Pandas学习汇总笔记(需要会numpy)
Pandas学习汇总笔记
- pandas最重要的6个知识点
- pd的3个基础数据结构(DateFrame,Series,Index)
- Series
- series的创建
- series的创建大概分为三种:
- Series的属性
- DataFrame
- DataFrame的创建
- Index对象
- pd的数值选择以及数值运算
- 如何取值
- series的取值
- (1)字典类的取值
- (2)numpy类方法的取值
- Dataframe的取值
- 字典类的取值(重点和Series的区别)
- numpy方式的取值(df结构)
- pd数据结构的运算
- 缺失值的处理
- 处理缺失值的一般方法(pd选择的方法)
- pd处理缺失值的具体方法
- 缺失值nan的简单介绍
- pd内置的缺失值处理函数(可以用pd调用,也可以数据结构(df)进行调用):
- iloc,loc,ix(索引函数)
- 层级索引:最核心知识点一
- Multiindex的四种创建方法
- pd的多级标签
- 多级索引的取值和切片
- 多级Series的取值和切片
- 多级Dataframe
- 多级索引的聚合
- unstack和stack以及set_index,以及其他一些多级索引的细节操作
- 合并数据集(concat和Merge):最核心知识点二
- GroupBy和数据透视表(pivot_table):最核心知识点三
- 高性能的pandas:eval()和query()
pandas最重要的6个知识点
由于现实的数据往往都是有关联性的,仅仅使用numpy的结构化数组结构当然是不够的,在此基础上pandas做出了极大的使用提升,所以有必要对pandas的核心功能做一个汇总学习;
在对全书的pandas知识进行了一次比较系统的学习之后,私以为pandas使用过程当中主要需要掌握6个核心知识点,掌握了这6个核心知识点之后,熟练的使用和理解pandas就变得极为容易:
- pd的3个基础数据结构(DateFrame,Series,Index)
- pd的数据选择和数值运算(与numpy对比)
- 层级索引(核心知识点一)
- 合并数据集(concat,merge)(核心知识点二)
- GroupBy和数据透视表(核心知识点三)
- pandas的高性能函数:eval()与query()
在这篇文章当中不对pandas的处理字符串数组和处理时间数据进行总结,因为感觉这两个知识完全是独立的,在使用的时候也只需要进行查阅就可以了;
pd的3个基础数据结构(DateFrame,Series,Index)
Series
(1)pd的数据结构当中最重要的属于DateFrame,因为我们基本上就是处理二维甚至多维的带有标签和索引的数据;而DateFrame可以看作Series组合而成的一种数据结构;
(2)所以学习Series的相关操作是极为重要的;
其实对Series的操作记住两点,就很容易理解和使用它的操作:
- 它的value属性,即它的值相当于numpy的数组加上了一个索引,numpy本身也有索引但是是隐性的,而它既有显式的,又有隐式的,同时,在使用索引进行获取值的时候,直接取值默认使用显式索引,切片默认隐式索引,并且使用显式索引的时候包含后面的值,使用隐式索引的时候不包含后面的值;对Series的操作完全可以当作一个numpy一维数组进行操作,它会自动对齐索引,且计算后也会保留索引;
- 它是一个字典结构,其键为它的索引,值为Series中的值;
series的创建
series的创建大概分为三种:
(1)data是一个列表或者numpy数组,这种情况就直接指定后面的index索引,或者使用默认的数字索引都可以;
print("采用指定index的方式创建:")
data_index = pd.Series([7,6,3,4,5,7],index=['a','b','c','d','e','e'])
print(data_index)
(2)data是一个标量,这个时候Series就会根据index数组,对每个index都给与标量相同的元素;
print("采用标量的方式创建:")
data_index = pd.Series(6,index=['a','b','c','d','e','e'])
print(data_index)
(3)data是一个字典,这个时候索引就默认是键,值默认是每个键对应的值,并且这个时候的index只能实现筛选字典当中值的功能;
print("采用字典的方式创建Series:")
data_zidian = pd.Series({'a':1,"b":3,'e':9})
print("data_zidian:",data_zidian)
data_zidian_2 = pd.Series({'b':1,'a':3,'e':9},index=[5,'b',7])
print("data_zidian_2:",data_zidian_2)
Series的属性
| 属性名 | 意义 |
|---|---|
| index | 索引列表 |
| value | 值列表 |
| index的修改函数为reindex(index)对所有索引进行修改或者添加索引 | 通过字典形式进行修改data[‘索引a’]=new_value |
DataFrame
pd最常用的数据结构,我们在现实中所处理的几乎所有的数据都是DateFrame结构;
对于DataFrame的操作我们也是主要理解两点:
(1)DataFrame的每一列都相当于一个Series;numpy数组的所有操作它也全部适用,同时保留索引和默认进行索引对齐
(2)DataFrame也是一个字典结构,不过和Series不同的是,这里的键是标签,即列索引,(一般情况下我们称呼行索引为索引,列索引为标签,但其实两者没有本质区别),同时Dataframe想要获取行数据的话,就得采用切片的方式或者转置dataframe之后让索引变成标签然后取这里的列(相当于以前的行),或者就直接获取value属性的numpy数组;
DataFrame的创建
dataframe的创建一共有四种方式:
(1)pd.Dataframe(SeriesA,colums=[‘biaoqianA’])
(2)pd.Dataframe({‘a’:SeriesA,‘b’:SeriesB}//里面的series也可以是列表或者numpy一维数组;
(3)pd.Dataframe(A,columns=columns,index=index)//A是一个二维数组
(4)pd.Dataframe(A)//A是一个结构化数组,创建后其类型名默认为列标签,行索引自动创建;
Index对象
其操作和numpy数组完全一致,不过它不可改变;,后面层级索引会有一个MultiIndex对象,用于创建层级索引Dataframe;
pd的数值选择以及数值运算
在使用pandas的数据结构当中,肯定需要明白的两点就是该数据结构当中如何进行取值以及如何进行运算量大点;
如何取值
series的取值
(1)字典类的取值
字典类的取值主要有两种,这两种方式都是直接将Series看作字典结构(索引和值的键值对);
- 通过索引取值
print("采用指定index的方式创建:")
data_index = pd.Series([7,6,3,4,5,7],index=['a','b','c','d','e','g'])
print(data_index['e'])
输出:

