机器学习心得总结:
机器学习算法(一)
介绍如何使用算法:1、如何评价算法好坏。2、如何解决过拟合和欠拟合。3、如何调节算法的参数。4、如何验证算法的正确性。
机器学习的任务:监督学习(分类和回归)
机器学习方法分类:监督学习、非监督学习、半监督学习、增强学习。
非监督学习的意义:对数据进行降维处理(特征提取、特征压缩:PCA)
机器学习其他分类:在线学习和批量学习(离线学习),参数学习和非参数学习
机器学习分为:
监督学习(Supervised Learning)
无监督学习(Unsupervised Learning)
强化学习(Reinforcement Learning,增强学习)
半监督学习(Semi-supervised Learning)
深度学习(Deep Learning)
sklearn库可以完成分类、回归、聚类、降维、模型选择和数据预处理等任务。
有无监督学习主要看其是否有标签,有标签的为监督学习,无标签的为无监督学习。无监督学习最常见的是聚类和降维。
一、
1 聚类
聚类是根据数据的“相似性”将数据分为多类的过程。
评估两个不同样本的相似性,即计算两个样本之间的“距离”。不同计算样本间距离的方法与聚类结果的好坏有关系。
“距离”计算方法如下四种:
1)欧氏距离
二维空间欧氏距离计算:

欧式距离公式:
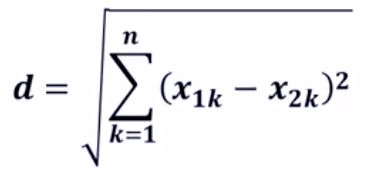
2)曼哈顿距离
二维空间曼哈顿距离计算

曼哈顿距离计算:
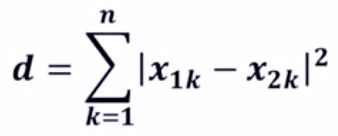
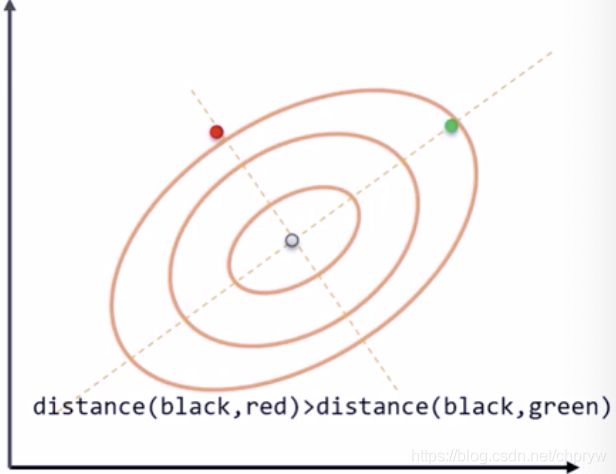
3)马氏距离
二维空间马氏距离
马氏距离:
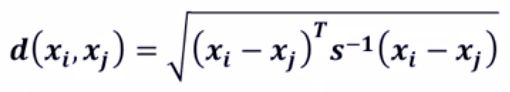
4)夹角余弦
二维空间夹角余弦:

夹角余弦:
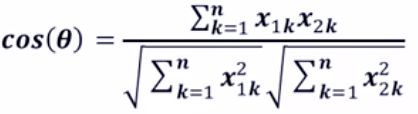
2 降维
降维是在保证数据所具有代表性特征或者分布的情况下,将高维数据转化为低维数据的过程。其作用:数据可视化;精简数据。
二、
聚类算法
1、K-means聚类算法
以k为参数,将n个对象分解成k个簇,使簇内相似度高,簇间相似度低。
步骤:随机选择k个点作为初始的聚类中心,剩下的点根据与聚类中心的距离,归类为最近的簇,对每个簇计算所有点的均值作为新的聚类中心,重复前面剩下点的操作,直到聚类中心不再发生改变。
K-means聚类算法的实现过程
1)建立工程,导入sklearn相关包
import numpy as np
from sklearn.cluster import KMeans
2)加载数据,创建K-means算法实例,并进行训练,获得标签。
1、利用loadData方法读取数据
2、创建实例
3、调用Kmeans()fit_predict()方法进行计算。
调用K-Means方法所需的参数:
n_clusters:用于指定聚类中心的个数
init:初始聚类中心的初始化方法
max_iter:最大的迭代次数
data:加载的数据
label:聚类后各数据所属的标签
fit_predict():计算簇中心以及为簇分配序号
一般调用K-Means方法时,只用给出n_clusters即可,init默认是k-means++,max_iter默认是300。
r+:读写打开一个文本文件
.readlines():一次读取整个文件(类似于.read())
3)输出标签,查看结果
加入聚类结果为5类,则:
km=KMeans(n_clusters=5)
扩展和改进
计算两条数据相似性时,Sklearn的K-Means默认用的是欧氏距离。虽然还有余弦相似度,马氏距离等多种方法,但没有设定计算距离方法的参数。
如果要自定义计算距离,可以更改K-Means代码的eucliden_distances的源码,使用scipy.spatial.distance.cdist方法。例如代码可以改为:
scipy.spatial.distance.cdist(A,B,metric=‘cosine’)
2、DBSCAN方法
DBSCAN算法是一种基于密度的聚类算法,聚类的时候不需要预先指定簇的个数,最终的簇的个数也不定。
DBSCAN算法将数据点分为三类:
核心点:在半径Eps内含有超过MinPts数目的点。
边界点:在半径Eps内点的数量小于MinPts,但是落在核心点的领域内。
噪音点:既不是核心点也不是边界点的点。
DBSCAN算法流程:
1)将所有点标记为核心点、边界点或者噪声点
2)删除噪声点
3)为距离在Eps之内的所有核心点之间赋予一条边
4)每组连通的核心点形成一个簇
5)将每个边界点指派到一个与之关联的核心点的簇中(哪一个核心点的半径范围之内)
DBSCAN算法的实现过程:
1、建立工程,导入sklearn相关包
import numpy as np
from sklearn.cluster import DBSCAN
DBSCAN主要参数:
eps:两个样本被看作邻居节点的最大距离
min_samples:簇的样本数
metric:距离计算公式
代码示例:
sklearn.cluster.DBSCAN(eps=0.5,min_samples=5,metrci=‘euclidean’)
2、读入数据并进行处理
3、聚类,创建DBSCAN算法实例,并进行训练,获得标签:
1)调用DBSCAN方法进行训练,labels为每个数据的簇标签。
2)打印数据被记上的标签,计算标签为-1,即噪声数据的比例。
3)计算簇的个数并打印,评价聚类效果。
4)打印各簇标号以及各簇内数据
4、输出标签,查看结果。
5、画直方图,分析实验结果。
import matplotlib.pyplot as pet plt.hist(X,24)
6、数据分布vs聚类(可以采用对数变换)
降维算法
1、主成分分析(PCA)算法(Principal Component Analysis)
通常用于高维数据的探索与可视化,还可以用作数据压缩和预处理等。该算法把具有相关性的高维变量合成为线性无关的低维变量,称为主成分。主成分能够尽可能保留原始数据的信息。
PCA涉及到的相关术语:方差、协方差、协方差矩阵、特征向量和特征值。
1)方差:各个样本和样本均值的差的平方和的均值,用来度量一组数据的分散程度。

2)协方差:用于度量两个变量之间的线性相关程度,若两个变量的协方差为0,则可认为二者线性无关。协方差矩阵则是由变量的协方差值构成的矩阵(对称阵)。
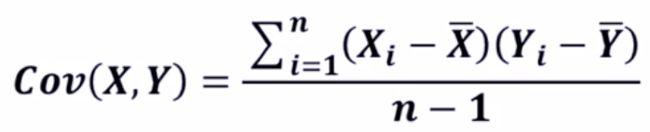
3)特征向量:矩阵的特征向量是描述数据集结构的非零向量并且满足公式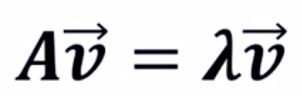
其中A是方阵。
主成分分析原理:矩阵的主成分就是其协方差矩阵对应的特征向量,按照对应的特征值大小进行排序,最大的特征值就是第一主成分,其次是第二主成分,以此类推。
在sklearn库中,使用sklearn.decomposition.PCA加载PCA进行降维,主要的参数如下:
n_components:指定主成分的个数,即降维后数据的维度。
svd_solver:设置特征值分解的方法,默认为‘auto’,其他可选有‘full’,‘arpack’,‘randomized’。
以鸢尾花为实例实现过程:
1、建立工程,导入sklearn相关工具包。
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
2、加载数据并进行降维
data = load_iris()#以字典形式加载鸢尾花数据集
y = data.target#使用y表示数据集中的标签
X = data.data#使用X表示数据集中的属性数据
pca = PCA(n_components=2)#加载PCA算法,设置降维后的主成分数目为2
reduced_X = pca.fit_transform(X)#对原始数据进行降维,保存在reduce_X中
3、按照类别对降维后的数据进行保存
red_x,red_y = [],[]#第一类数据点
blue_x,blue_y = [],[]#第二类数据点
green_x,green_y = [],[]#第三类数据点
4、降维后数据点的可视化:
plt.scatter(red_x,red_y,c='r',marker='x')#第一类数据点
plt.scatter(blue_x,blue_y,c='b',marker='D')#第二类数据点
plt.scatter(green_x,green_y,c='g',marker='.')#第三类数据点
plt.show()#可视化
2、非负矩阵分解(NMF)算法
此算法是在矩阵中所有元素均为非负数约束条件下的矩阵分解方法。
原理:给定一个非负矩阵V,NMF能够找到一个非负矩阵W和一个非负矩阵H,使得矩阵W和H的乘积近似等于矩阵V中的值。

