写给java web一年左右工作经验的人
转自:https://my.oschina.net/aaron74/blog/282304
我把我这些年在java学习中学到的东西,按照项目开发中可能遇见的场景,进行了一次梳理。
这个故事是我最后决定加上来的,我非常喜欢这个故事,软件工程中有一个被戏称为Cargo Cult编程法的编程风格,而下面这个故事讲述了此编程法的来源:
早在40年代,据说,美军曾驻扎在一个偏远的岛屿。岛上的土著居民在此以前从未见过的现代文明,所以,他们对联军和他们带来的东西非常惊奇。他们发现联军修建了机场跑道和控制塔,带着耳机的士兵对天呼叫,然后满载着大量货物的大铁鸟便从天而降。当铁鸟降落后,货物便分发给所有岛上的人们,为人们带来繁荣。
终于,有一天,部队离开了,大铁鸟也不再回来了。为了再次得到货物,岛上的土著居民用竹子建造了自己的跑道,控制塔,让他们的头领登上平台,并让他戴上用椰子做的耳机。但无论他们如何努力尝试,大铁鸟再也没有回来。
几十年后,研究人员发现了该岛。岛上的土著居民仍旧保留着这一宗教仪式。他们把岛上居民的这一奇怪的宗教仪式命名为“Cargo Cult”
@考虑这样一个应用场景:我们的项目功能日渐强大,代码却日渐臃肿,我们如何将代码变得有条理些?
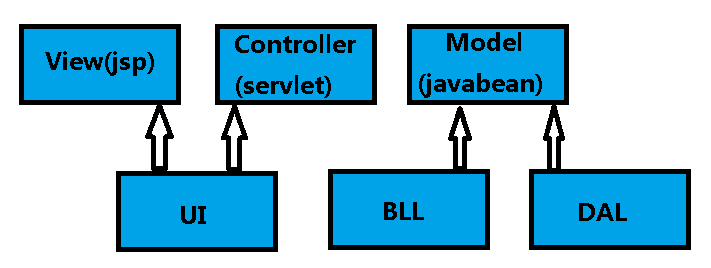
无论我们是学习还是工作,我们的前辈总是会告诉我们,我们需要把java项目进行架构上的分层,界面层(UI) 业务逻辑层(BLL) 数据访问层(DAL),就像Cargo Cult中的土著居民一样,虽然我们并不知道为什么高手们要那样做,但是我们相信这么做可以让程序工作起来,后面我会讲到为什么会有所谓的经典的三层架构,现在我们已经做完的事是,按照三层架构将项目搭建并运行起来了!
我们一般会想到MVC,很多书上都有写到,可惜很多时候我们理解的MVC是错误的。。。甚至我曾经天真的以为,MVC正好对应着DAL,UI,BLL。。。实际上,这两者并没有显式的关系,前者属于设计模式,而后者属于架构设计的范畴,如果一定要扯到一起的话,关系可能会是这样的:
 |
实际上,Controller是很薄的一层,它仅仅负责接收参数,封装参数,调用不同的service。所以我们可以考虑先从它入手,简化代码。
我们现有的controller做法是,不同的业务调用不同的servlet,通过参数的不同,调用不同的方法,比如,有下面一个form
<form action=”UserServlet?command=login”>
<input name=”name” />
<input name=”password” />
form>如果我们在这个表单中输入用户名密码,最终后台会将这个请求提交到UserServlet中,然后根据command=login,调用UserServlet中的login方法。在login方法中,会有这样的一段代码:
String name = request.getAttribute(“name”);
String password = request.getAttribute(“password”);
Boolean result = userService.hasUser(name, password);
if(result) {
....
} else {
....
} 我们可以发现,基本上这个servlet中,所有的方法几乎都有着从request中获取参数的这么一个过程,而且同一个servlet中,需要获取的参数大部分都是重叠的(比如UserServlet中,几乎所有的方法都需要获取name和password的值,才能进行近一步操作),既然每一个方法都有这么一个需求,为什么不考虑将这一过程抽象出来呢?
