MongoDB4.x优化
MongoDB架构
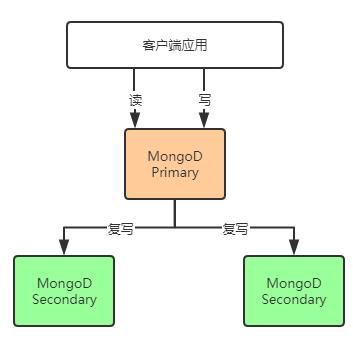
MongoDB是典型的C/S架构,数据库存储采用主从结构,应用发起的读写请求都落在主库上,如果是写入请求,主库提交之后,还会同步写入到对应的从库上,同步的具体方式是类似OpLog,主库+从库组成了一个副本集,是MongoDB最小的部署单位。
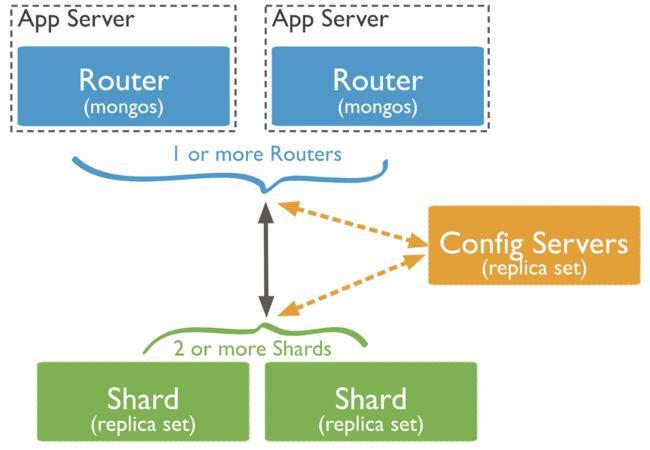
同时,MongoDB还支持较为复杂的集群方案,为用户解决元数据的高可用,业务数据的冗余和灾备(副本集来保证),动态自动分片,动态自动数据均衡等问题。典型的集群架构如下图所示:

上面的图表示的集群由两个副本集,一个配置服务器,两个MongoS路由器组成其中配置服务器是存放整个集群的元信息,本身不具备调度功能;MongoS路由负责负载均衡,当客户端请求到来时,MongoS需要把该请求路由到对应的副本集上。
分片
MongoDB分片集群将数据分布在一个或多个分片上。每个分片部署成一个MongoDB副本集,该副本集保存了集群整体数据的一部分。因为每个分片都是一个副本集,所以他们拥有自己的复制机制,能够自动进行故障转移。你可以直接连接单个分片,就像连接单独的副本集一样。但是,如果连接的副本集是分片集群的一部分,那么只能看到部分数据。
分片的信息可以基于库,也可以基于集合,对于大部分情况,我们都需要采用第二种情况,即把一个大的集合分片到若干个分片中,如下图:

分片的规则分为两种,第一种是根据分片键的范围来分片,比如把键的范围划分为4个部分,Chunk1包含(-INF,1),chunk2包含[1,20),chunk3包含[20, 99),chunk4包含[99,INF)之类;第二种是根据键的hash值来分片,通过一个Hash函数,把键较为均匀的方式分片到各个副本集上。
实际运用过程中,如果你的查询是基于类似范围的方式,那么可以采用范围分片,比如按照用户年龄来查询,此时如果用Hash来分片,那么就会导致数据库引擎去各个Shard上去查,然后再到MongoS上汇总,效率是比较低的。
数据访问和存储
MongoDB3.2引入了新的可拔插的存储引擎WiredTiger,支持按行级别的锁来并发访问,相比于之前的MMAP引擎来说,提升了不少性能。WiredTiger引擎支持数据的压缩存储,也提升了存储效率。下面重点解释一下WiredTiger引擎的实现原理:
按照MongoDB默认的配置,WiredTiger的写操作会先写入Cache,并持久化到WAL(Write ahead log),每60s或log文件达到2GB时会做一次Checkpoint,将当前的数据持久化,产生一个新的快照。Wiredtiger连接初始化时,首先将数据恢复至最新的快照状态,然后根据WAL恢复数据,以保证存储可靠性。
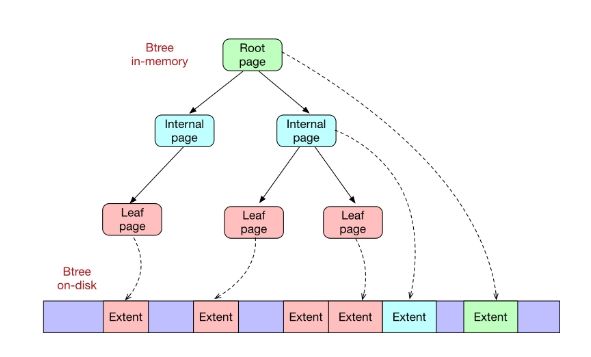
WiredTiger的Cache采用Btree的方式组织,每个Btree节点为一个page,root page是Btree的根节点,internal page是Btree的中间索引节点,leaf page是真正存储数据的叶子节点;Btree的数据以page为单位按需从磁盘加载或写入磁盘。
Wiredtiger采用Copy on write的方式管理修改操作(insert、update、delete),修改操作会先缓存在cache里,持久化时,修改操作不会在原来的leaf page上进行,而是写入新分配的page,每次checkpoint都会产生一个新的root page。

