python机器学习——集成学习(分类)及“泰坦尼克号沉船事故”数据集案例操作
集成学习(分类)及具体案例操作
- 一、集成学习( Ensemble Learning )算法
- (1)集成学习简介
- (2)集成建模中的误差(方差vs偏置)
- (3)常用的集成学习技术:
- (4)随机森林
- (5)梯度提升决策树(Gradient Tree Boosting)
- 二、集成学习具体案例操作
- (1)导入数据
- (2)特征选择
- (3)数据清洗
- (4)划分训练集测试集
- (5)特征转换
- (6)建立模型及性能测试
- 参考文献:
一、集成学习( Ensemble Learning )算法
(1)集成学习简介
定义:所谓集成,是指结合不同的学习模块(单个模型)来加强模型的稳定性和预测能力。集成学习是使用一系列学习器进行学习,并使用某种规则把各个学习结果进行整合从而获得比单个学习器更好的学习效果的一种机器学习方法。
思路:在对新的实例进行分类的时候,把若干个单个分类器集成起来,通过对多个分类器的分类结果进行某种组合来决定最终的分类,以取得比单个分类器更好的性能。如果把单个分类器比作一个决策者的话,集成学习的方法就相当于多个决策者共同进行一项决策。
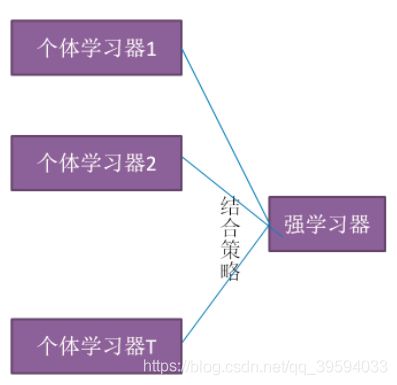
由上图可知,集成学习主要需解决的问题是如何得到若干个个体学习器,以及如何选择一种结合策略,将这些个体学习器集合成一个强学习器。
注意:集成学习的一个不可忽视的重点就是每个模型是弱分类器,并且每个模型之间最好存在一定的区别,也就是对不同的数据特征有自己的能力。之所以要的是弱分类器,是因为弱分类器以后的改进中还可以对那些原来分错的数据加大权重进行修改,这样写不断的迭代修改,可以保证一定的修改次数。
要获得好的集成,个体学习器应“好而不同”,即个体学习器要有一定的“准确性”,学习器不能太坏,并且要有“多样性”(即学习器间具有差异)。事实上,如何产生并且结合“好而不同”的个体学习器,恰是集成学习研究的核心。
理论支撑:多个模型集成的结果最差的情况就是和原来没有什么变化。
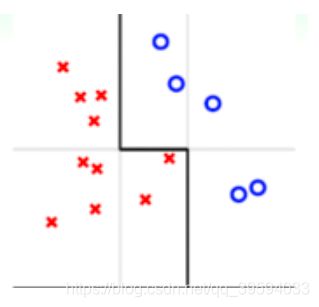
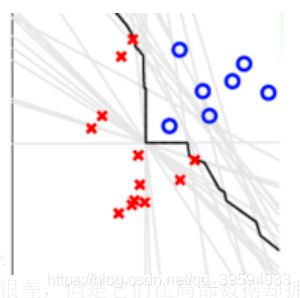
由上图,可以认为黑线是不同的模型集成的结果,而灰色比较暗淡的线条代表的是最初的模型,虽然在整个数据平面的能力很差,但是它们在局部数据却拥有表现自己的能力。集成学习算法本质上就是挑出局部数据平面分的最好的线条进行了组装,就得到了想要的线条。
导致模型不同的主要因素主要有:不同种类、不同假设、不同建模技术、初始化参数不同。
(2)集成建模中的误差(方差vs偏置)
任何模型中出现的误差都可以在数学上分解成:
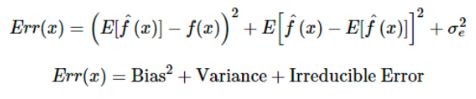
① 偏置误差:用来度量预测值与实际值差异的平均值,高偏置误差意味着模型表现欠佳,预测值和真实值差别很大。
② 方差:度量基于同一观测值,预测值之间的差异,高方差模型在训练集上会过拟合,并且在训练之外的任何观察表现都不佳,模型的稳定性不好。
下图可以更加直观的说明方差和偏置误差(假设红点是真实值,蓝点是预测值):
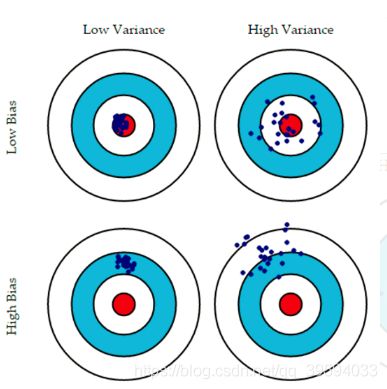
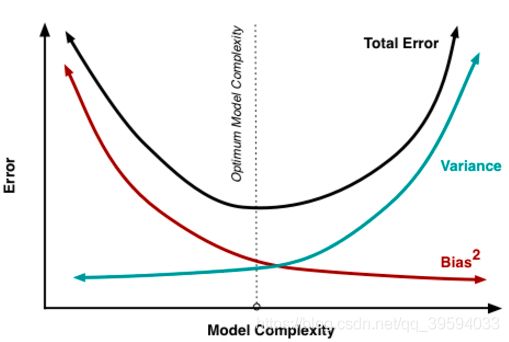
