操作系统CPU底层
CPU:中央处理器,运算器+控制器
PC:程序计数器,用来存放当前欲执行指令的地址,它与主存的MAR之间有一条直接通路,且具有自动加1的功能,即可自动形成下一条指令的地址。
IR:用来存放当前的指令,IR的内容来自于主存的MDR
CU:控制单元,用来解释存储器中的指令,并发出各种操作命令来执行指令
ALU:算逻部件,用来完成算术逻辑运算
ACC:累加器,运算器中的寄存器的一种
MQ:乘商寄存器
X:操作数寄存器
MAR:存储器地址寄存器,用来存放欲访问的存储单元的地址,其位数对应存储单元的个数
MDR:存储器数据寄存器,用来存放从存储体某单元取出的代码或者准备往某存储单元存入的代码,其位数与存储字长相等。
I/O:输入与输出设备,也称外部设备
MIPS:单位时间内执行指令的平均条数(百万条指令每秒)
CPI:执行一条指令所需的时钟周期(机器主频的倒数)
FLOPS:浮点运算次数每秒

上图为计算机的基本组成。
计算机有cpu 内存 硬盘等结构通过总线进行关联起来,总线传输着各种各样的数据。总线还连接着一些外部设备usb、显卡、网卡等等。
一个程序是如何让cpu给运行起来的呢?
先来讲一下程序、进程、线程、指令的关系:
在硬盘里的可执行文件叫程序
跑在内存里分配了一些内存资源让cpu去执行他叫做进程,一个程序是可以有多个进程的。
这个进程中的线程对于cpu来说就是一条一条的指令
一个进程里面不同的执行路径叫线程,一个程序可以有多个进程。
拿qq程序举例:
CPU
当我们点击qq.exe时操作系统就把qq.exe从硬盘里面放到内存里面映射成了一个进程,这个进程中的线程相对于cpu而言是一个一个的指令然后cpu去执行它。
CPU乱序执行的原因:
反向依赖的问题
乱序执行在等待时间内完成其他工作,能提高效率,但也会产生问题。例如下面这段程序。
LD r1,[a]; ←将内存的变量a 读入到寄存器r1(加载)
ADD r2,r1,r5; ←r1与r5相加,保存到r2
SUB r1,r5,r4; ←r5减去 r4,保存到 r1
执行这类程序时,开头的加载指令缓存未命中时,将变量a 读取到r1 就需要很长时间。而下一条ADD指令要使用r1 的值作为操作数,所以在加载指令完成之前,ADD指令无法执行。
但是,再下一条SUB 指令的操作数r4 和r5 的值已经求出了,利用乱序执行,无须等待前面的LD 指令、ADD指令就可以执行,但ADD指令的操作数r1 正好是后面SUB 指令保存结果的位置,因此存在反向依赖(Anti-dependency )。如图2 所示,如果在 ADD指令之前执行SUB 指令,那么 ADD指令的操作数r1 就不再是 LD指令的结果,而变成了SUB 指令的结果,导致r2 的内容发生变化。另外,LD 指令将结果保存到r1 的行为也要比SUB 指令将结果保存到r1 的行为晚,因此后面r1 的值也会因乱序执行而变化。
PC (Program Counter 程序计数器)
cpu是如何去执行这些指令的呢?
cpu有个组成部分叫 pc 这个pc里面记录这一个地址存放下一条执行的指令在哪里,cpu执行完一条就去内存取下一条。
Register 寄存器
执行指令过程中少不了一些数据放到cpu来执行 ,那这些数据就放在寄存器(registers)里面。
alu (Arithmetic Logic Unit)运算单元
数据放到寄存器之后使用运算单元alu来运算,运算完写回到寄存器,寄存器再写回到内存里面去。
比如:2+3这条在内存上的指令 首先pc指向2+3这条指令 然后2和3会放到寄存器里面 然后alu会进行计算然后把计算结果放回到寄存器里面 然后寄存器写回到内存里面
cache重点讲一下

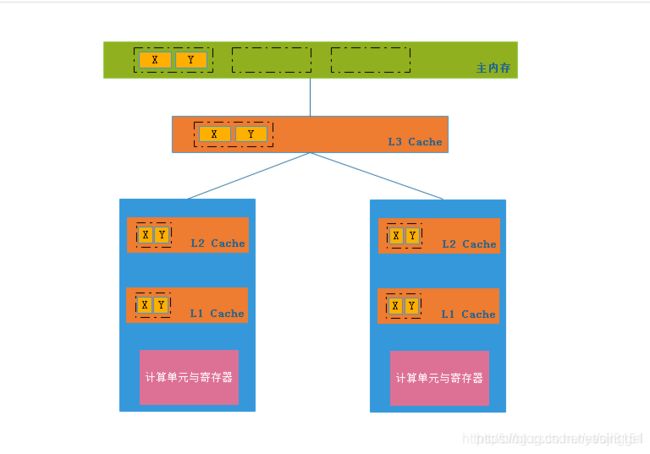
L1、L2是缓存 一般位于cpu内部,L3会位于主板或者cpu内。
由上图可以得知,如果寄存器想要得到存储在内存的数据是需要经历三层(不同cpu不同层,一般是三层)缓存,先进入L3再进入L2再进L1。
缓存行
寄存器要从内存中读数据的时候是,并不是一个字节一个字节的读取的而是通过总线一块一块的进行读取数据的,这里就有了缓存行的概念。缓存行越大 局部空间效率越高 但读取数据慢反之。目前多用的是64字节。
一块cpu里面有好多的核,每个核里面都有自己的内存单元自己的寄存器自己的pc。
小细节:经常写与经常读的数据单独存与缓存行中可以提高速度。
比如:long类型占4字节那么,前面申请56字节字段后面申请56字节字段,不论在哪里取此long类型数据都是单独在一个缓存行中。
MESI协议
如果一个线程或者cpu需要xy另外一个线程或者cpu也需要xy,那么第一个线程修改了xy后就必须通知另外一个线程使用最新的值,就产生了线程的可见性
怎么做呢?
intel使用的是MESI Cache一致性,硬件上使用缓存锁
具体可参考下面文章链接,讲的特别细:
https://juejin.im/post/5d67e75a5188256db0644778
总线风暴
Java代码中使用volatile,如果大量的使用,那么数据都进行缓存的一致性更近,并发量大时会出现总线风暴
对象创建过程:
1.分配内存 new #2<>
2.初始化,填充内存区域 astore_1
3.建立关联,也就是指针映射 invokespecial #3
DCL需不需要volatile?
合并写技术:使用缓存行对齐