历。示例代码如下:
public static void main(String[] args) {
int[] arr = {1,2,5,7,9,11,0,0};
int len = arr.length;
// 查找元素9的位置
for (int i = 0; i < len; i++) {
if(9 == arr[i]){
System.out.println("Index of num 9 is : " + i);
break;
}
}
}
它的最坏时间复杂度也是O(n)。
- 总结
数组是一个中规中矩的数据结构,它在增删查方面的时间复杂度都是O(n),仅在通过Index索引数据时为O(1)。数组也有些高级的用法,比如动态调整大小,这部分知识大家可以看我分析ArrayList的文章:Java集合源码分析之List(二):ArrayList
链式存储
线性存储要求一块完整的内存,在增删数据时也表现一般,而链式存储则正好解决了这些问题。我们依然从增、删、查三个方面来解析。首先,我们先定义使用的Java模型:
class Node{
Integer data;
Node next;
}
其中data表示数据,next表示下一个数据的信息。现在我们实现了一个链表,如下所示:
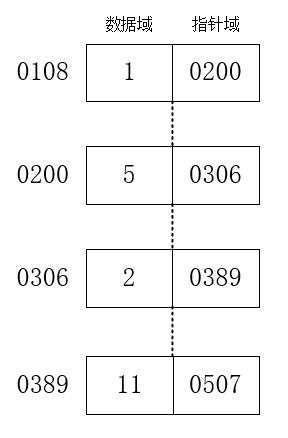
- 增
要在一个链式存储的结构中插入数据,只需要修改一个节点的指针域即可。比如要把元素7插入到1和5之间,把5挂在7后面,再将1的指针域指向7的位置,示意如下:

可以看到这个操作对其他数据不会产生影响,所以它的时间复杂度为O(1)。
- 删
删除与插入类似,其时间复杂度也是O(1),不过其操作顺序和插入时相反。例如要把数据2从原表中删除,需要先把11挂在5的后边,再删除2,示意如下:

- 查
链式存储结构不能像数组一样根据Index获取数据,它的查询也必须要遍历,所以时间复杂度为O(n)。
- 总结
链式存储结构增删数据时时间复杂度是O(1),查询和数组一样,都是O(n),且不支持Index获取。对比数组可以发现,数组适合静态的、不变的数据,而链式适合动态的、变化频繁的数据。
单链表
单链表结构与上述示例类似,每个数据只知道下一个位置的数据,却不知道前一位置的数据。通常,定义一个单链表会设置一个头结点head,它的数据域没有意义,它的指针域指向链表的第一个数据。我们用java代码实现一个简单的单链表。
- 声明一个空链表
Node head = new Node(null,null);
- 添加一条数据
Node first = new Node(2,null);
Node second = new Node(5,null);
first.next = second;
head.next = first;
- 插入一条数据
Node insert = new Node(7,null);
// 注意顺序,①把first也链接在insert后,②再把insert链接在head后
// 因为通常情况下我们只持有head实例的引用
insert.next = head.next;
head.next = insert;
- 遍历
Node print = head.next;
while (print!=null) {
System.out.println(print.data);
print = print.next;
}
- 删除一条数据
// 删除数据2
Node delete = head.next;
Node prev = delete;
while(delete!=null){
if(delete.data == 2){
// 也要注意顺序,先把后边的数据,挂载在前一数据后边
prev.next = delete.next;
// 再删除数据2
delete.next = null;
break;
}
// 记录前一数据
prev = delete;
delete = delete.next;
}
头结点并非是必需的,只是为了保证数据一致性所添加的辅助结点。
双向链表
单链表的特点就是简单,但是它在遍历时只能从前往后,这在某些情况下是不适用的。比如所有的数据都是有序的,按照从小到大排序,数据依次是{1,3,5,6,8,9,11},现在我们已经找到了数据8的位置,想要找到6,按照单链表的设计只能从前向后遍历。这时候如果链表是双向的,从数据8开始,只需要执行一次操作就可以了。
双向链表是在单链表的基础上实现的,只需要在原有结构上增加一个prev指针即可,如下所示:
class Node{
Integer data;
Node prev;
Node next;
}
它的操作和单链表类似,只是在增删时一定要注意顺序,下面对这两部分做重点说明。
- 声明一个空链表
为了数据的一致性,我们增加一个tail结点,作为尾几点:
Node head = new Node(null);
Node tail = new Node(null);
- 添加一条数据
Node first = new Node(2);
Node second = new Node(5);
// next和prev成对设置
second.next = tail;
tail.prev = second;
first.next = second;
second.prev = first;
head.next = first;
first.prev = head;
- 删除一条数据
// 删除数据2
Node delete = head.next;
Node prev = delete;
while(delete!=null){
if(delete.data == 2){
// 要注意顺序,先把后边的数据,挂载在前一数据后边
prev.next = delete.next;
delete.next.prev = prev;
// 再删除数据2
delete.next = null;
delete.prev = null;
break;
}
// 记录前一数据
prev = delete;
delete = delete.next;
}
只要注意成对地处理prev和next,就不会出错。
循环链表
无论是单链表还是双向链表,从某一数据开始遍历,都不能循环整个链表,除非从head或tail开始遍历。循环链表则可以从任意结点开始,遍历整个链表。它也是单链表的变种。
定义一个循环链表十分简单,只需要把单链表的最后一个元素的next指针,指向head即可。示意图如下所示:

它的操作和以上链表都类似,这里不再赘述。
总结
数组和链表是计算机可以存储数据的最基本的结构,其他的数据结构虽然定义不同,但最终还是需要转换成这两种结构才能进行存储,所以我们必须深刻理解。链表也不是仅有以上三种形态,但都是在单链表的基础上进行改造,以适应不同的需求。
在JDK中包装的ArrayList和LinkedList,就是数组和链表的应用,这些类包装了数组和链表的常用操作,还增加了动态管理数组大小的技术,在性能上的表现十分优秀,值得我们参考和学习。大家可以查看以下的文章学习相关知识:
Java集合源码分析之List(二):ArrayList
Java集合源码分析之LinkedList
以上涉及代码均已上传至我的github。
本文到此就结束了,如果您喜欢我的文章,可以关注我的微信公众号: 大大纸飞机
或者扫描下方二维码直接添加:

您也可以关注我的github:https://github.com/LtLei/articles
编程之路,道阻且长。唯,路漫漫其修远兮,吾将上下而求索。