大数据开发之Druid数据查询
1 Druid数据查询
1.1:查询组件介绍
在介绍具体的查询之前,我们先来了解一下各种查询都会用到的基本组件,如Filter,Aggregator,Post-Aggregator,Query,Interval等,每种组件都包含很多的细节
1.1.1 Filter
Filter就是过滤器,在查询语句中就是一个JSON对象,用来对维度进行筛选和过滤,表示维度满足Filter的行是我们需要的数据,类似sql中的where字句。Filter包含的类型如下:
Selector Filter
Selector Filter的功能类似于SQL中的where key=value,它的json示例如下:
“Filter”:{“type”:“selector”,“dimension”:dimension_name,“value”:target_value}
{
"queryType":"timeseries",//查询的类型,druid中有timeseries,groupby ,select,search
"dataSource":"adclicklog",//指定你要查询的数据源
"granularity":"day",//指定时间聚合的区间,按照每天的时间维度聚合数据
"aggregations":[//聚合器,
{
"type":"longSum",//数值类型的累加
"name":"click",//聚合后的输出字段,select sum(price) as totalPrice
"fieldName":"click_cnt" //按照哪个原始字段聚合,
},{
"type":"longSum",
"name":"pv",
"fieldName":"count"//求pv,其实就是求出原始数据的条数,
}
],
"filter":{"type":"selector","dimension":"device_type","value":"pc"},//selectorfilter过滤出pc
"intervals":["2019-05-30/2019-05-31"] //指定查询的时间范围,前闭后开
}
Regex Filter
Regex Filter 允许用户使用正则表达式进行维度的过滤筛选,任何java支持的标准正则表达式druid都支持,它的JSON格式如下:
“filter":{“type”:“regex”,“dimension”:dimension_name,“pattern”:regex}
正则表达式判断我们的device_type是不是pc,
.*pc.*
{
"queryType":"timeseries",
"dataSource":"adclicklog",
"granularity":"day",
"aggregations":[
{
"type":"longSum",
"name":"click",
"fieldName":"click_cnt"
},{
"type":"longSum",
"name":"pv",
"fieldName":"count"
}
],
"filter":{"type":"regex","dimension":"device_type","pattern":".*pc.*"},
"intervals":["2019-05-30/2019-05-31"]
}
1+$ :该正则的意思是匹配所有的数字和字母
Logincal Expression Filter (and,or,not)
Logincal Expression Filter包含and,not,or三种过滤器,每一种都支持嵌套,可以构建丰富的逻辑表达式,与sql中的and,not,or类似,JSON表达式如下:
“filter”:{“type”:“and”,“fields”:[filter1,filter2]}
“filter”:{“type”:“or”,“fields”:[filter1,filter2]}
“filter”:{“type”:“not”,“fields”:[filter]}
{
"queryType":"timeseries",
"dataSource":"adclicklog",
"granularity":"day",
"aggregations":[
{
"type":"longSum",
"name":"click",
"fieldName":"click_cnt"
},{
"type":"longSum",
"name":"pv",
"fieldName":"count"
}
],
"filter":{
"type":"and",
"fields":[
{"type":"selector","dimension":"device_type","value":"pc"},
{"type":"selector","dimension":"host","value":"baidu.com"}
]
},
"intervals":["2019-05-30/2019-05-31"]
}
In Filter
In Filter类似于SQL中的in, 比如 where username in(‘zhangsan’,‘lisi’,‘zhaoliu’),它的JSON格式如下:
{
“type”:“in”,
“dimension”:“username”,
“values”:[‘zhangsan’,‘lisi’,‘zhaoliu’]
}
{
"queryType":"timeseries",
"dataSource":"adclicklog",
"granularity":"day",
"aggregations":[
{
"type":"longSum",
"name":"click",
"fieldName":"click_cnt"
},{
"type":"longSum",
"name":"pv",
"fieldName":"count"
}
],
"filter":{
"type":"in",
"dimension":"device_type",