2. 通过新索引增加值
print("采用指定index的方式创建:")
data_index = pd.Series([7,6,3,4,5,7],index=['a','b','c','d','e','g'])
data_index['f']=9
print(data_index)
输出:

这种方式会直接在series中创建新的一个键值对,但是不会自动排序
(2)numpy类方法的取值
对于pd的数据结构,由于pd就是在numpy的基础上建立的,所以numpy的所有取值操作,pd都支持:
- 掩码
print("==========")
print("采用指定index的方式创建:")
data_index = pd.Series([7,6,3,4,5,7],index=['a','b','c','d','e','g'])
print(data_index[data_index>5])
输出:

2. 花哨索引
print("==========")
print("采用指定index的方式创建:")
data_index = pd.Series([7,6,3,4,5,7],index=['a','b','c','d','e','g'])
print(data_index[['a','b']])
输出:

3. 切片
print("==========")
print("采用指定index的方式创建:")
data_index = pd.Series([7,6,3,4,5,7],index=['a','b','c','d','e','g'])
print(data_index['a':'c'])
输出:

在切片这里有一个很重要的点就是**iloc,loc和ix;**在对Dataframe和series的介绍完成后单独对这个地方进行总结;
Dataframe的取值
字典类的取值(重点和Series的区别)
字典的操作我们已经很熟悉了,但是dataframe中的字典结构和Series又有区别,series中是索引和数据构成键值对;
而dataframe中是标签(列索引)和列Series构成键值对;
实例:
df字典类的取值:
print("=======================")
population_dict = {'California':38332521,
'Texas':26448193,
'New York':19651127,
'Florida': 19552860,
'Illinois':12882135}
population = pd.Series(population_dict)
area_dict = {'California':423967,
'Texas':695662,
'New York':141297,
'Florida': 170312,
'Illinois':149995,
'test':13213}
area = pd.Series(area_dict)
states = pd.DataFrame({'population':population,
'area':area})
print("states:")
print(states)
print("states['area']:")
print(states['area'])
输出;
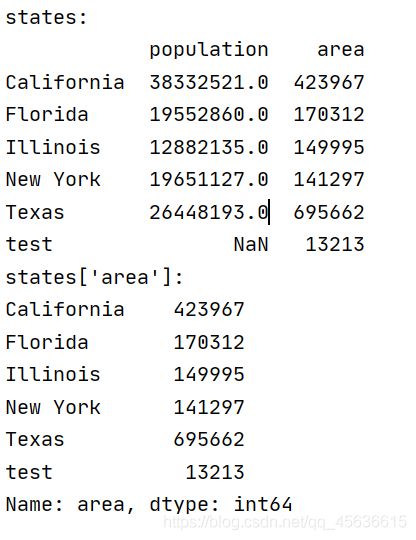
从这里可以看出与列标签键所对应的是一个Series;
df字典类的添加值:
states['midu']=states['population']/states['area']
print(states)
输出:
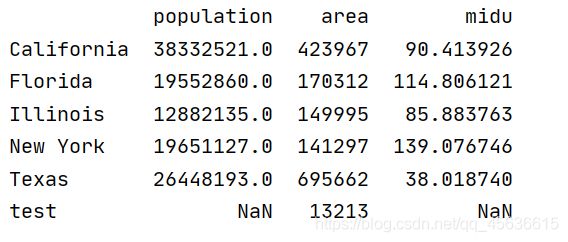
同时,df已经不再支持通过行索引取值,其想要取一行的值只能通过切片:
错误:
print(states['California'])
输出:
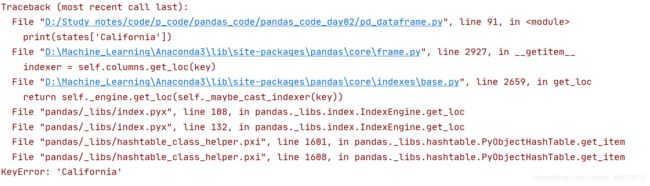
正确(由于使用显式索引切片就会包含后面的块,所以这里使用隐式索引):
print(states[0:1])

当然print(states[‘California’:‘California’]),也可以达到相同的效果;