通常情况下,增加模型的复杂性时,由于模型的低偏置,错误减少,但是,这只在某个特定点之前才发生;当继续增加模型复杂性时,模型最终会过拟合,因此模型开始出现高方差。
一个优良的模型应该在这两种误差之间保持平衡,这被称为偏置方差的折衷管理。集成学习就是执行折衷权衡的一种方法。
(3)常用的集成学习技术:
① Boosting 算法
各弱分类器之间存在相互依赖:
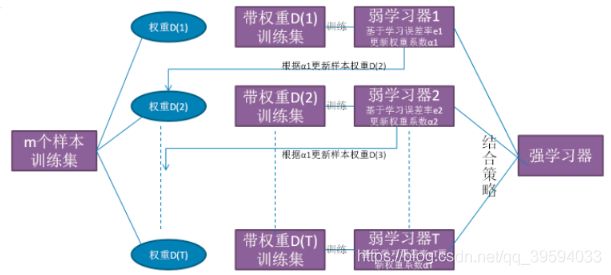
从图中可以看出,Boosting 算法的工作机制是首先从训练集用初始权重训练出一个弱学习器 1 ,根据弱学习的学习误差率表现来更新训练样本的权重,使得之前弱学习器 1 学习误差率高的训练样本点的权重变高,使得这些误差率高的点在后面的弱学习器 2 中得到更多的重视。然后基本调整权重后的训练集来训练弱学习器 2 。如此重复进行,直到弱学习器数达到事先指定的数目 T ,最终将这 T 个弱学习器通过集合策略进行整合,得到最终的强学习器。
Boosting 系列算法里最著名算法主要有 AdaBoost 算法和提升树( boosting tree )系列算法。提升树系列算法里面应用最广泛的是梯度提升决策树( Gradient Boosting Tree ) ,每一棵决策树在生成过程都会尽可能降低整体集成模型在训练集上的拟合误差。
② Bagging 算法:
Bagging 算法原理和 Boosting 不同,它的弱学习器之间没有依赖关系,可以并行生成:
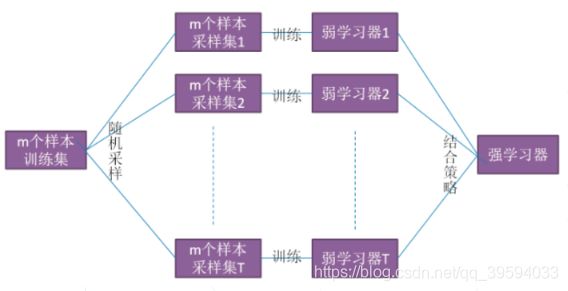
从上图可以看出,Bagging 的个体弱学习器的训练集是通过随机采样得到的。通过 T 次的随机采样可以得到 T 个采样集,对于这 T 个采样集,可以分别独立的训练出 T 个弱学习器,再对这 T 个弱学习器通过集合策略来得到最终的强学习器。
注:这里的随机采样一般采用的是自助采样法(Bootstap sampling),即对于 m 个样本的原始训练集,每次先随机采集一个样本放入采样集,接着把该样本放回,也就是说下次采样时该样本仍有可能被采集到,这样采集 m 次,最终可以得到 m 个样本的采样集,由于是随机采样,这样每次的采样集是和原始训练集不同的,和其他采样集也是不同的,这样得到多个不同的弱学习器。
Bagging 用于减少方差,Boosting 用于减少偏置误差。
(4)随机森林
随机森林(Random Forest,简称 RF) [Breiman, 2001a] 是 Bagging 的一个扩展变体。RF 在以决策树为基学习器构建 Bagging 集成的基础上,进一步在决策树的训练过程中引入了随机属性选择.具体来说,传统决策树在选择划分属性时是在当前结点的属性集合(假定有 d 个属性)中选择一个最优属性;而在 RF 中,对基决策树的每个结点,先从该结点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分. 这里的参数k 控制了随机性的引入程度;若令 k = d ,则基决策树的构建与传统决策树相同;若令 k = 1 ,则是随机选择一个属性用于划分; 一般情况下,推荐值 k = log2 d[Breiman,2001]。
随机森林简单、容易实现、计算开销小,令人惊奇的是, 它在很多现实任务中展现出强大的性能,被誉为"代表集成学习技术水平的方法"可以看出,随机森林对 Bagging 只做了小改动,但是与 Bagging 中基学习器的"多样性"仅通过样本扰动(通过对初始训练集采样)而来不同,随机森林中基学习器的多样性不仅来自样本扰动,还来自属性扰动,这就使得最终集成的泛化性能可通过个体学习器之间差异度的增加而进一步提升。