"values":["pc","mobile"]
},
"intervals":["2019-05-30/2019-05-31"]
}
Bound Filter
Bound Filter是比较过滤器,包含大于,等于,小于三种,它默认支持的就是字符串比较,是基于字典顺序,如果使用数字进行比较,需要在查询中设定alpaNumeric的值为true,需要注意的是Bound Filter默认的大小比较为>=或者<=,因此如果使用<或>,需要指定lowerStrict值为true,或者upperStrict值为true,它的JSON格式如下:
21 <=age<=31:
{
“type”:“bound”,
“dimension”:“age”,
“lower”:“21”, #默认包含等于
“upper”:“31”, #默认包含等于
“alphaNumeric”:true #数字比较时指定alphaNumeric为true
}
21 { “type”:“bound”, “dimension”:“age”, “lower”:“21”, “lowerStrict”:true, #去掉包含 “upper”:“31”, “upperStrict”:true, #去掉包含 “alphaNumeric”:true #数字比较时指定alphaNumeric为true } 聚合粒度通过granularity配置项指定聚合时间跨度,时间跨度范围要大于等于创建索引时设置的索引粒度,druid提供了三种类型的聚合粒度分别是:Simple,Duration,Period Simple的聚合粒度 Simple的聚合粒度通过druid提供的固定时间粒度进行聚合,以字符串表示,定义查询规则的时候不需要显示设置type配置项,druid提供的常用Simple粒度:all,none,minute,fifteen_minute,thirty_minute,hour,day,month,Quarter(季度),year; all:会将起始和结束时间内所有数据聚合到一起返回一个结果集, none:按照创建索引时的最小粒度做聚合计算,最小粒度是毫秒为单位,不推荐使用性能较差; minute:以分钟作为聚合的最小粒度; fifteen_minute:15分钟聚合; thirty_minute:30分钟聚合 hour:一小时聚合 day:天聚合 数据源: Duration聚合粒度 duration聚合粒度提供了更加灵活的聚合粒度,不只局限于Simple聚合粒度提供的固定聚合粒度,而是以毫秒为单位自定义聚合粒度,比如两小时做一次聚合可以设置duration配置项为7200000毫秒,所以Simple聚合粒度不能够满足的聚合粒度可以选择使用Duration聚合粒度。注意:使用Duration聚合粒度需要设置配置项type值为duration. Period聚合粒度 Period聚合粒度采用了日期格式,常用的几种时间跨度表示方法,一小时:PT1H,一周:P1W,一天:P1D,一个月:P1M;使用Period聚合粒度需要设置配置项type值为period, 案例: Aggregator是聚合器,聚合器可以在数据摄入阶段和查询阶段使用,在数据摄入阶段使用聚合器能够在数据被查询之前按照维度进行聚合计算,提高查询阶段聚合计算性能,在查询过程中,使用聚合器能够实现各种不同指标的组合计算。 聚合器的公共属性介绍: type:声明使用的聚合器类型; name:定义返回值的字段名称,相当于sql语法中的字段别名; fieldName:数据源中已定义的指标名称,该值不可以自定义,必须与数据源中的指标名一致; 计数聚合器,等同于sql语法中的count函数,用于计算druid roll-up合并之后的数据条数,并不是摄入的原始数据条数,在定义数据模式指标规则中必须添加一个count类型的计数指标count; 比如想查询Roll-up 后有多少条数据,查询的JSON格式如下: {“type”:“count”,“name”:out_name} 如果想要查询原始数据摄入多少条,在查询时使用longSum,JSON示例如下: {“type”:“longSum”,“name”:out_name,“fieldName”:“count”} 求和聚合器,等同于sql语法中的sum函数,用户指标求和计算,druid提供两种类型的聚合器,分别是long类型和double类型的聚合器; 第一类就是longSum Aggregator ,负责整数类型的计算,JSON格式如下: {“type”:“longSum”,“name”:out_name,“fieldName”:“metric_name”} 第二类是doubleSum Aggregator,负责浮点数计算,JSON格式如下: {“type”:“doubleSum”,“name”:out_name,“fieldName”:“metric_name”} 负责计算出指定metric的最大或最小值;类似于sql语法中的Min/Max doubleMin aggregator { “type” : “doubleMin”, “name” : doubleMax aggregator { “type” : “doubleMax”, “name” : longMin aggregator { “type” : “longMin”, “name” : longMax aggregator { “type” : “longMax”, “name” : DataSketche Aggregator是近似基数计算聚合器,在摄入阶段指定metric,从而在查询的时候使用,要在conf/druid/_common/common.runtime.properties配置文件中声明加载依赖druid.extensions.loadList=[“druid-datasketches”],之前已有的hdfs,mysql等不要删除,添加这个扩展即可。 