首先,我们可以设计一个叫AaronDispatcher的类,它负责截取了所有的对项目的访问的http请求。
比如,我们上面的请求叫UserServlet?command=login,同时传递三个参数name和password(以及上面的command) 。AaronDispatcher巨牛叉,它直接把这个请求截取了,并进行分析,首先它的名字叫UserServlet,调用的方法叫login。为了不引发歧义,我们更改前台的请求地址,改为发送到UserAction?command=login。
然后我们可以重新设计UserServlet,创建全新的UserAction。(现已加入豪华午餐)
public UserAction {
String name;
String password;
String newpassword; //updatePassword这个方法需要
String oldpassword;
...... //所有的UserAction从前端获取的参数
public login() {
...
}
public logout() {
...
}
public updatePassword() {
...
}
...... //所有UserAction需要提供的方法
} //UserAction结束 (眼疾手快的人也许可以注意到一点:这个类不再需要接受HttpServletRequest及HttpServletResponse作为参数了)
每当我们有一个发送到UserAction的请求,AaronDispatcher就帮我们new一个新的UserAction实例,同时将请求中的参数赋给UserServlet中的属性。具体的底层做法,类似于下面这样:(实际上会复杂很多,不会直接new对象,而是使用反射来创建对象并赋值属性)
UserAction userAction = new UserAction();
userAction.setName(request.getAttrbute(“name”));
userAction.setPassword(request.getAttrbute(“password”));
userAction.setNewpassword(request.getAttrbute(“newpassword”));
userAction.setOldpassword(request.getAttrbute(“oldpassword”));
...... 如果我们需要登陆功能,直接调用userAction.login()就可以了(至于name和password,直接可以在方法内部获取当前对象属性)。 所有的方法中,从request中获取参数并进行封装的这么一个过程,全部都被巨牛叉的AaronDispatcher做了,是不是减少了很多重复的代码量?!
可能会有疑虑,所有的请求,无论什么方法,都进行一次属性全赋值,如果前台没有传入这个属性,不就为空了嘛?但是要知道,如果我们调用login这个功能,newpassword和oldpassword固然会因为前台没有相应的属性值传入而设为null,但是,但是,在login方法中,我们根本就不会用到这两个参数啊!所以即使为空也不会有错的!
甚至我们可以做的再牛叉一点,AaronDispatcher会去读取一段配置文件,配置文件中指定了什么样的请求调用什么养的类以及相应的方法,这样我们就可以彻底解耦最前方的Controller了!
但是AaronDispatcher是怎么做到无论什么类,当中有什么属性,我们都不需要事先知道,我们都可以接收前端参数,给他们的属性赋值呢?(答案是通过反射)
现在,我们已经成功的重新发明轮子了!
因为以上这个伟大的想法已经有被别人抢在前面实现了,就是著名的Struts2,毋庸置疑,Struts2的核心功能就是这么简单。
在Struts2中,每一个处理类被称之为Action,而Struts2也正是通过xml配置文件,实现了无需要修改代码,通过修改配置文件,就可以修改Controller。
Struts2发展到今天已然是一个功能齐全的庞然大物了。
正如一开始所说,MVC框架只不过帮助我们封装了请求参数,分发了请求而已。Controller是非常薄的一层,而我们的业务逻辑都是由BLL层提供的Service对象实现。
首先讲述一下为什么会有所谓BLL(Business Logic Layer)和DAL(Dataaccess Layer)了。在一个项目中,无论是查询用户的用户名,还是查询库存数量,这些数据终归是要保存到数据库的,而这些对数据库的操作将会无比的频繁,如果我们不将这些对数据库表的操作独立出来,如果在多个方法中存在着对一个用户记录的查询,我们不得不把这段代码copy、paste无数次,既然这样,我们为什么不像上面那样,将这种可能会多次遇到操作抽象出来呢?于是就有了所谓的DAL了,这样,无论在什么地方,需要用到数据库查询相关的工作的时候,仅仅需要这么做
User user = userDaoImp.getUserById(userId);
...... 这么做有一个好处:减少了因为持久化方案的更换而导致的代码修改带来的工作。
持久化是一个非常高端大气的专业术语,说的更专业一点,就是将内存中的数据保存到硬盘中。在我们的项目中,用户进行了注册,我们需要将用户注册的用户名密码保存起来,以便下次用户登陆的时候我们能够知道,这个用户名的用户是合法注册过的。