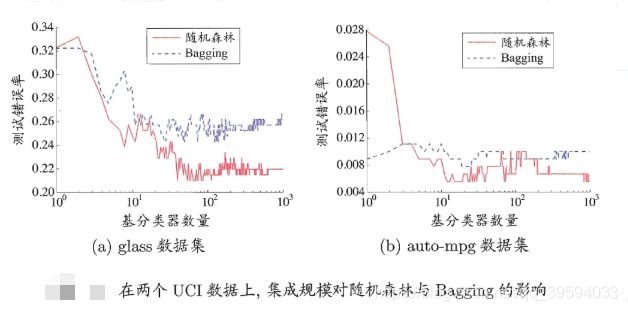
随机森林的收敛性与 Bagging 相似。如上图所示,随机森林的起始性能往往相对较差,特别是在集成中只包含一个基学习器时,这很容易理解,因为通过引入属性扰动,随机森林中个体学习器的性能往往有所降低然而,随着个体学习器数目的增加,随机森林通常会收敛到更低的泛化误差. 值得-提的是,随机森林的训练效率常优于 Bagging,因为在个体决策树的构建过程中, Bagging 使用的是“确定型”决策树,在选择划分属性时要对结点的所有属性进行考察,而随机森林使用的“随机型”决策树则只需考察一个属性子集。
注:这里的属性可以理解为特征或者是变量
(5)梯度提升决策树(Gradient Tree Boosting)
与构建随机森林分类器模型不同,这里的每一颗决策树在生成的过程中都会尽可能降低整体集成在训练集上的拟合误差。
GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案。它在被提出之初就和 SVM一起被认为是泛化能力较强的算法。GBDT中的树是回归树(不是分类树),GBDT用来做回归预测,调整后也可以用于分类。
提升树是迭代多棵回归树来共同决策。当采用平方误差损失函数时,每一棵回归树学习的是之前所有树的结论和残差,拟合得到一个当前的残差回归树,残差的公式:残差 = 真实值 - 预测值 。提升树即是整个迭代过程生成的回归树的累加。
提升树利用加法模型和前向分步算法实现学习的优化过程。当损失函数时平方损失和指数损失函数时,每一步的优化很简单,如平方损失函数学习残差回归树。但对于一般的损失函数,往往每一步优化没那么容易,如 Huber 损失函数。针对这一问题,Freidman 提出了梯度提升算法:利用最速下降的近似方法,即利用损失函数的负梯度在当前模型的值,作为回归问题中提升树算法的残差的近似值,拟合一个回归树。
二、集成学习具体案例操作
本文依然以“泰坦尼克号沉船事故”数据集为例:
(1)导入数据
# 导入 pandas 用于数据分析
import pandas as pd
# 利用 pandas 的 read_csv 模块直接从互联网收集泰坦尼克号乘客数据
titanic = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
(2)特征选择
#人工选取 pclass, age 和 sex 作为判别乘客是否能够生还的特征。
X = titanic[['pclass', 'age', 'sex']]
y = titanic['survived']
(3)数据清洗
# 首先我们补充 age 里的数据,使用平均数或者中位数都是对模型偏离造成最小影响的策略
X['age'].fillna(X['age'].mean(), inplace=True)
(4)划分训练集测试集
# 数据分割
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state = 33)
(5)特征转换
# 我们使用 scikit-learn.feature_extraction 中的特征转换器
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer(sparse=False)