使用的场景:高基数维度的去重计算,比如用户访问数等 DataSketche聚合器在数据摄入阶段规则定义格式如下: 在查询阶段规则定义: Post-Aggregator可以对结果进行二次加工并输出,最终的输出既包含Aggregation的结果,也包含Post-Aggregator的结果,Post-Aggregator包含的类型: Arithmetic Post-Aggregator支持对Aggregator的结果进行加减乘除的计算,JSON格式如下: Field Accessor Post-Aggregator返回指定的Aggregator的值,在Post-Aggregator中大部分情况下使用fieldAccess来访问Aggregator,在fieldName中指定Aggregator里定义的name,如果对HyperUnique的结果进行访问,需要使用hyperUniqueCardinality,Field Accessor Post-Aggregator的JSON示例如下: 我们计算日期20190530的广告总点击量,曝光量和曝光率,曝光率等于点击量除以曝光量,曝光率的计算就可以使用druid的后聚合器实现: 类似的sql: druid如何实现: druid查询采用的是HTTP RESTFUL方式,REST接口负责接收客户端的查询请求,客户端只需要将查询条件封装成JSON格式,通过HTTP方式将JSON查询条件发送到broker节点,查询成功会返回JSON格式的结果数据。了解一下druid提供的查询类型 timeseries时间序列查询对于指定时间段按照查询规则返回聚合后的结果集,查询规则中可以设置查询粒度,结果排序方式以及过滤条件,过滤条件可以使用嵌套过滤,并且支持后聚合。 timeseries查询属性: 类似sql语句: druid JSON格式查询: 然后通过HTTP POST方式执行查询,注意发送的是broker节点地址。 topn查询是通过给定的规则和显示维度返回一个结果集,topn查询可以看做是给定排序规则,返回单一维度的group by查询,但是topn查询比group by性能更快。metric这个属性是topn专属的按照该指标排序。 topn的查询属性如下: topn查询规则定义: 关于排序规则: 在实际应用中经常需要进行分组查询,等同于sql语句中的Group by查询,如果对单个维度和指标进行分组聚合计算,推荐使用topN查询,能够获得更高的查询性能,分组查询适合多维度,多指标聚合查询: 分组查询属性: limitSpec规则定义的主要作用是查询结果进行排序,提取数据条数,类似于sql中的order by 和limit的作用;规则定义格式如下: limitSpec属性表: 分组查询规则定义: search 查询返回匹配中的维度,对维度值过滤查询,类似于sql中的like语法,它的相关属性: 搜索规则用于搜索维度值范围内与搜索值是否相匹配,类似于sql中where限制条件中的like语法,使用搜索过滤器需要设置三个配置项:type过滤器类型值为:search,dimension值为维度名称,query值为json对象,定义搜索过滤规则。搜索过滤规则有Insensitive Contains,Fragment,Contains (1)Insensitive Contains 维度值的任何部分包含指定的搜索值都会匹配成功,不区分大小写,定义规则如下: sql语句中where city like '%jing%'转为等价的查询规则如下: (2)Fragment Fragment提供一组搜索值,纬度值任何部分包含全部搜索值则匹配成功,匹配过程可以选择忽略大小写,使用Fragment搜索过滤器需要配置三个选项:type:fragment,values:设置一组值(使用json数组),case_sensitive:表示是否忽略大小写,默认为false,不忽略大小写; 样例,sql语句中where city like ‘%bei%’ and city like '%jing%'转化为等价的查询 (3)Contains 维度值的任何部分包含指定的搜索值都会匹配成功,与insensitive Contains实现的功能类似,唯一不同的是Contains过滤类型可以配置是否区分大小写。 样例:sql语句中where city like "%bei%"转化为等价查询规则如下: 提交查询任务 //提交kafka索引任务 提交普通索引导入数据任务 //获取指定kafka索引任务的状态 杀死一个kafka索引任务 删除datasource,提交到coordinator ], curl -X ‘POST’ -H’Content-Type: application/json’ -d @quickstart/ds.json http://hp103:8082/druid/v2/?pretty curl -X POST -H ‘Content-Type: application/json’ -d @kafka-index.json http://hp101:8090/druid/indexer/v1/supervisor curl -X ‘POST’ -H ‘Content-Type:application/json’ -d @hadoop-index.json hp101:8090/druid/indexer/v1/task curl -X GET http://hp101:8090/druid/indexer/v1/supervisor/kafkaindex333/status curl -X GET http://hp101:8090/druid/indexer/v1/supervisor/kafkaindex333/shutdown curl -XDELETE http://hp101:8081/druid/coordinator/v1/datasources/adclicklog6 a-z0-9A-Z ↩︎1.1.2 granularity

统计2019年05月30日的不同终端设备的曝光量,曝光量输出字段名称为pv,查询规则如下:{
"queryType":"groupBy",
"dataSource":"adclicklog",