通常持久化的方案就是将数据保存到数据库中,但是我相信如果我不愿意使用数据库,而直接将用户名密码明文保存到文本文件中,也没有人会从技术上反对吧(实际上这种事情在中国互联网的发展历史中还真发生过。。。),如果我真的选择这么做,我所需要做的工作就是仅仅修改DAL中的实现,将对数据库的操作改为对本地文件的操作,而无须修改调用持久化方法的方法。
业务层负责业务的处理(接收上层传过来的信息进行处理),当处理完之后,将处理的结果利用DAL的对象进行“保存到硬盘”。而DAL具体是怎么实现的,完全不会影响到已实现的业务。
很明显的,为了做到上面这一点,DAL中的方法要尽量的“单纯”,不包含任何的业务上的逻辑,仅仅是将内存中的数据(一般就是某个对象)保存到硬盘的“实现”,以及从硬盘读取的数据提取到内存的“实现”。
已经很明显了,三层架构不是从来都有的,只不过是在无数次痛苦的经历过后先烈们总结出来的一套证明可以在某一方面减少因变动而带来的额外工作量。说它经典,也只不过是因为它实现了展示、业务、持久化这三个必不可少却又相对对立的需求的切割(不过确实有的项目中,展示不是必选的)。
所以基本上所有的复杂架构也只不过是在此基础上的进一步分割,曾经做过一个巨复杂SaaS项目,为了减少某些不定因素的变动而带来的代码上的改动,架构师将BLL分成了两层,在原有的BLL之上又增加了一层core business layer。这样MVC框架只需要调用core business的业务而无须自己在重复组装比较底层的业务逻辑了。
如果有更复杂些的项目的话,就需要通过分割子项目及更复杂的层级关系来解决了。
这个时候我们或许应该讲述BLL了,不过在此之前,我们可以再多想一步,能不能修改DAL中的东西,让我们使用起来更简单?
一般来说,数据库中的表对应着java中的类,表中的一行记录对应着一个entity对象,表中的字段对应着对象中的属性,我以前一直觉得很神奇,这就是传说中的ORM。这当中还有很多更复杂的东西,比如多表级联的结果映射为对象,在这里我们先忽略这些复杂的情况。
有了上面的知识,我们可以发现, 如果我们选择关系型数据库作为持久化方案,我们的DAL其实也很“单纯”,他们所做的也不过是将对象属性通过sql存储到数据库、将通过sql获取的数据封装为对象。
同样的我们可以写一个巨牛叉框架(好吧,这次不是写一个巨牛叉的类了),它会自动根据我们entity的名字,去数据库寻找相应的表,当我们调用insert,delete,update,select等方法的时候,它会自动帮助我们根据要求及参数拼接sql,然后去数据库查询/修改记录,如果是查询,则把查询出来的记录集封装成对象,保存在list中。这样,我们就可以在DAL中简单的定义一些entity就可以了。
比如,我们这次在DAL中,仅仅只定义了一个类:
public User {
long id;
String name;
String password;
} 是的,剩下的事全部交给这个巨牛叉的框架来做了,当我们需要在UserService中查询一个用户记录的时候,我们只需要这么做:
//我们已经假设了框架巨牛叉,所有的DAL对象都是可以根据entity自动生成
AaronDao userDao = new AaronDao(User.class);
List list = userDao.list(......) //括号里面是一些列条件,比如一些分页条件啊,属性限制啊之类的。 哇~,生活瞬间变得很美好,这个巨牛叉的框架太棒了,只要定义好entity就可以完成以前需要成千上百行才能完成的功能,我连数据库的刷库脚本都不用写了~这么巨牛叉的框架一定会帮我们做好这些的。我恨不得马上就使用这个框架来开发我下的一个项目。
只可惜java中还真没有这种框架。。。
实际上java的JDBC远比想象中的复杂(主要是因为作为强异常处理的java语言,为了完成一次对数据库的操作,需要编写的异常处理代码实在太多了),还有事务的处理,数据库连接的开启和释放(甚至连接池的配置),等等等等。。。如果使用Spring JDBC或者Hibernate ORM框架,可以帮助我们不需要花太多精力放在非核心的处理上,专注于数据的读/写。
即使这样,需要写的代码还是太多了。因为每一个entity我们都必须手动编写相应的Dao类(注:操作entity的类),我又开始怀念那个巨牛叉的框架了。如果大家有兴趣,倒是可以尝试一下实现我上面所形容的据牛叉的DAL框架。
实际上,真的有人在Ruby中实现了类似于上述的数据库操作框架,在Ruby On Rails中,我们仅仅只需要定义一些普通的entity,而剩下的操作都是ror自动生成,当年DHH(ror的作者)在网上发出15分钟从零开始完成博客系统的视频,整个Web世界都被惊叹到了。
在正式讲到BLL之前,咱们先怀念一下最原始的servlet,是的,就是它刚刚出生的时候的事。
最早的时候,sun在提出servlet规范的时候,很多人是直接在servlet中完成接收参数,处理业务,从数据库或者本地文件中读取数据,最后打印出html返回。这个过程,大概会长成这个样子:
response.getWriter().println(“”);
response.getWriter().println(“hello ” + user.name);
response.getWriter().println(“”); 不用怀疑,JSP出现之前很多大神早期真的都这么做过。
显然的,后来对数据库的操作被剥离出来作为DAL了,那为什么还要剥离BLL呢?
