reactor.netty.http.client.PrematureCloseException: Connection prematurely closed BEFORE response解决方案
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://lovnx.blog.csdn.net/article/details/107900585
一、背景
可能大家在使用Spring Cloud Gateway构建微服务网关的时候,过五关斩六将,Reactor没能难倒我们,链路追踪没能难倒我们,最后在上线之后发现许多奇妙的问题,这些奇妙的问题还无从下手,比如这个堆栈,深入使用过SCG的人一定不会陌生:
reactor.netty.http.client.PrematureCloseException: Connection prematurely closed BEFORE response
Suppressed: reactor.core.publisher.FluxOnAssembly$OnAssemblyException:
类似的还有:
Connection prematurely closed DURING response 。。。等等
百度了一圈,鲜有人提供解决方案,有条件的Google了一把,跟着官方调整几个参数,有用没用也不得而知,最后反正就不了了之。
二、如何找答案
去SCG官方Issue中查找一番,还不少,(这里插一句,遇到问题可以先找前人的Issue,尽量不要提一些重复的问题,美德永存!)
然后发现了一句:
看来问题的根因不是在SCG,按照以往的经验来看,Spencer Gibb老铁是个实诚人,知之为知之,不知为不知,深得儒家精髓。召唤了Reactor-Netty的@violetagg,由此,我们知道了这个问题要去 https://github.com/reactor/reactor-netty/issues找答案了。其实题主也一样,在Reactor-Netty下面也没怎么搞明白这个错误的产生原理,正好全局异常处理器可以捕获到这个异常,给调用方返回一个请求第三方出错的统一结果,也不痛不痒。But,我是不会让这种不明不白的问题程序上线的!其实仔细阅读Reactor-Netty项目的Issue会总结出一些关键点,除了@violetagg指导大家如何如何切debug模式,如何如何找channel id之外,有一些总结性的话,我贴在下面,大家细品:
第一段:
I would recommend to configure maxIdleTime on the client side having in mind the keepAliveTimeout on Tomcat. Without such configuration Reactor Netty can receive the close event at any time between acquiring the connection from the pool and before actual sending of the request. Also you might want to switch to LIFO leasing strategy so that you will use always the most recently used connection.
第二段:
The connection is closed by Spring Framework WebClient’s new change for disposing the connection when a cancellation happens
第三段:
the connection was closed while still sending the request body
其实问题最本质的原因就是一个正常的请求在一些情况下被突然关闭了,当然能够get到这个点的老铁和题主一样脑袋中也出现了更多的问号:“一些情况”是嘛情况?为什么会被关闭?这样的问题出现频率不高,如何有效复现?why???
在众多的Issue中,你一定也会注意到,这个异常和Reactor-Netty内部的HttpClient有莫大的关系。
三、原因剖析
SCG官方文档有说,设置请求第三方服务的连接超时和读取超时实际上是设置的org.springframework.cloud.gateway.config.HttpClientProperties类属性,接着挖下去,HttpClientProperties其实就是提高配置能力,为初始化reactor.netty.http.client.HttpClient做门面,其实这个配置类和你知道的HttpClient没啥直接关系,它只是模拟出了类似HttpClient该有的一些机制,譬如连接池(使用过HttpClient的老铁在线上出幺蛾子的时候一定也把玩过它的连接/线程池参数)机制,HttpClientProperties里面的pool属性就是设置连接池相关的属性的。
看到这里,你只需要知道,SCG的底层Reactor-Netty会为请求实例创建连接池,以便后面发起请求不用重新创建请求,直接从中获取即可。其实这也就是问题的根因,看下面的时序图你就明白了:
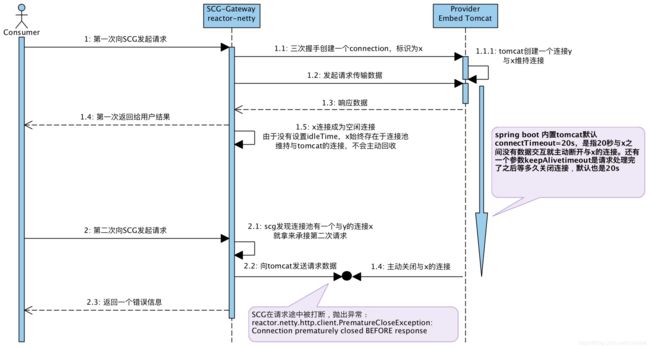
这里使用一个Spring Boot内置Tomcat作为服务提供方,用户通过SCG访问,SCG代理请求。
默认情况下,SCG内部创建的连接是不会被回收的,一直存在于内存中,而Spring Boot内置的Tomcat不一样,默认在20s之后没有数据交互,便会回收掉这个连接,在回收的时候恰巧碰到又来了请求,刚好又在SCG拿到这个连接来尝试请求Tomcat,就会出现这个异常。
所以,不要指望在Reactor-Netty或是SCG中解决这个问题,这需要网关和后端服务配合解决,最大限度不出现这个异常。
四、解决方式
从上文的第一段原话就有解决方案:
第1步、加入JVM参数 -Dreactor.netty.pool.leasingStrategy=lifo
第2步、SCG新增配置:
spring:
cloud:
gateway:
httpclient:
pool:
maxIdleTime: 10000(根据需要调整)
第1步将默认获取连接由FIFO变更为LIFO,因为LIFO能够确保获取的连接最大概率是最近刚被用过的,LRU的思想。
第2步是设置空闲请求在空闲多久后会被回收,这样也就可以避免拿到旧连接刚好在请求途中被强行close了,这个时间的设置只要确保比你后端服务的connectTimeout小就行了,这样能够确保SCG回收请求在后端服务回收请求之前,就可以避免掉这个问题。
这样设置后还会偶发这个异常,请排查你的所有后端服务是否connectTimeout都比maxIdleTime大,或者尝试调整maxIdleTime。另外,本身这是个概率性偶发问题,题主这样设置后,几乎看不到这个异常出现了,彻底根除这个顽疾,请看懂时序图再提问题。
版本说明:
题主之前使用的SCG版本是Greenwich.SR2版本,对应的Spring Boot版本是2.1.6.RELEASE,这个版本对应的Reactor-Netty版本是v0.8.9.RELEASE,这个版本的Reactor-Netty是没有提供设置maxIdleTime这个选项的。
Reactor-Netty是在v0.9.5.RELEASE版本开始提供设置
所以以上的配置请下面的版本当中使用:
Spring Cloud:Hoxton.SR1及以上(SCG 2.2.1.RELEASE及以上)
Reactor-Netty:v0.9.5.RELEASE及以上
Spring Boot:2.2.2.RELEASE及以上
单纯使用Reactor-Netty的同学也可以在reactor.netty.resources.ConnectionProvider找到配置方式。