"granularity":"day",
"dimensions":["device_type"],
"aggregations":[
{
"type":"longSum",
"name":"pv",
"fieldName":"count"
}
],
"intervals":["2019-05-30/2019-05-31"]
}
{
"queryType":"groupBy",
"dataSource":"adclicklog",
"dimensions":["device_type"],
"granularity":{
"type":"duration",
"duration":7200000
},
"aggregations":[
{
"type":"longSum",
"name":"pv",
"fieldName":"pv_cnt"
}
],
"intervals":["2019-05-29/2019-05-31"]
}
{
"queryType":"groupBy",
"dataSource":"adclicklog",
"granularity":{
"type":"period",
"period":"P1D"
},
"aggregations":[
{
"type":"longSum",
"name":"pv",
"fieldName":"pv_cnt"
}
],
"intervals":["2019-05-29/2019-05-31"]
}
1.1.3 Aggregator
Count Aggregator
{
"queryType":"timeseries",
"dataSource":"ad_event",
"granularity":{
"type":"period",
"period":"P1D"
},
"aggregations":[
{
"type":"count",
"name":"count"
},
{
"type":"longSum",
"name":"pv",
"fieldName":"count"
}
],
"intervals":["2018-12-01/2018-12-3"]
}
{
"queryType":"timeseries",
"dataSource":"adclicklog",
"granularity":{
"type":"period",
"period":"P1D"
},
"aggregations":[
{
"type":"longSum",
"name":"pv",
"fieldName":"count"
}],
"intervals":["2019-05-29/2019-05-31"]
}
Sum Aggregator
Min/Max Aggregator
{
"queryType":"timeseries",
"dataSource":"adclicklog",
"granularity":{
"type":"period",
"period":"P1D"
},
"aggregations":[
{
"type":"longMin",
"name":"min",
"fieldName":"is_new"
}
],
"intervals":["2019-05-30/2019-05-31"]
}
DataSketche Aggregator
{"type":"thetaSketch",
"name":{
"type": "kafka",
"dataSchema": {
"dataSource": "adclicklog",
"parser": {
"type": "string",
"parseSpec": {
"format": "json",
"timestampSpec": {
"column": "timestamp",
"format": "auto"
},
"dimensionsSpec": {
"dimensions": [],
"dimensionExclusions": [
"timestamp",
"is_new",
"pv_cnt",
"click_cnt"
]
}
}
},
"metricsSpec": [
{
"name": "count",
"type": "count"
},
{
"name": "click_cnt",
"fieldName": "click_cnt",
"type": "longSum"
},
{
"name": "new_cnt",
"fieldName": "is_new",
"type": "longSum"
},
{
"name": "uv",
"fieldName": "user_id",
"type": "thetaSketch",
"isInputThetaSketch":"false",
"size":"16384"
},
{
"name": "click_uv",
"fieldName": "click_user_id",
"type": "thetaSketch",
"isInputThetaSketch":"false",
"size":"16384"
}
],
"granularitySpec": {
"type": "uniform",
"segmentGranularity": "HOUR",
"queryGranularity": "NONE"
}
},
"tuningConfig": {
"type": "kafka",
"maxRowsPerSegment": 5000000
},
"ioConfig": {
"topic": "process_ad_click",
"consumerProperties": {
"bootstrap.servers": "hp101:9092,hp102:9092",
"group.id":"kafka-index-service"
},
"taskCount": 1,
"replicas": 1,
"taskDuration": "PT5m"
}
}
{
"type":"thetaSketch",
"name":{