如上图所示,黄色节点是旧的节点,在进行Check point操作的时候,新的数据不会写入黄色的节点,而是把黄色的旧节点拷贝出来成为绿色的新节点,并在新的绿色节点上写入,每次Check Point之后,会生成一个新的Root Page节点,最后,WiredTiger会从新的Root节点开始把修改后的节点写入磁盘。这样的过程可以看得出来非常高效,首先不用修改旧的树,而在旧的树基础上生成新树,节省了许多修改旧树的时间;其次新生成的节点才写入磁盘,只把新节点写入到磁盘,不用修改旧的磁盘内容,虽然整个Btree的文件越来越大,但实时运行的过程中,只写入变动的数据保证了运行的效率
优化
针对键的优化
因为MongoDB是采用Free Schema存储的,没有地方专门存储Schema(类似MySQL的表结构),所以每一个文档中都有Schema,就是说文档中的每个键名都存储在文档中了,如果你的键名比较长,那么如果集合中的文档数量级很大,重复的长键名就会消耗大量空间,此时应该把键名缩短为1个或者2个字母,这样会减少很多内存消耗,有人做过一个实验,在16亿条文档的集合中,把键名从原来的长键名改为1个字母的短键名,存储空间就从原来占用243GB,下降为183GB,整整节约了60GB的存储空间。
_id的生成优化
MongoDB的集合新建立文档的时候,如果不指定_id键的值,系统会为你自动生成一个12字节的object ID,并且作为主键建立索引,但我并不推荐使用默认生成_id的方式,一个原因是因为12字节所占的空间太大了,我们完全可以自己生成主键_id的值,另外一个原因是系统生成这个object ID也需要花费一些计算代价。
解决的办法是我们自己生成_id的值,且不用在MongoDB上生成,在我们自己的服务上生成,例如用户uID,可以使用用户的登录名,昵称等业务唯一性标记来作为_id的值,具体可以参考一些唯一id生成算法。
Schema的设计
设计文档结构Schema的时候,有时需要考虑空间和时间的折中,例如对于用户信息的结构设计来说,如果是一个学生成绩的信息,比如数学多少分,英语多少分,科目这样的信息结构比较少,所以完全可以把它们嵌入到用户信息集合中,这样查找到用户之后,就可以直接访问各个科目的成绩。
如果是一个游戏玩家,拥有很多种不同属性值的卡牌,那么就不适合放入到玩家用户信息集合中,因为那样的话加载的冗余信息可能比较大,此时应该把卡牌信息专门做一个集合来存放,而在玩家信息里放入一个卡牌id的字段来对应,就能节省空间,虽然查找一个玩家拥有的卡牌信息时需要进行两次查询,那比起消耗较多的空间来说还是要划得来很多的。
总结起来就是优先考虑内嵌的方式,如果文档中的数据需要单独访问的时候,就可以考虑不使用内嵌,而放入其它集合。
压缩算法的选择
有两种压缩算法可以选取,分别是Snappy和Zlib算法,下面的图对两种算法进行简单说明:
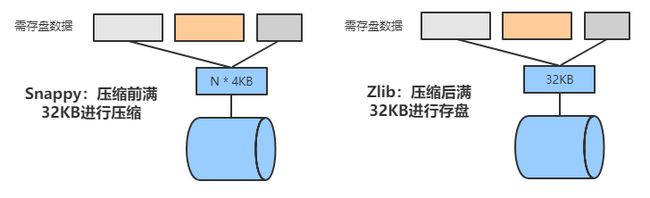
从上图可以看出,Snappy算法是根据压缩前的数据大小为单位来存盘,压缩前每满32KB进行压缩,然后存盘,而Zlib算法是先把数据进行压缩并临时存放,每满32KB存盘一次,实际运营中往往采用Zlib算法,因为它的数据存储结构更规整,这样访问效率会更高。
db.createCollection( "email", {storageEngine:{wiredTiger:{configString: 'block_compressor=zlib'}}})
插入100条数据:
db.email.insert({'name':4,'age':12,'remark':'aaaaa'})
数据大小
db.email.dataSize()
占用磁盘大小
db.email.storageSize()
db.stats();
"collections" : 3,表示当前数据库有多少个collections.可以通过运行show collections查看当前数据库具体有哪些collection.