numpy方式的取值(df结构)
与Series一样,numpy二维数组支持的所有取值方式df都支持,且它会自动保存索引;
参考numpy和Series,这里不再一一演示;
pd数据结构的运算
其运算和numpy别无二至,主要记住以下三点:
(1)其运算会保留索引和列标签
(2)或默认进行索引对齐,只有索引(行索引)相同的数据才会进行运算
(3)Dataframe和Series运算时候,和numpy类似,默认axis=1,进行列运算,并且索引也会自动对齐,默认情况下行索引和列标签都会进行对齐;
缺失值的处理
因为字写的太丑了,这里对pd的缺失值处理做一个详解:
- 处理缺失值的一般方法和pd选择的方法
- pd处理缺失值的具体方法
- 缺失值nan的简单介绍
- pd内置的缺失值处理函数
处理缺失值的一般方法(pd选择的方法)
(1)使用覆盖全局的掩码
使用掩码的方式将缺失值的值隐藏起来,可以使用pd的内置缺失值处理函数,pd.isnull()函数获取逻辑矩阵;
print(pd.isnull(states))
输出:

在使用isnull函数之后会返回一个矩阵,是nan的地方就返回一个true,然后再把这个矩阵传到原来的矩阵里就实现对缺失值的全局覆盖;
pd处理缺失值的具体方法
(1)用标量值(nan或极大极小的数值例如-9999)对缺失值进行填充;pd.finllna(Data)函数就能实现;
(2)pd采用NaN和none值对缺失值进行填充,对象类型的数组确实值就是none,并且一般字符数组的类型就是Object类型;
pd会(1)将整数类型的缺失值转化成np.nan;
(2)将布尔类型的缺失值转化成none和np.nan;
(3)对浮点型和object类型不进行改变;
(4)同时,pd等价看代none和np.nan,必要时会进行自动替换;
缺失值nan的简单介绍
(1)nan与任何值运算值都是nan
(2)nan和其他值进行比较的时候,它既是最大值,也是最小值
(3)调用时采用np.nan
pd内置的缺失值处理函数(可以用pd调用,也可以数据结构(df)进行调用):
| 函数名 | 效果 |
|---|---|
| isnull() | 返回一个bool矩阵,其中是nan的地方返回true |
| notnull() | 与isnull效果相反 |
| dropna | 剔除缺失值 |
| fillna | 填充缺失值 |
dropna函数原型:
DataFrame.dropna(axis=0, how=‘any’, thresh=None, subset=None,
inplace=False)
(1)其中,axis指定对行数据进行处理,删除数据也是一行一行删除;
(2)how有两个参数‘any’和’all‘,any代表有缺失值则删除该行或者列,all,代表全是缺失值的时候才剔除;
(3)thresh参数指定一行数据当中至少要有thresh个有效值才不会被剔除;
fillna函数原型:
DataFrame.fillna(alue=None, method=None, axis=None, inplace=False,
limit=None, downcast=None, **kwargs)
(1)需要注意的是method参数,它有两个可选值:’ffill‘和’bfill‘
(2)ffill:从前往后填充
(3)bfill:从后往前填充
(4)如果从前往后填充第一个值是缺失值,第二个也是缺失值,那么调用这个函数之后,依然存在缺失值,bfill同理;
iloc,loc,ix(索引函数)
在对pd数据结构的取值当中,很容易发现由于pd的默认隐式索引是整数类型的Indexrange结构,如果这个时候显式索引也是一样的整数类型的话,很容易在取值时候就发生歧义;
例如:
print("==========")
print("使用numpy数组创建:")
data_numpy = pd.Series(['a','b','c','d','e','g'],index=[2,3,4,5,6,7])
print("data_numpy[2]: ")
print(data_numpy[2])
这个时候是输出索引2对应的数据呢,还是输出索引3对应的数据,来看输出:

输出的是索引2对应的数据;
再来看切片:
print(data_numpy[2:4])
输出:
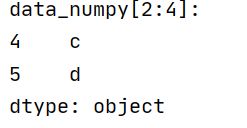
如果按照上面的理解使用显方式索引,那么应该输出的是‘a’,‘b’,‘c’(因为pd显示索引的切片会包含后面);
可以发现很容易就会搞混淆,索引pd采用了iloc来直接调用隐式索引,用loc来调用显示索引,但是一般如果不调用的话,默认取值是显示索引,切片是隐式索引;
代码实例:
print("data_numpy.iloc[2]: ")
print(data_numpy.iloc[2])
输出:

iloc调用隐式索引,所以是c
print("data_numpy.loc[2]: ")
print(data_numpy.loc[2])
输出:
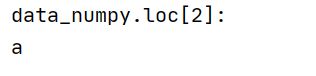
loc调用显式索引,所以直接是2所对应的a;在切片操作中也同理;
层级索引:最核心知识点一
我们之前学习的pandas的最高维度数据的表示数据结构就是DataFrame,以我们目前所学习的知识而言,一般它只能表示二维的数据;
pandas最普通的DataFrame:
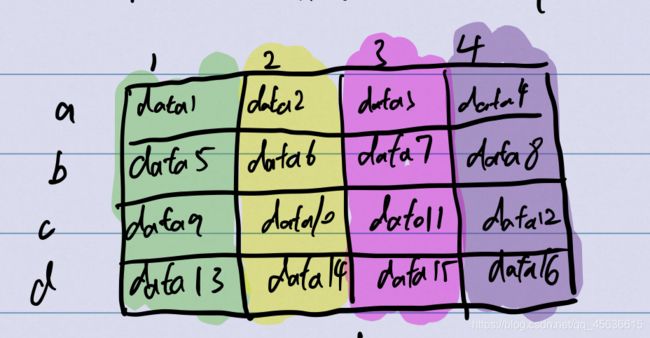
如果想要表示更高维度的数据,很简单,首先把这个dataFrame使用更低维度的表示方法,例如,转换成这样的series:
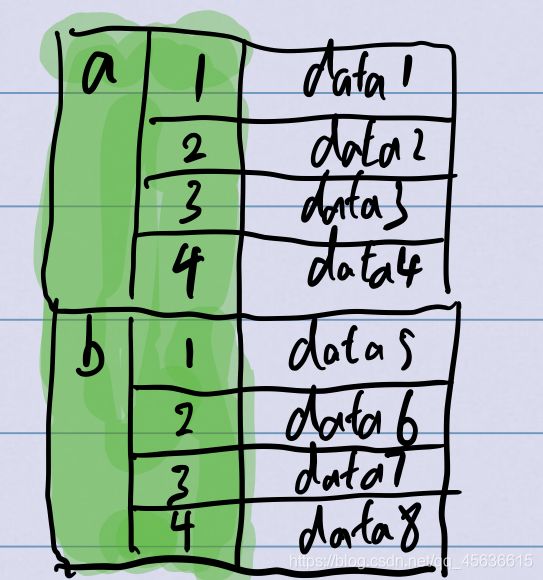
容易发现,下面这个结构使用Series就表达了二维的数据结构,用这个思想,我们很容易就用pd中原本只有1,2维度数据结构的Series和Dataframe表示各种更高维度的数据,在pd中内置了两个方法进行这种转换:stack()方法和unstack()方法,后面会单独对它们进行总结;
那么,pd是如何实现这种结构上的转换呢,使用最笨的办法:
(1)先创建index=[(‘a’,1),(‘a’,2)…]这样的元组结构;
(2)然后创建一个series,指定index为上面的元组列表;
最终变成:
(‘a’,1) data1
(‘a’,2) data2
…
这样的结构,很容易发现这样结构的取值非常不方便,需要取到所有a索引的数据时,需要将所有的带有a索引的元组传进去,data[(‘a’,1),(‘a’,2),…]这样,显然是不行的,pd中对这种结构进行了专门的涉及:
Multiindex的四种创建方法
pd中创建多级索引的方法也很简单,那就是指定index为MultIndex对象,系统会自动创建拥有多级索引结构的datafram或者Series;
比如上面的结构,使用下面的代码就可以轻松实现:
print("===========")
multiIndex = pd.MultiIndex.from_product([['a','b'],[1,2,3,4]])
data = pd.Series(['data'+str(i) for i in range(1,9)],index=multiIndex)
print(data)
输出:

在想要获取所有的a索引的值时,直接:
print(data['a'])
输出:

就获得了所有的a索引的值列表;
所以创建多级索引的主要是MultiIndex对象的创建:
(1)pd.MultiIndex.from_array([[‘a’,‘a’,‘a’,‘a’,‘b’,‘b’,‘b’,‘b’],[1,2,3,4,1,2,3,4]])//pd从数组创建多级索引,其多级索引会是列表中两个列表对应值的组合;
(2)pd.MultiIndex.form_tuples([(‘a’,1),(‘a’,2),(‘a’,3),(‘a’,4),…])//从元组列表创建,和最笨的方法类似,但是创建之后的效果不一样,系统将其转换成MultiIndex对象;
(3)pd.MultiIndex.form_product([[‘a’,‘b’],[1,2,3,4]])//系统根据列表当中两个列表的乘积创建多级索引对象,也是我们刚刚所使用的方式;
(4)pd.MultiIndex(levels=[[‘a’,‘b’],[1,2,3,4],codes=[[0,0,1,1],[0,1,2,3,0,1,2,3]]])//这种通过levels和codes的方式创建,levels相当于给出各个级别索引列表,越在前面索引级别越高,codes相当于给出多级索引的结构,这种方式非常灵活,能实现大部分结构,且代码量也相对较少;
注意:除了这4种multiindex的创建方法外,pd还有一种直接从字典创建多级索引的方式,下面给出代码示例:
print("====================")
data = pd.Series({('a',1):'data1',('a',2):'data2',('a',3):'data3',('a',4):'data4',
('b',1):'data5',('b',2):'data6',('b',3):'data7',('b',4):'data8'})
print(data)
输出:
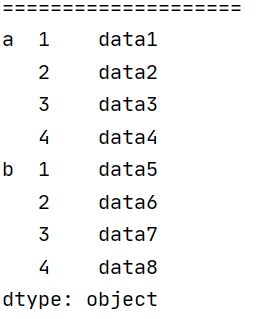
也可以实现这种结构,不过比较原始,知道就行;
pd的多级标签
多级标签和多级索引原理完全相同,且它所使用的创建媒介对象也是MultiIndex对象;
print("===============")
print("同时创建多级行索引和多级列索引:")
multiIndex_hang = pd.MultiIndex.from_product([['a','b'],[1,2]])
multiIndex_lie = pd.MultiIndex.from_product([['A','B'],[1,2]])
data_vec = np.full((4,4),'data')
data = pd.DataFrame(data_vec,index=multiIndex_hang,columns=multiIndex_lie)
print(data)
输出:

多级索引的取值和切片
多级Series的取值和切片
(1)与普通的Series取值唯一不同的是需要传入多级的索引编号,例如data[a,2],代表取到一级索引a索引的二级索引2当中的值;
(2)同时如果只传入一级索引,比如data['a'],会得到a索引下所有的数据组合而成的新的Series对象;
(3)其切片和花哨索引都完全支持,唯一需要注意的是1对二级索引的切片,不能直接A【a,:】,必须写A【‘a’】.loc[:]//其切片默认支持隐式切片;
这里自己做个实验就行了,不再给出实例;
多级Dataframe
(1)与多级Series极为类似,主要记住它的字典结构是列索引和列Seris的;
(2)多级DataFrame的使用,在标签部分和Series完全一致;
(3)多级Dataframe的切片操作IndexSlice对象
示例代码:
取一行的值:(一定记住pd的DataFrame的结构要获得行的值只能通过切片,当然用value属性获取numpy数组当然也是可以的)
print(data[0:1][0:1])//因为dataframe的行只能通过切片获得
输出:

取一列的值:
print(data['A'][1])
输出:
对Dataframe的精准取值:
通常采用传入元组对的方式:
例如:
print(data.loc[('a',1),('A',1)])
注意传入元组对的时候,必须使用显式的方式进行调用,即使用loc函数;
出现的问题就是当我们要进行元组内切片的时候:
print(data.loc[('a',1:2),('A',1)])
输出:

系统会直接报错,那怎么解决呢,pd内置了一个IndexSlice对象来实现元组对内的切片;
idx =pd.IndexSlice
print(data.loc()[idx['a',1:2],idx['A',1]])
输出:

需要注意的是,IndexSlice的使用也必须使用loc调用;
多级索引的聚合
(1)原本的所有聚合函数都适用;
(2)但是在原本的聚合函数基础上会多出两个可设置参数,level和axis;
主要对level参数进行解析:
原本的axis参数我们在numpy当中已经进行了学习,而level参数,下面一个实例:
print("===============")
print("同时创建多级行索引和多级列索引:")
multiIndex_hang = pd.MultiIndex.from_product([['a','b'],[1,2]])
multiIndex_lie = pd.MultiIndex.from_product([['A','B'],[1,2]])
data_vec = np.full((4,4),1)
data = pd.DataFrame(data_vec,index=multiIndex_hang,columns=multiIndex_lie)
print('data:')
print(data)
data.index.names =['suoyin1','suoyin2']
data.columns.names = ['biaoqian1','biaoqian2']
print(data.mean(level='suoyin1',axis=0))
输出:

可以发现它对索引列进行了统计,另外一个需要注意的点就是当axis=0的时候,它会在行索引当中寻找level名称,如果设置了行索引等级名,却设置axis=0,则系统报错;
默认情况下是多所有列标签进行统计:
print(data.mean())
输出:

unstack和stack以及set_index,以及其他一些多级索引的细节操作
(1)unstack函数和stack函数的功能完全是相反的,unstack函数的功能就是将行索引转换成列索引,看这个例子;
print("同时创建多级行索引和多级列索引:")
multiIndex_hang = pd.MultiIndex.from_product([['a','b'],[1,2]])
multiIndex_lie = pd.MultiIndex.from_product([['A','B'],[1,2]])
data_vec = np.full((4,4),1)
data = pd.DataFrame(data_vec,index=multiIndex_hang,columns=multiIndex_lie)
print('data:')
print(data)
print('data.unstack:')
print(data.unstack())
输出:

可以发现,unstack默认将二级行索引转换成了列索引;这就是unstack默认的功能,其中,还有一个level参数,用于指定需要转换的索引级别,默认level是指向最低一级的索引,我们手动将level改成0,看看效果:
print(data.unstack(level=0))
输出:

可以看到它就将一级行索引转换成了列索引;stack函数的功能与其完全相同,只是stack做的是列标签转换为行标签的功能;
(2)在pd的多级索引当中还有几个函数需要了解一下,set_index,reset_index,和索引的等级名称设定方法
- set_index(【‘biaoqian1’,‘bianqian2’】),函数set_index会将传入的列标签那一列作为新的行索引,如果是传入多列都生成多级索引;
- reset_index(level=0),这个函数实现的是将索引列变成数据列,其如果有等级名,则将等级名变成列标签。没有则默认为level+等级;和set_index实现完全相反的功能
- 对等级名的设置,主要是调用index和column的names属性进行直接赋值;
例如:
data.index.names=['l1','l2']
输出:

而columns的等级名称设置也是同理:column.names属性进行赋值;
(3)另外pd.Panel和pd.Panel4D两个对象可以了解一下;一般是Series和Dataframe就够用了:
Panel相当于Series的三维形式
Panel相当于Dataframe的四维形式
合并数据集(concat和Merge):最核心知识点二
GroupBy和数据透视表(pivot_table):最核心知识点三