"queryType":"groupBy",
"dataSource":"adclicklog",
"granularity":{
"type":"period",
"period":"PT1H",
"timeZone": "Asia/Shanghai"
},
"dimensions":["device_type"],
"aggregations":[
{
"type": "thetaSketch",
"name": "uv",
"fieldName": "uv"
}
],
"intervals":["2019-05-30/2019-05-31"]
}
1.1.4 Post-Aggregator
Arithmetic Post-Aggregator
"postAggregation":{
"type":"arithmetic",
"name":out_name,
"fn":function,
"fields":[post_aggregator1,post_aggregator2]
}
Field Accessor Post-Aggregator
{
"type":"fieldAccess",
"name":out_name,
"fieldName":aggregator_name
}
select t.click_cnt,t.pv_cnt,(t.click/t.pv*100) click_rate from
(select sum(click_cnt) ,sum(pv_cnt) pv_cnt from ad_event where dt='20181201' ) t
{
"queryType": "timeseries",
"dataSource": "adclicklog",
"granularity":{
"type":"period",
"period":"PT1H"
},
"intervals": [
"2019-05-30/2019-05-31"
],
"aggregations": [
{
"type": "longSum",
"name": "pv_cnt",
"fieldName": "count"
},
{
"type": "longSum",
"name": "click_cnt",
"fieldName": "click_cnt"
}
],
"postAggregations": [
{
"type": "arithmetic",
"name": "click_rate",
"fn": "*",
"fields": [
{
"type": "arithmetic",
"name": "div",
"fn": "/",
"fields": [
{
"type": "fieldAccess",
"name": "click_cnt",
"fieldName": "click_cnt"
},
{
"type": "fieldAccess",
"name": "pv_cnt",
"fieldName": "pv_cnt"
}
]
},
{
"type": "constant",
"name": "const",
"value": 100
}
]
}
]
}
1.2 查询类型
1.2.1 时间序列查询
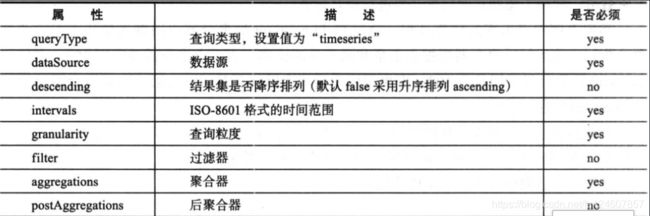
案例:统计2019年05月30日北京地区曝光量,点击量select sum(click_cnt) click,sum(pv_cnt) pv from ad_event
wehre dt='20181201' and city = 'beijing'
{
"queryType":"timeseries",
"dataSource":"adclicklog",
"descending":"true",
"granularity":"minute",
"aggregations":[
{
"type":"longSum",
"name":"click",
"fieldName":"click_cnt"
},{
"type":"longSum",
"name":"pv",
"fieldName":"count"
}
],
"filter":{"type":"selector","dimension":"city","value":"beijing"},
"intervals":["2019-05-30/2019-05-31"]
}
1.2.2 TopN查询
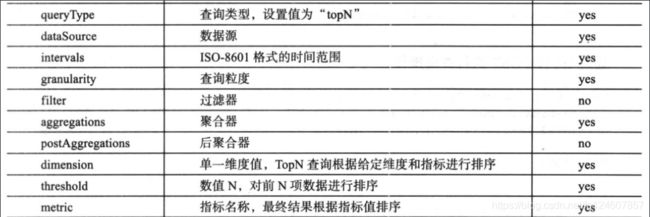
案例:统计2019年05月30日PC端曝光量和点击量,取点击量排名前二的城市{
"queryType":"topN",
"dataSource":"adclicklog",
"dimension":"city",
"threshold":2,
"metric":"click_cnt",
"granularity":"day",
"filter":{
"type":"selector",
"dimension":"device_type",
"value":"pc"
},
"aggregations":[
{
"type":"longSum",
"name":"pv_cnt",
"fieldName":"count"
},
{
"type":"longSum",
"name":"click_cnt",
"fieldName":"click_cnt"
}
],
"intervals":["2019-05-30/2019-05-31"]
}
"metric" : {
"type" : "numeric", //指定按照numeric 降序排序
"metric" : "1.2.3分组查询

limitSpec


案例:统计2018年12月1日各城市PC端和TV端的曝光量,点击量,点击率,取曝光量排名前三的城市数据;曝光量相同则按照城市名称升序排列。{
"queryType": "groupBy",
"dataSource": "adclicklog",
"granularity": "day",