"objects" : 13,表示当前数据库所有collection总共有多少行数据。显示的数据是一个估计值,并不是非常精确。
"avgObjSize" : 36,表示每行数据是大小,也是估计值,单位是bytes
"dataSize" : 468,表示当前数据库所有数据的总大小,不是指占有磁盘大小。单位是bytes
"storageSize" : 13312,表示当前数据库占有磁盘大小,单位是bytes,因为mongodb有预分配空间机制,为了防止当有大量数据插入时对磁盘的压力,因此会事先多分配磁盘空间。
"numExtents" : 3,似乎没有什么真实意义。我弄明白之后再详细补充说明。
"indexes" : 1 ,表示system.indexes表数据行数。
"indexSize" : 8192,表示索引占有磁盘大小。单位是bytes
"fileSize" : 201326592,表示当前数据库预分配的文件大小,例如test.0,test.1,不包括test.ns。丢数据问题
有人在使用MongoDB的过程中,发现有数据丢失的问题,主要是发生在2.6版本之前,是不是因为程序有bug?其实丢失数据的原因不是因为MongoDB有bug,而是因为MongoDB在版本较早或者用户配置的问题。
早于2.4版本的MongoDB,如果出现数据丢失,很可能是没打开恢复日志,这个参数在2.4前的版本默认是关闭的,如果运行过程中机器掉电而此时正在写入数据,那么就会导致重启后,最后本该写入的数据没有正常写入,解决办法就是打开恢复日志即可。
另外一个丢失数据的原因是用户配置项,称之为写关注(Write Concern),用来描述数据库写操作返回信息的保证级别,有3种选项,分别为0 - Unacknowledged、1 - Acknowledged、 majority - Replica Acknowledged,安全级别由低到高,早期版本默认配置是0,表示不管是否写入成功,都将立即返回,可以得到最大的性能,但丢数据的风险是最大的。如果不知道这一点,则可能会导致数据丢失
解决办法是把写关注配置为majority级别,让半数及以上的副本写入成功后再返回,这样丢数据的可能性就非常低了。下面的示意图展示了MongoDB写入的流程:

cfg = rs.conf()
cfg.settings.getLastErrorDefaults = { w: "majority", wtimeout: 5000 }
rs.reconfig(cfg)
也可以使用客户端指定策略,如下:至少要写入两个节点,超时时间是5s
db.products.insert(
{ item: "envelopes", qty : 100, type: "Clasp" },
{ writeConcern: { w: 2, wtimeout: 5000 } }
)大量删除数据的问题
如果在实际运行过程中,在某个时间点对一个集合进行了一个删除操作,但删除的内容是集合中的大量文档,例如对已读的文档进行统一删除,则会发生数据库假死的状态(CPU消耗过高),产生这个现象的原因是这个操作其实是一个遍历集合文档的操作,当数据量巨大的时候,还会发生热数据和冷数据反复交换的问题,所以耗时很长。
解决办法可以是以下两种,一个是在读取完文档后,同时执行删除操作,这样就不用在某个时候统一删除了;另外也可以把要删除的文档objectID导出来,然后用objectID来遍历删除,因为objectID是主键,有索引,所以删除速度还是很快的。
删除数据之后留下的空洞问题
一个库的集合长期运行之后,必然经历了多次删除,插入等操作,由于MongoDB的机制,被删除的数据在磁盘上并没有真正的删除,只是做了一个标记,称之为空洞,这些大量的空洞也会被加载到内存,导致内存的利用率降低,类似于磁盘碎片。
MongoDB提供了一个在线的空洞整理命令compact,针对表级别的空洞整理,但是这个命令的性能比较差,如果在线运行的时候,会影响用户的实际体验,推荐只在在线用户比较少的时候进行。
第二个方案是基于冗余库的方案,具体做法是先摘掉一个从库,然后把从库中的所有文档删除,然后再启动从库开始从主库同步,这样所有的文档都重新创立,自然从库的空洞就消失了,然后把这个从库提升为主库,把降为从库的主库再进行上面的步骤,这样就主库也完成了空洞整理过程。
use dmp_phone
db.dmp_phone.runCommand('compact');
或者 db.runCommand({ compact : 'dmp_phone'});