如果我们不剥离service对象(BLL),如果我们需要增加用户,我们需要在UserServlet中这样写:
public void doPost(HttpServletRequest request, HttpServletResponse response){
Strring cmd = request.getAttribute(“command”);
if (“addUser”.equals(request.getAttribute(cmd))) {
String name = request.getAttribute(“name”);
String password = request.getAttribute(“password”);
User user = new User(name,password);
if (userDaoImp.getUserByName(“name”) != null){
userDaoImp.addUser(user);
......//返回添加成功页面
} else {
......//返回添加失败页面
}
} else if (其他command) {
......
}
} 这当中只有一个简单的逻辑:如果用户名已经存在,则返回到错误页面,告知用户添加新用户失败。如果用户名不存在,则返回到正确页面,告知用户添加新用户成功。
如果我们想测试我们所写的代码是否正确,会遇到一个前所未有的困难,需要模拟HttpServletRequest和HttpServletResponse对象以及一个UserServlet对象。我们很难脱离浏览器环境测试这个类。(实际上可以通过mock来模拟这个过程,这个后面会说到)
简单的办法就是写好前端页面,然后通过在页面上去添加一个用户,看看是不是真以上逻辑正确。
天呐。。。这才是一个简单的业务逻辑,我们就不得不等到有了前端页面之后才能去测试它,如果我们的逻辑更复杂点,等到前端都做完了才能发现有后台有bug,而且即使修改完了还需要回头通过浏览器再测试一遍,如果是通过页面不断地手动输入用户信息这种,估计一天也就测试几个case了。。。大部分时间都浪费在键盘上了。
要是能把测试的case记录下来,下次由电脑自动的重新模拟这个过程该多好(正所谓重复劳动力全部交给电脑吧!),不过自动化测试在后面,我们先跳过这个疯狂的想法。
还是修改源代码吧。。。
public void doPost(HttpServletRequest request, HttpServletResponse response){
String cmd = request.getAttribute(“command”);
if (“addUser”.equals(cmd)) {
String name = request.getAttribute(“name”);
String password = request.getAttribute(“password”);
User user = new User(name,password);
userService.addUSer();
}
} //结束doPost 正如一开始所说,通过将servlet作为很薄的一层controller,真正的业务逻辑抛给service做,所有对业务的测试全部都可以简单的变为对service的测试。
比如我们可以简单的这样测试:
public static void main(String[] args) {
UserService userService = new UserService();
User user = new User(name,password);
System.out.println(userService.addUser(user));
} servlet中唯一要做的,就是根据service的返回结果,返回不同的UI展示。
这样保证了一种“契约”:servlet负责调用service并提供相应参数,根据service的返回结果,返回不同的UI展示。只要service没有错误,servlet肯定能正确的执行MVC中对View的跳转。
而对service中业务逻辑的测试,在前期就可以通过简单的单元测试做完,保证最后提供出去的service都是正确的。相比较于将业务逻辑写入servlet,等到后期通过页面的操作才能发现bug,开发效率可以说是骤增。
实际情况当然会比我所说的例子复杂的多。。。