# 转换特征后,我们发现凡是类别型的特征都单独剥离出来,独成一列特征,数值型的则保持不变
X_train = vec.fit_transform(X_train.to_dict(orient='record'))
print(vec.feature_names_)
# 同样需要对测试数据的特征进行转换
X_test = vec.transform(X_test.to_dict(orient='record'))
(6)建立模型及性能测试
① 单一决策树
# 从 sklearn.tree 中导入决策树分类器。
from sklearn.tree import DecisionTreeClassifier
# 使用默认配置初始化决策树分类器
dtc = DecisionTreeClassifier()
# 使用分割到的训练数据进行模型学习
dtc.fit(X_train, y_train)
# 用训练好的决策树模型对测试特征数据进行预测
y_predict = dtc.predict(X_test)
# 从sklearn.metrics 导入 classification_report
from sklearn.metrics import classification_report
# 输出预测准确性
print(dtc.score(X_test, y_test))
# 输出更加详细的分类性能
print(classification_report(y_predict, y_test, target_names = ['died', 'survived']))
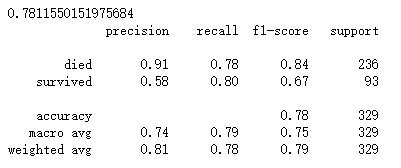
② 随机森林
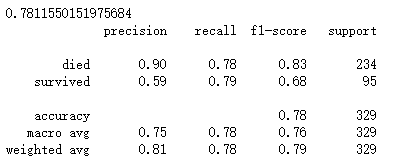
③ 梯度提升决策树
# 使用梯度提升决策树分类器进行集成模型的训练以及预测分析。
from sklearn.ensemble import GradientBoostingClassifier
gbc=GradientBoostingClassifier()
gbc.fit(X_train,y_train)
gbc_y_prde=gbc.predict(X_test)
# 输出梯度提升决策树预测准确性。
print(gbc.score(X_test, y_test))
# 输出梯度提升决策树更加详细的分类性能。
print(classification_report(gbc_y_prde, y_test, target_names = ['died', 'survived']))
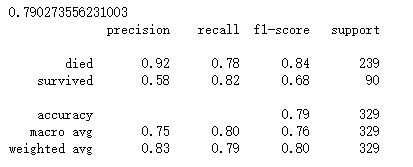
由上面的结果可知,在相同的训练和测试数据条件下,仅仅使用模型默认配置,梯度上升决策树具有最佳的预测性能,其次是随机森林分类器,最后是单一决策树。一般而言,工业界为了追求更加强劲的预测性能,经常使用随机森林分类模型作为基线系统(Baseline System 通常指那些使用经典模型搭建的机器学习系统)。
因此,集成模型虽然在训练过程中要消耗更多的时间,但得到的综合模型往往具有更高的表现性能和更好的稳定性。
参考文献:
[1] 李航. 统计学习方法[M]. 清华大学出版社, 北京, 2012.
[2] 周志华. 机器学习[M]. 清华大学出版社, 北京, 2016.
[3] 范淼,李超.Python 机器学习及实践[M].清华大学出版社, 北京, 2016.