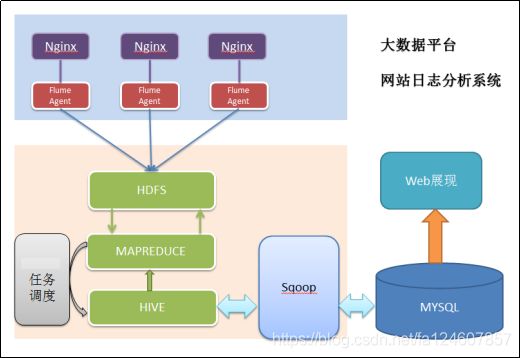
网站日志分析整体技术流程及系统架构
- 网站分析意义
网站分析,可以帮助网站管理员、运营人员、推广人员等实时获取网站流量信息,并从流量来源、网站内容、网站访客特性等多方面提供网站分析的数据依据。从而帮助提高网站流量,提升网站用户体验,让访客更多的沉淀下来变成会员或客户,通过更少的投入获取最大化的收入。
事实上网站分析设计的内容非常广泛,由很多部分组成。每一部分都可以单独作为一个分析项目,如下所示:

首先,网站分析是网站的眼睛。是从网站的营销角度看到的网站分析。在这部分中,网站分析的主要对象是访问者,访问者在网站中的行为以及不同流量之间的关系。
其次,网站分析是整个网站的神经系统。这是从产品和架构的角度看到的网站分析。在这部分中,网站分析的主要对象是网站的逻辑和结构,网站的导航结构是否合理,注册购买流程的逻辑是否顺畅。
最后,网站分析是网站的大脑,在这部门中,网站分析的主要分析对象是投资回报率(ROI)。也就是说在现有的情况下,如何合理的分配预算和资源以完成网站的目标。
终极意义:改善网站的运营,获取更高投资回报率(ROI)。赚更多的钱。
2 数据处理流程
网站流量日志数据分析是一个纯粹的数据分析项目,其整体流程基本上就是依据数据的处理流转流程进行。通俗可以概括为:数据从哪里来和数据到哪里去,可以分为以下几个大的步骤:
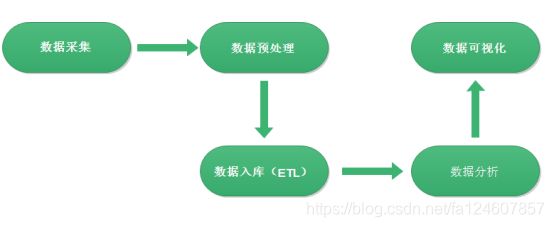
2.1 数据采集
数据采集概念,目前行业会有两种解释:
一是数据从无到有产生的过程(服务器打印的log、自定义采集的日志等)叫做数据采集;
另一方面也有把通过使用Flume等工具把数据采集搬运到指定位置的这个过程叫做数据采集。
关于具体含义要结合语境具体分析,明白语境中具体含义即可。
2.2 数据预处理
数据预处理(data preprocessing)是指在正式处理以前对数据进行的一些处理。现实世界中数据大体上都是不完整,不一致的脏数据,无法直接进行数据分析,或者说不利于分析。为了提高数据分析的质量和便捷性产生了数据预处理技术。
数据预处理有多种方法:数据清理,数据集成,数据变换等。这些数据处理技术在正式数据分析之前使用,大大提高了后续数据分析的质量与便捷,降低实际分析所需要的时间。
技术上原则来说,任何可以接受数据经过处理输出数据的语言技术都可以用来进行数据预处理。比如java、Python、shell等。
大数据Hadoop项目中通过MapReduce程序对采集到的原始日志数据进行预处理,比如数据清洗,日期格式整理,滤除不合法数据等,并且梳理成点击流模型数据。
使用MapReduce的好处在于:一是java语言熟悉度高,有很多开源的工具库便于数据处理,二是MR可以进行分布式的计算,并发处理效率高。
2.3 数据入库
预处理完的结构化数据通常会导入到Hive数据仓库中,建立相应的库和表与之映射关联。这样后续就可以使用Hive SQL针对数据进行分析。
因此这里所说的入库是把数据加进面向分析的数据仓库,而不是数据库。因项目中数据格式比较清晰简明,可以直接load进入数据仓库。
实际中,入库过程有个更加专业的叫法—ETL。ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。
| ETL的设计分三部分:数据抽取、数据的清洗转换、数据的加载。在设计ETL的时候我们也是从这三部分出发。数据的抽取是从各个不同的数据源抽取到ODS(Operational Data Store,操作型数据存储)中——这个过程也可以做一些数据的清洗和转换),在抽取的过程中需要挑选不同的抽取方法,尽可能的提高ETL的运行效率。ETL三个部分中,花费时间最长的是“T”(Transform,清洗、转换)的部分,一般情况下这部分工作量是整个ETL的2/3。数据的加载一般在数据清洗完了之后直接写入DW(Data Warehousing,数据仓库)中去。 |
2.4 数据分析
本阶段是项目的核心内容,即根据需求使用Hive SQL分析语句,得出指标各种统计结果。

2.5 数据可视化
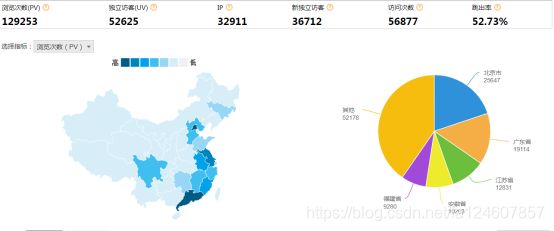
将分析所得数据结果进行数据可视化,一般通过图表进行展示。
数据可视化可以帮你更容易的解释趋势和统计数据。
3 系统的架构
相对于传统的BI数据处理,流程几乎差不多,但是因为是处理大数据,所以流程中各环节所使用的技术则跟传统BI完全不同:
数据采集:页面埋点JavaScript采集;开源框架Apache Flume
数据预处理: Hadoop MapReduce程序
数据仓库技术:基于hadoop的数据仓库Hive
数据导出:基于hadoop的sqoop数据导入导出工具
数据可视化:定制开发web程序(echarts)
整个过程的流程调度:hadoop生态圈中的azkaban工具