首先,现在很少有项目会直接采用servlet的形式来做,那样子的话我们不得不在很多地方重新创造轮子(还记不记得我设计的很牛叉的AaronDispatcher。。。),一般会采用MVC框架来封装servlet。
同时,我们会遇到很多很多诸如安全性,权限控制,异常处理等等之类的,需要解决的问题。(最后我们会发现,我们的业务逻辑的代码量和这些非业务逻辑代码量相比,要少的多的多)
对有些人来说,如果仅仅是为了测试而多做一层service的确看起来没有那个必要,三层架构不一定总是正确,有很多缺点,典型的贫血模型,不够面向对象(关于这一点,网上的资料好多,可以尝试一下);开发过程漫长;做出来的效果鱼龙混杂;(同样适用三层架构,大牛们和我设计出来的效果简直就是美食和狗屎的区别)
现实生活中,没有这么复杂的php也活得好好的。
但是,但是,但是。。。如果我们只是想做一个网站,它只需要记录我们的博客,展示我们曾经拍过的照片,提供一个供大家谈谈人生谈谈理想论坛,那么我建议使用php,的确做网站最好的是php,用java纯属装逼。java之所以是java(或者换句话,.net之所以是.net),他们与php的差别在于,他们有完整的命名空间机制(java中的package,C#中的namespace),完善的开发标准体系,成熟的第三方框架,语法简单、规则性强。事实上,java/.net绝对不适合做快速成型的展示型网站。
吐槽结束,回到上面的问题,既然三层架构绝对不是权威,仅仅为了测试还不值得我们抽象出一层BLL,那为什么我们要像Cargo Cult土著居民那样,跟随别人的脚步呢?
因为我们还不够强。。。
因为我们还不够强,不能想到更好的分层办法,所以我们不得不沿用传统的三层架构或者在此基础上的多层架构,如果我们足够强大,完全可以利用领域模型的思维来构建系统。
因为我们不够强大,很多功能我们需要利用BLL才能实现。
正如前面所说,java工程师的方向绝对不是做一个简单的网站,如果项目领导突然有一天神经大条,说我们需要做一个iphone客户端,因为领导用的是iphone,如果我们没有把BLL抽象出来,我们就不得不重新写一个和web处理相同业务逻辑的层级,用来和iphone客户端通信。如果业务复杂,天呐。。。
正是由于我们已经将不依赖于任何显示逻辑的BLL抽象出来,我们才能淡然的添加一层薄薄的iphone客户端通信层,当需要发生业务逻辑的时候,仅仅只需要调用BLL已实现的方法。
通常三层架构中的UI最终会返回html给浏览器解析,而iphone通信层一般会返回json数据给iphone客户端解析。
好吧,的确不是所有领导都有iphone的,但是,即使我们确定我们仅仅需要支持的就是浏览器,很不幸,很多时候我们也需要利用BLL。
通常BLL中的每一个方法都是一个事务。事务是一个很复杂的东西,在分布式系统中更是如此,但即使是一个简单的项目,我们也不得不为事务而伤神。
在我们的潜意识中,事务应该是数据库访问层做的事,但是很不幸,我们需要在业务逻辑处理中进行事务。
最烂大街的例子,BLL中有一个AccountServer类,提供一个transfer(Double money, Account from, Account to)方法。在这个方法中,首先会进行一次update(from),再进行一次update(to)的数据库操作,但是如果update(from),汇款操作成功了,但是因为某些未知原因,update(to),收款操作失败了,估计所有人都接受不了这件事。
所以我们要保证transfer(Double money, Account from, Account to)作为一个方法,要么里面的数据库操作都成功,要么都失败。
抽象出业务逻辑层的好处在于我们可以以一种更好的颗粒度来做事务。
说点题外话。。。
不得不说,如果不利用Spring AOP来配置事务,纯手工编写的话,给BLL中的方法做事务,的确是一个很有技术含量的活。
这当中的确用到了很多设计模式的奇技淫巧、ThrealLocal等较为高深的技术(好吧,的确在一年之前,我真的不知道ThreadLoacl是什么。。。),因为我们做事务的一个前提是,事务中所有的数据库操作,使用的是同一个connection。
关于更具体的,如何简化BLL中的事务配置,以及面向接口的编程习惯,spring的使用,将会留到下一个应用场景。
现在我们来做一次总结:
MVC之类的设计模式、三层架构的划分,归根结底的目的在于解耦,减少项目中牵一发而动全身的现象,同时减少重复代码的编写,增加代码的可读性、复用性。
所谓框架,就是帮助我们减少重复的、不必要的、非业务核心的代码的编写的工具而已。(不然我们用它图什么呢?)