其中,W矩阵是基础图像矩阵,相当于从原矩阵V中抽取出来的特征;H矩阵是系数矩阵。
NMF广泛应用于图像分析、文本挖掘和语音处理等领域。
优化目标的方式有以下几种:
1)矩阵分解优化目标:最小化W矩阵H矩阵的乘积和原始矩阵之间的差别。
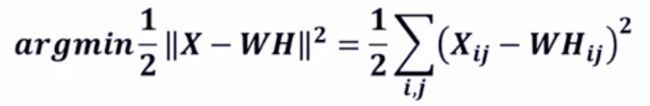
2)基于KL散度的优化目标,损失函数:

在sklearn库中,使用sklearn.decomposition.NMF加载NMF算法,参数如下:
n_components:用于指定分解后矩阵的单个维度k。
init:W矩阵和H矩阵的初始化方式,默认为‘nndsvdar’。
以olivetti人脸数据集为实例程序流程:
1、建立工程,导入sklearn相关工程包
import matplotlib.pyplot as plt
#加载matplotlib用于数据的可视化
from sklearn import decomposition
#加载PCA算法包
from sklearn.datasets import fetch_olivetti_faces
#加载Olivetti人脸数据集导入函数
from numpy.random import RandomState
#加载RandomState用于创建随机种子
2、设置基本参数并加载数据:
n_row,n_col = 2,3
#设置图像展示时的排列情况
n_components = n_row * n_col
#设置提取的特征的数目
image_shape = (64,64)
#设置人脸数据图片的大小
dataset = fetch_olivetti_faces(shuffle=True,
random_state=RandomState(0))
faces = datasets.data
#加载数据,并打乱顺序
3、设置图像的展示方式
def plot_gallery(title,images,n_col=n_col,n_row=n_row);
#创建图片,并制定图片大小(英寸)
plt.figure(figsize=(2.*n_col,2.26*n_row))
#设置标题及字号大小
plt.suptitle(title,size=16)
for i,comp in enumerate(images):
#选择画制的子图
plt.subplot(n_row,n_col,i+1)
vmax = max(comp.max(),-comp.min())
#对数值归一化,并以灰度图形式显示
plt.imshow(comp.reshape(image_shape),
cmap=plt.cm.gray,
interpolation='nearest'
vmin=-vmax,vmax=vmax)
plt.xticks(())
#去除子图的坐标轴标签
plt.yticks(())
#对子图位置及间隔调整
plt.subplots_adjust(0.01,0.05,0.99,0.93,0.04,0)
4、创建特征提取的对象NMF,与PCA对比:
将NMF和PCA存放在一个列表中
estimators = [
('Eigenfaces - PCA using randomized SVD',
decomposition.PCA(n_components=6,whiten=True)),
('Non-negative components - NMF',
decomposition.NMF(n_components=6,init='nndsvda',
tol=5e-3))]
5、降维后数据点的可视化
for name,estimator in estimators:#分别调用PCA和NMF
estimator.fit(faces)#调用PCA或NMF提取特征
components_=estimator.components_#获取提取的特征
#按照固定格式进行排列
plot_gallery(name,components_[:n_components])
plot.show()#可视化
小实例
利用K-means聚类算法对图像像素点颜色进行聚类实现简单的图像分割。同一聚类中的点使用相同的颜色标记,不同聚类颜色不同,要求使用sklearn.cluster.KMeans?
实验步骤
1、建立工程并导入sklearn包
创建Kmeans.py文件,导入sklearn相关包。
import numpy as np
import PIL.Image as image#加载PIL包,用于加载创建图片
from sklearn.cluster import KMeans#加载Kmeans算法
2、加载图片并进行预处理
加载训练数据
def loadData(filePath):
f = open(filePath,'rb')#以二进制形式打开文件
data = []
img = image.open(f)#以列表形式返回图片像素值
m,n = img.size#获得图片的大小
for i in range(m):#将每个像素点RGB颜色处理到0-1
for j in range(n):#范围内并存放进data
x,y,z = img.getpixel((i,j))
data.append([d/256.0,y/256.0,z/256.0])
f.close()
return np.mat(data),m,n#以矩阵的形式返回data,以及图片大小
imgData,row,col = loadData('kmeans/bull.jpg')#加载数据
3、加载Kmeans聚类算法
km = KMeans(n_clusters=3)
其中,n_clusters属性指定了聚类中心的个数为3。
4、对像素点进行聚类并输出
(PIL包:因为实验中涉及图像的加载和创建,因此需要使用PIL包。)
依据聚类中心,对术语同一聚类的点使用同样的颜色进行标记。
#聚类获得每个像素所属的类别
label = km.fit_predict(imgData)
label = label.reshape([row,col])
#创建一张新的灰度图保存聚类后的结果
pic_new = image.new("L",(row,col))
#根据所属类别向图片中添加灰度值
for i in range(row):
for j in range(col):
pic_new.putpixel((i,j),256/(label[i][j]+1))
#以JPEG格式保存图像
pic_new.save("result-bull-4.jpg","JPEG")