模型融合方法
模型融合是kaggle等比赛中经常使用到的一个利器,它通常可以在各种不同的机器学习任务中使结果获得提升。顾名思义,模型融合就是综合考虑不同模型的情况,并将它们的结果融合到一起。模型融合主要通过几部分来实现:从提交结果文件中融合、stacking和blending。
从提交结果文件中融合
最简单便捷的方式就是从竞赛的提交结果文件中进行融合,因为这样做并不需要重新训练模型,只需要把不同模型的测试结果弄出来,然后采取某种措施得出一个最终结果就ok。
多数表决融合
首先证明一下为什么模型融合能提高准确率以及对低相关的结果进行融合可以获得更好结果。
用一个概率的例子来说明。假如现在有10条记录,每条记录能被正确分类的概率为70%,或者某个模型对这10条记录进行分类能获得70%的准确率。现在拟合三个相当的模型,采用多数表决的情况下,对每条记录,三个模型都判断正确的概率为0.7*0.7*0.7~=0.34,两个模型判断正确的概率为0.7*0.7*0.3*3~=0.44,那么通过三个准确率0.7的模型来融合的话,理论上最终每条记录能被正确分类的概率提升到0.78!
周志华教授在他的著作《机器学习》提到,结果的差异性越高,最终模型融合出来的结果也会越好。同样用一个简单的例子来证明:接着上面的话题,假设现在三个模型预测出来的结果是
model1:1111111100 = 80% 准确率
model2:1111111100 = 80% 准确率
model3:1011111100 = 70% 准确率
如果把这三个模型结果用多数表决组合起来,那么最终结果是:1111111100 = 80%,这个结果跟第一、二个模型是一致的,也就是,这样的模型融合对最终结果没有任何的提升。
假如我们现在把三个模型结果改为:
model1:1111111100 = 80% 准确率
model2:0111011101 = 70% 准确率
model3:1000101111 = 60% 准确率
显然这三个模型之间的差异更大,而且表面来看性能也不如前面提到的三个模型,但它们融合出来的结果是:1111111101 = 90% 准确率!
加权表决融合
多数表决的融合方式默认了所有模型的重要度是一样的,但通常情况下我们会更重视表现较好的模型而需要赋予更大的权值。在加权表决的情况下,表现较差的模型只能通过与其他模型获得一样的结果来增强自己的说服力。
对结果取平均
对结果取平均在很多机器学习问题上以及不同的评估准则上都获得很不错的结果。
取均值的做法常常可以减少过拟合现象。在机器学习的应用上,过拟合现象是很普遍的,根本问题是训练数据量不足以支撑复杂的模型,导致模型学习到数据集上的噪音,这样产生的问题是模型很难泛化,因为模型“考虑”得过分片面。
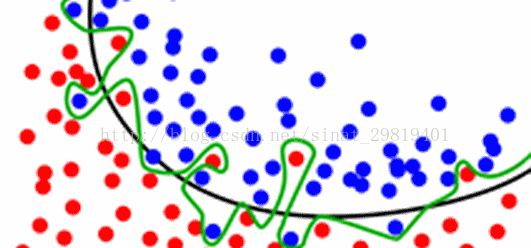
但如果对结果取平均,可以在一定程度上减轻过拟合现象。图中所示,单个模型因为过拟合产生了绿色的决策边界,但事实上黑色的决策边界因为有更好的泛化能力从而有更好的效果。如果通过拟合多个模型并对模型结果取平均,对这些噪音点的考虑就会因为结果拉平均的原因而减少,决策边界也会慢慢的往黑色线靠拢。
记住,机器学习的目的并不是让模型记住训练数据,而是对未知数据有更好的推广。
Stacking&Blending
Stacking
Stacking的基本思想是用一些基分类器进行分类,然后使用令一个分类器对结果进行整合。
用2-fold stacking作为例子:
1.将训练数据分成A和B两份
2.使用第一阶段模型用A训练,然后对B生成预测值
3.通过同样的模型用B训练,生成A的预测值
4.然后使用整个训练集来拟合这个模型,并生成测试集的预测值
5.像第(2)步一样训练第二阶段模型
Stacking的模型可以在特征空间上获取更加多的信息,因为第二阶段模型是以第一阶段模型的预测值会作为特征。
(update @ 2019.5.29:删除描述图,因图中文字表述有误)
Blending
Blending与Stacking大致相同,只是Blending的主要区别在于训练集不是通过K-Fold的CV策略来获得预测值从而生成第二阶段模型的特征,而是建立一个Holdout集,例如说10%的训练数据,第二阶段的stacker模型就基于第一阶段模型对这10%训练数据的预测值进行拟合。说白了,就是把Stacking流程中的K-Fold CV 改成 HoldOut CV。
Blending的优点在于:
1.比stacking简单(因为不用进行k次的交叉验证来获得stacker feature)
2.避开了一个信息泄露问题:generlizers和stacker使用了不一样的数据集
3.在团队建模过程中,不需要给队友分享自己的随机种子
而缺点在于:
1.使用了很少的数据(第二阶段的blender只使用training set10%的量)
2.blender可能会过拟合(其实大概率是第一点导致的)
3.stacking使用多次的CV会比较稳健
对于实践中的结果而言,stacking和blending的效果是差不多的,所以使用哪种方法都没什么所谓,完全取决于个人爱好。