事实上,如果我们真的看完所谓23种设计模式,实际上只是在强调三个原则:封装变化点、对接口进行编程、多使用组合而不是继承。(这里主要注意第一点)
好吧,进入下面的应用场景。
@考虑这样一个应用场景:我们已经深刻的掌握了三层架构的要领(事实上并没有。。。),并且使用了业内最牛叉的Aaron MVC框架来处理请求,一切都变得很美好。突然有一天,领导来了。。。
领导有一天突然发现,我们的UserService中的listUsers写的不够好,没有另外一个小组编写的UserService中实现的listUsers方法好,因为另外一个小组在listUsers中加了一个小判断,在列举出来的用户中,领导永远排在第一个。
于是乎,领导二话不说,让我们直接把Action中有引用到UserService的全部换成他们的UserService。
因为我们的UserService是这样子导入的:
import com.unis.team1.UserService; 而他们的UserServcice则需要这样子导入:
import com.unis.team2.UserService; 于是,我们不得不全文搜索所有的地方, 将import com.unis.team1.UserService 改为import com.unis.team2.UserService
如果很不凑巧,大家的命名方法不一样,另外一个小组的名字叫做com.unis.team2.UserServ,我就不得不全文搜索将import com.unis.team1.UserService 改为import com.unis.team2.UserServ, 同时,全文搜索将UserService改为UserServ。
这一切的一切的罪恶的根源,源于如下的代码:
import com.unis.team1.UserService;
public UserAction{
UserService userService = new UserService();
....... //参考struts2中需要的东西
}我们添加一个接口:
public interface IUSerService {
List listUsers();
} 于是,导致罪恶的代码被修改为这样:
import com.unis.service.UserService;
public UserAction{
IUserService userService;
....... //参考struts2中需要的东西
}Animal cat = new Cat(); //Cat实现了Animal接口回到刚才的罪恶的代码,我们在Action中定义了service的接口,可是那又怎么样呢?最终不还是需要new一个具体的实现吗?如果我们new了UserService,后面需要替换的时候,还是需要换成new UserServ啊!
嗯,所以我们就要想办法不需要自己在代码中new!跟往常一样,我们设计一个超级牛叉的Aaron Container框架,它能完美的和Aaron MVC结合。
我们定义了如上的UserAction,但是实际上我们真正使用的UserAction并不是我们自己new出来的,而是每次有一个请求到来的时候,由Aaron MVC创建的,创建的过程可以这么去理解(实际上的情况要复杂的多,可以看出,Aaron MVC就是一个山寨版的struts2,action的创建远远比这个复杂!):
UserAction userAction = new UserAction();
IUserService userService = new UserService();
userAction.setUserService(userService);如果仅仅是为了动态的替换实现类,就将所有本来一个类就能完成的事拆分成接口和实现类,好像也说不过去哦。。。不过,领导怎么会这么轻易地善罢甘休呢?
领导决定放大招了,他觉得既然我们现在已经分离出了BLL,那么他希望BLL中的每一个方法执行前,都进行一次log记录,记录的格式大概如下:
“谁谁谁”于“什么什么时间”进行了“什么什么操作”
我可以骂人吗?!在提干的假设中,我们的项目已经做的很庞大了,也就是说,我们的BLL中有上百个类,上千个方法!也就是说,为了领导的一句话,我们不得不Ctrl C V上千次,而且还有可能有遗漏。。。
是时候让史上最牛叉的Aaron Container框架出场了!
