基于隐语义模型的推荐系统

如何根据上边两位豆瓣用户的图书列表做出推荐?
传统的推荐方法
UserCF,首先需要找到和他们看了同样书的其他用户,然后给他们推荐那些用户喜欢的其他书。
ItemCF,需要给他们推荐和他们已经看的书相似的书。
基于隐语义模型
通过矩阵分解建立用户和隐类之间的关系,物品和隐
类之间的关系,最终得到用户对物品的偏好关系。
隐语义模型(LFM)
假设我们想要发现 F 个隐类, 我们的任务就是找到两个矩阵 U 和 V,使这两个矩阵的乘积近似等于R,即将用户物品评分矩阵 R 分解成为两个低维矩阵相乘,如下所示:
然后定义损失函数,利用随机梯度下降法处理损失函数,求出U和V。
1、利用隐语义模型主要解决了以下问题
分类的可靠性。分类来自对用户行为的统计,代表了用户对物品分类的看法。
可控制分类的粒度。允许我们自己指定有多少个隐类。
- 将一个物品多类化。通过统计用户行为来决定某物品在每个类中的权重。
2、通过举例理解隐语义模型
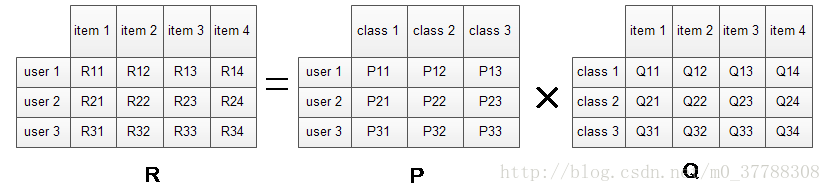
其中P矩阵是user-class矩阵,矩阵值Pij表示的是user i对class j的兴趣度;Q矩阵式class-item矩阵,矩阵值Qij表示的是item j在class i中的权重,权重越高越能作为该类的代表
ToyExample

User-Item Matrix
ToyExample的分解U、V

Class-User Matrix

Class-Item Matrix
注意:每次得到的U、V可能有所不同,原因是初始值是随机的。
ToyExample的预测
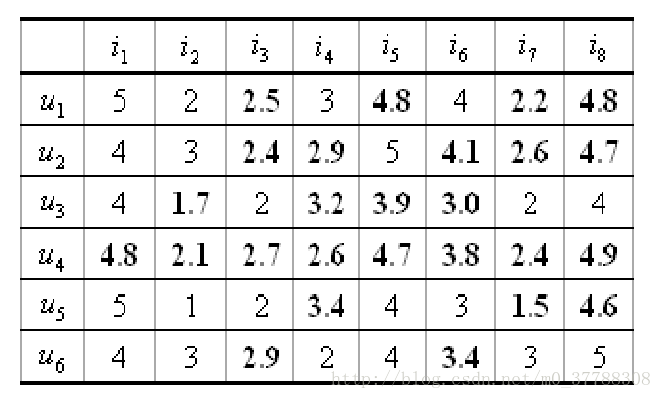
Predicted User-Item Matrix
3、隐语义模型核心代码分析

