论文笔记——FCOS:Fully Convolutional One-Stage Object Detection
论文题目:Fully Convolutional One-Stage Object Detection
论文链接:https://openaccess.thecvf.com/content_ICCV_2019/papers/Tian_FCOS_Fully_Convolutional_One-Stage_Object_Detection_ICCV_2019_paper.pdf
最近看了两篇anchor-free的detection论文,分别是CenterNet和这篇FCOS,其共性都使得网络免去对anchor的依赖,变得简单高效又不失精度。

对于FCOS的backbone部分,采用了基于FPN的Resnet,输出为P3-P7这五个不同尺度的特征图,用于后续的预测。这里先拿某一个尺度的特征图为例。如果还原到原始image上的位置在GT的box内,则该点称为正样本,否则称为负样本。特征图后续接入预测head,该head主要负责预测两个部分,即对于feature map的每个点来说,输出预测instance位置大小的4d向量 t = ( l , t , r , b ) \bold t=(l,t,r,b) t=(l,t,r,b);以及类别置信向量 p \bold p p,对于coco数据集来说该向量维度是80。 t = ( l , t , r , b ) \bold t=(l,t,r,b) t=(l,t,r,b)每个维度的意义如下图Fig.1所示(代表中心点距离bbox左、上、右、下的距离,文中利用exp(x)将他们都映射到[0,∞) ):
因此再回过来看Fig.2,输出的4d位置向量 t x , y \bold t_{x,y} tx,y,倘若该位置属于正样本,那么他在「(x,y)到bounding box四条边的距离 t ∗ = ( l ∗ , t ∗ , r ∗ , b ∗ ) \bold t^{*}=(l^{*},t^{*},r^{*},b^{*}) t∗=(l∗,t∗,r∗,b∗)」的约束下做regression;同时classification分支输出预测每个类别置信度的向量 p x , y \bold p_{x,y} px,y(这里p之前的训练并不是按照多分类器来训练的,而是分成了80个binary classifier训练,符合focal loss)。在training阶段,回归部分采用IOU loss,而分类部分采用经典的focal loss,具体形式如下:
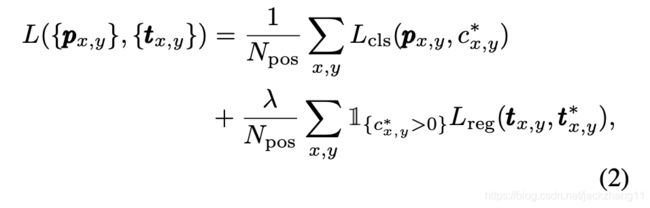
在inference阶段,通过正向的预测可以得到每个特征图上对应点的位置向量 t x , y \bold t_{x,y} tx,y,和分类置信度 p x , y \bold p_{x,y} px,y。如果 p x , y > 0.05 \bold p_{x,y}>0.05 px,y>0.05,则把该样本(x,y)记作positive sample,并做后续的操作以得到真实的bbox位置。
到这里可能会有疑问,如果某一个点(x,y)落在了多个bbox内部呢,那这个点负责预测哪个框?作者在文中表明,这种情况下预测size最小的。那就又有疑问了,这样的话recall就会降低很多呀。所以为了解决这个问题,作者采用了multi-level prediction的方法,也就是说,之前基于FPN的backbone得到P3-P7这五个尺度的feature,我们可以根据每个特征图上的一点对应的感受野的不同,来给他们分配不同尺寸的框。
具体怎么做呢?首先我们知道P3-P7的stride分别为8, 16, 32, 64, 128。我们设定m2-m7分别为0, 64, 128, 256, 512, ∞。对于特征图 P i P_{i} Pi上的一点的 t ∗ = ( l ∗ , t ∗ , r ∗ , b ∗ ) \bold t^{*}=(l^{*},t^{*},r^{*},b^{*}) t∗=(l∗,t∗,r∗,b∗),如果 m i − 1 ≤ m a x ( l ∗ , t ∗ , r ∗ , b ∗ ) ≤ m i m_{i-1}\le max(l^{*},t^{*},r^{*},b^{*}) \le m_{i} mi−1≤max(l∗,t∗,r∗,b∗)≤mi,这样才将其视为正样本,若在这个范围之外,都视作负样本。这里拿 P 3 P_{3} P3为例, P 3 P_{3} P3是resolution最大的feature map,因此对应的receptive field最小,更适合预测尺寸小的instance,所以对应的 [ m 2 , m 3 ] [m_{2},m_{3}] [m2,m3]的区间也比较小。与此同时,不同的feature level应该去回归不同range size的instance,所以如果都用同样的head显然是不合理的,因此作者提出了一个可训练的标量 s i s_{i} si,并将回归branch的exp(x)进行了修改,变为exp( s i x s_{i}x six),以自适应feature level,可以稍微涨一些点。
文中还有一个非常重要的概念叫centerness。因为有很多中心点偏离实际中心很多的预测框,这类框会拉低检测的效果。因此作者提出了centerness这个概念,可以理解为“中心度”,其计算公式如下:
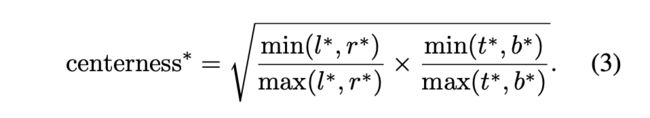
可见centerness的取值在[0,1]区间内,越靠近bbox中心的点的centerness越大,越接近于1。此时再回过头来看最上方的Fig.2,发现它后面有一个 H ∗ W ∗ 1 H*W*1 H∗W∗1的centerness分支,用来预测每一个点(x,y)的centerness。这个loss采用BCE loss进行训练。而最后对于bbox的打分基于centerness与 p p p的乘积,因此配合后处理NMS可以筛除掉中心非常偏离的低centerness检测框。
Ablation Study实验结果
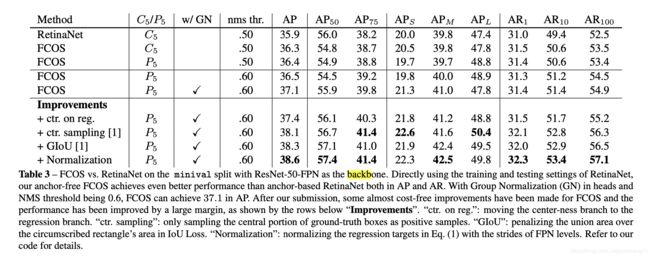
和其他SOTA的比较