上面已经说了,Aaron MVC会帮助我们自动生成Action,而当中如果有需要用的BLL中的接口,会被自动“注入”我们需要的实现类,我们修改一下这个过程:
UserAction userAction = new UserAction();
IUserService userService = AaronContainer.get(IUserService.class)
userAction.setUserService(userService);先介绍一下可爱的代理模式吧。。。
public interface Test {
public void test();
}
public AaronTest implements Test {
public void test() {
System.out.println(“hello world !”);
}
}
public AaronTestProxy implements Test {
public Test testImpl;
public AaronTestProxy(Test test) {
this.testImpl = test;
}
public void doBefore() {
System.out.println(“do before !”);
}
public void doAfter() {
System.out.println(“do after!”);
}
public void test() {
this.doBefore();
this.testImpl.test();
this.doAfter();
}
}Test test = new AaronTest();
test.test();hello world !
但是如果我们使用代理类,我们可以这么做:
Test test = new AaronTestProxy(new AaronTest());
test.test();do before !
hello world !
do after !
相信聪明的孩子已经看出来了,通过代理类,我们可以在原本需要实现的方法实现之前/之后做点别的事。
而想要完成这一点,关键就在于——接口!
我们声明需要的只是某一个接口,我们提供的是代理之后的实现。
我们将核心的逻辑放入接口实现类,而公共的非业务逻辑放入代理实现类,通过代理实现类包装业务逻辑,我们就可以全心全意的将精力放入业务逻辑的实现,而将权限控制、日志记录、异常处理等功能,由代理类实现。(比如上面的doBefore方法,完全可以用来记录日志)
这也是设计模式第二个原则:面向接口编程。
现在假设我们的Aaron Container框架已经帮助我们代理了所有的service实现类(前提是,service都是接口!!!)于是乎,所有在需要service实现类的地方,我们都只是声明一个接口,Aaron Container会自动将代理类注入进去!
而且,我们的Aaron Container框架已经聪敏的成精了,AaronContainer.get(IUserService.class)这个过程,返回的是包装了我们所编写的UserService的代理类,当我们执行当中的方法的时候,代理类首先先记录一下日志:
“谁谁谁”于“什么什么时间”调用了“什么什么方法”
然后再调用UserService中的我们所编写的带有业务逻辑的方法。
好了,现在我来总结一下这一套“复杂”的过程:
首先是我们将service分为接口和实现。
然后在需要service方法的地方声明了相应的接口。
OK,我们工作结束了。
然后,Aaron框架套件会帮助我们利用一些列高阶的java技巧,完成剩下的工作。
将需要用到service的地方“注入”具体的“实现”,而这当中,所有的“具体实现”,不再是简单的我们自己所编写的service实现,而是经过包装(也就是代理)后的代理实现类。
代理实现类很牛叉的帮助我们在运行具体业务逻辑方法之前/之后做点别的事,比如记录一下日志,检测一下用户权限是否匹配,事务的声明什么的。
理解上述的过程还是十分简单的,不过我仍然要说一下,具有人工智能的Aaron框架套件仍处于开发中,所以我们还不能因为我们的领导想添加日志,框架就会帮助我们实现代理类的日志记录,所以我们需要自行编写代理类的日志记录行为(这当中的步骤远比我形容的困难,我们甚至需要获取到当前用户的信息)。
现在我们来看一看Aaron Container到底做了些什么吧:帮助我们生成某个接口实现类的代理类,在我们所有的编写的需要这些实现类的地方,我们都不再需要人为的“new”了,我们仅仅需要声明我们需要这个接口,然后它会帮助我们将生成代理类“注入”到声明了有接口的地方。因为所有的代理类都是从Aaron Container“拿”出来的,所以运行的时候调用这些代理类的某个方法的时候,很容易就可以做到添加点别的功能,而无须修改我们自己编写的那个实现类。
这就是所谓的依赖注入(或者高端大气一点叫做控制反转),我们无需自己new,仅仅只需要声明,真正需要用到这个对象的时候会被“注入”进来。
好吧,这就是Spring的核心,一个大大的container,负责创建“实现了某个接口的业务逻辑对象”的代理对象(这么说很狭隘,实际上要是愿意,我们可以将大部分对象都交由Spring管理)。
Spring帮助我们管理需要被管理的对象的生命周期,简单来说,就是我们可以通过配置文件,控制这些需要被管理的对象什么时候生成,生成的时候加点什么操作,什么时候销毁,销毁的时候加点什么操作(比如在销毁的时候记录一下日志“我死了。。。”)什么的,一切都变得可控了。
而且我们可以随时替换具体的实现类,因为我们在源代码中并没有硬编码声明我们需要new“哪一个”具体实现类!!