"intervals": [
"2019-05-30/2019-05-31"
],
"dimensions": [
"city",
"device_type"
],
"aggregations": [
{
"type": "longSum",
"name": "pv_cnt",
"fieldName": "count"
},
{
"type": "longSum",
"name": "click_cnt",
"fieldName": "click_cnt"
}
],
"postAggregations": [
{
"type": "arithmetic",
"name": "click_rate",
"fn": "*",
"fields": [
{
"type": "arithmetic",
"name": "div",
"fn": "/",
"fields": [
{
"type": "fieldAccess",
"name": "click_cnt",
"fieldName": "click_cnt"
},
{
"type": "fieldAccess",
"name": "pv_cnt",
"fieldName": "pv_cnt"
}
]
},
{
"type": "constant",
"name": "const",
"value": 100
}
]
}
],
"limitSpec": {
"type": "default",
"limit": 3,
"columns": [
{
"dimension": "pv_cnt",
"direction": "descending"
},
{
"dimension": "city",
"direction": "ascending"
}
]
}
}
1.2.4 search搜索查询
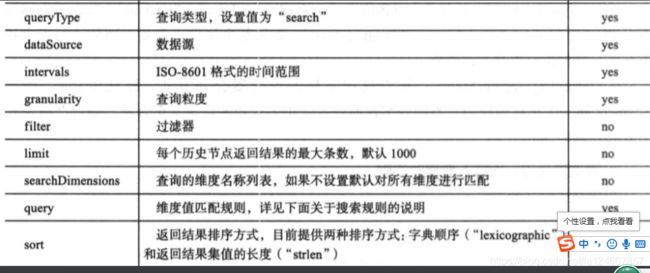
{
"type":"insensitive_contains",
"value":"some_value"
}
{
"queryType": "search",
"dataSource": "adclicklog",
"granularity": "all",
"limit": 2,
"searchDimensions": [
"city"
],
"query": {
"type": "insensitive_contains",
"value": "jing"
},
"sort" : {
"type": "lexicographic"
},
"intervals": [
"2019-05-29/2019-05-31"
]
}
{
"queryType": "search",
"dataSource": "adclicklog",
"granularity": "all",
"limit": 2,
"searchDimensions": [
"city"
],
"query": {
"type": "fragment",
"values": ["jing","bei"],
"case_sensitive":true
},
"sort" : {
"type": "lexicographic"
},
"intervals": [
"2019-05-29/2019-05-31"
]
}
{
"queryType": "search",
"dataSource": "adclicklog",
"granularity": "all",
"limit": 2,
"searchDimensions": [
"city"
],
"query": {
"type": "contains",
"value": "bei",
"case_sensitive":true
},
"sort" : {
"type": "lexicographic"
},
"intervals": [
"2019-05-29/2019-05-31"
]
}
6 查询的API
6.1 druid restful api展示
curl -X 'POST' -H'Content-Type: application/json' -d @quickstart/ds.json http://hp103:8082/druid/v2/?pretty
curl -X POST -H 'Content-Type: application/json' -d @kafka-index.json http://hp101:8090/druid/indexer/v1/supervisor
curl -X 'POST' -H 'Content-Type:application/json' -d @hadoop-index.json hp101:8090/druid/indexer/v1/task
curl -X GET http://hp101:8090/druid/indexer/v1/supervisor/kafkaindex333/status
curl -X GET http://hp101:8090/druid/indexer/v1/supervisor/kafkaindex333/shutdown
curl -XDELETE http://hp101:8081/druid/coordinator/v1/datasources/adclicklog6
"city"
“query”: {
“type”: “contains”,
“value”: “bei”,
“case_sensitive”:true
},
“sort” : {
“type”: “lexicographic”
},
“intervals”: [
“2019-05-29/2019-05-31”
]
}
# 6 查询的API
## 6.1 druid restful api展示
提交查询任务
//提交kafka索引任务
提交普通索引导入数据任务
//获取指定kafka索引任务的状态
杀死一个kafka索引任务
删除datasource,提交到coordinator