4、隐语义模型在实际应用的缺点
数据稀疏会导致性能降低。甚至不如UserCF和 ItemCF的性能。
不能在线实时推荐。因为LFM在生成推荐列表时速度太慢。
- 不能给出推荐解释。因为LFM计算的是各个隐类,但每个类别不会自动生成这个类的类别标签。
改进的隐语义模型
1、基于标签的隐语义模型
标签是一种表示用户兴趣和物品语义的重要方式,当一个用户对一个物品打上了一个标签,这个标签一方面描述了用户的兴趣,另一方面则表示了物品的语义,利用社交标签可以提高推荐的精度。
1.1、标签关系分解
TagRec算法、SoRecUser算法、SoRecItem算法。标签关系分解算法举例:
TagRec:同时考虑了用户物品评分矩阵,用户标签矩阵和物品标签矩阵,构建了一个统一的概率矩阵分解模型,用户的隐特征向量既可以从用户物品评分矩阵中学习,也可以从物品标签矩阵中学习。
缺点:标签存在质量不高和语义等问题。
1.2、标签关系不分解
NHPMF算法、TagiCoFi算法。标签关系不分解算法举例:
NHPMF:根据用户标签词频和物品标签词频分别计算用户最邻近和物品最邻近,然后将领域信息融入矩阵分解模型之中,同时对用户和物品的相似关系进行了传播。
缺点:标签存在质量不高和语义等问题。
2、基于社交的隐语义模型
利用社交信任来提高推荐精度。而且,通过社交信任,能缓解数据的稀疏性和冷启动问题。当一个新的用户几乎没有评分的状态下,使用相似度来计算相似用户几乎不可行,但是在系统中我们存在大量的社交信任关系的话,那我们就可以根据信任关系进行推荐。
2.1、社交关系分解
SoRec算法、CTRPMF算法。社交关系分解算法举例:
SoRec:假定社交关系矩阵表征了用户在社交网络中重要交互信息,对其进行分解可以学习到用户社交行为的低维潜在重要特征。通过共享用户隐特征向量空间把用户评分信息和用户社交信息联系起来,用户的隐特征向量既从用户物品评分矩阵中学习,又从用户社交矩阵中学习。
缺点:可能泄露用户隐私。
2.2、社交关系不分解
SocialMF算法、STE算法、RSTE算法、RWD算法、RWT算法。社交关系不分解算法举例:
SocialMF:根据用户之间的信任关系,在计算用户隐特征向量的时候,考虑了这个用户信任的用户对其隐特征向量的影响,同时对用户的信任关系进行了一步或者两步的传播。
缺点:可能泄露用户隐私。
3、基于时间的隐语义模型
利用时间信息来提高推荐精度。不同的时间,对应了用户、物品以及用户-物品的变化情况。通过分析这一系列的变化,做出合理的推荐。
3.1、时间关系分解
TimeSVD算法。时间关系分解算法举例:
TimeSVD:整个社会的兴趣随着时间在变化,用户的兴趣随着时间在变化,物品的流行度随着时间在变化,用户对物品的兴趣随着时间在变化。
缺点:在实时系统中,算法的可扩展性还不够好。
3.2、时间关系不分解
TimeSVD++算法、Sequential-MF算法。时间关系不分解算法举例:
SequentialMF:通过时序信息,构建用户物品之间的结构关系,建立了用户消费网络和产品消费网络。
缺点:在实时系统中,算法的可扩展性还不够好。
4、其他改进的隐语义模型
- 贝叶斯概率矩阵分解模型BPMF,采用马尔可夫链蒙特卡罗进行采样
- 隐语义模型的泛化表示形式——因子分解机FM(Factorization Machines)
- 贝叶斯因子分解机模型BFM
- …
研究趋势
1、标签:利用标签的迁移学习来做交叉领域的推荐。
例如,豆瓣网含有丰富的电影标签和评论的信息,但不提供电影服务;优酷网提供电影服务,但电影的标签和评论信息较少。
2、社交:社交信任传播算法与用户物品的评价结合。
社交信任包含了信任和不信任两种情况,根据不信任的关系来约束信任关系的传播。
3、时间:与其他信息相结合来做推荐。
例如,时间与位置信息相结合,来计算用户在特定时间,特定地方对物品的偏好程度。
4、其它:将隐语义模型与交叉领域推荐相结合。
例如,将深度信度网络DBN与概率矩阵分解PMF相结合做推荐。现在很多学者已经用深度学习来做推荐。
2016 RecSys大会
来自工业界的经验分享报告《Lessons learned from build real-life Recsys》
观点:MF是最好的single approach,MF的变形包括FM,SVD++,ALS等;Quora开源了他们的MF模型QMF
工业界推崇的矩阵分解技术
SVD++,factorization machine,ALS等
值得关注的几篇论文
1.Field-awareFactorization Machines for CTR Prediction
2.AreYou Influenced by Others When Rating? Improve Rating Prediction by ConformityModeling
3.Recommendingfor the World (Netflix)
4.Tutorial:Lessons Learned from Building Real-life Recommender Systems (Xavier’ tutorial)
参考文献
[1] 王升升, 赵海燕, 陈庆奎,等. 个性化推荐中的隐语义模型[J]. 小型微型计算机系统, 2016, 37(5):881-889.
[2] 项亮. 推荐系统实践[M]. 人民邮电出版社, 2012.
[3] MaH, Yang H, Lyu M R, et al. SoRec: Social Recommendation Using ProbabilisticMatrix Factorization[C]// ACM Conference on Information and KnowledgeManagement, CIKM 2008, Napa Valley, California, Usa, October. 2008:931-940.