是的,这就是Spring的核心,听起来好简单,没什么大不了,但是的确就是这样。
而Spring AOP(这个会在很多地方看到的专业术语),也只不过是因为Spring帮助我们通过代理类管理了类的生成和注入从而才有的“附加功能”。AOP的含义简单来说,就像上面我们需要在每一个BLL中方法被调用时记录一下日志那样,因为所有的BLL中的具体实现类对象都由Spring来管理,当我们需要“横切”,对所有对象统一的加一个“调用方法时记录这个操作”这个操作时,只需要在一个地方声明一下我们需要在方法调用之前进行日志操作,就可以完成对所有BLL中的方法添加记录日志这个功能,这就是AOP。
再次记住这句话,依赖于接口,而不是依赖于具体的某一个类(通俗一点的说就是不要在代码里面直接new某个实现类对象),可以帮助我们减少很多代码量,同时提高项目的扩展性,扩展性在于,我们不需要修改已有代码(重中之重!!!),就可以替换行为,而在java中,如果不面向接口编程,这是无论如何都做不到的。
再次给我挚爱的Ruby做一次广告,为什么Ruby的开发速度比java快?为什么Ruby/Python不需要接口?
脚本语言在运行的时候可以动态的修改类里面的行为,而java需要先编译,一旦编译好的类,我们就无法再次去修改他们了,所以脚本语言不需要像java那样,事先定义好很多接口才能玩转设计模式(所以很多设计模式对于脚本语言来说,都是天生自然而然就能做到的,而不是很难的“编程技巧”)。
从这个角度来说,java/C#是拥有很强“契约精神”的语言,这种“限制”保证了我们可以在代码量成几何式增长之后仍旧能够保持良好的结构,而且即使是新手,只要按照相应的“契约”,就能够完成上面所交代的任务而不会影响别人的代码。某种意义上来说,java项目更注重“架构”的设计,而Ruby项目更注重个人的编程能力。
正如黑格尔所说,太阳下面没有新事物,随着我们的项目从无到有,从小到大,代码量成几何式增长,于是我们为了减少重复代码量,将项目中可变的部分抽象出来。为了减少因为代码改动而带来的额外工作量,我们总结了一套设计模式。为了用更少的代码实现总结出来的设计模式,我们将当中公共的部分作为模板(也就是框架),需要用到的时候直接利用这套模板就可以帮助我们专注于业务逻辑的实现而不是其他的条条框框。
嗯,读到这里的时候,我们已经可以人模人样的做一些项目了,甚至在这个过程中,查看了一些主流框架的使用方法并且用上了他们,我们简直就可以宣称我们是一个合格的软件工程师了!
其实。。。我们才刚上路。
进入下面一个应用场景吧!
@考虑这样一个应用场景:我们已经利用SSH(是的,就是那个很流行的Spring,Struts2,Hbiernate),人模人样的将项目重新搭建起来了,代码的结构瞬间变得无比清晰(虽然我相信百分之八十以上的人并不是真正理解SSH),这个时候,项目变得越来越庞大。。。
SSH在华人社区流行已久(主要是大陆和台湾地区),其实我个人并不喜欢这三个框架的组合。在欧美地区,只有Spring是依然流行的。(实际上Spring的地位也在遭受很多轻量级IOC框架的挑战)
在这次的应用场景中,我准备一次性讲述多一点的东西,所以这次的假设会糟糕一点。
因为开发人员众多,经常会发生每个人的开发环境不一致,比如明明我们用的是Spring 3.0的jar包,却偏偏有人用的是Spring 2.5的jar包。而且项目越做越大,我们不得已分成了几个子项目,交由不同的团队去做,可是经常发生其他团队已经完成了bug fix并打出新包了,我们仍然在沿用以前的有bug的旧包!
以前写过一篇关于Maven的简单介绍,这次就直接copy过来了。
关于构建的概念:
很久很久之前,在我刚刚学习Java的时候,那个时候还是非常的菜的,有一次学习struts,需要做一个项目,当时的流程是这样的(我相信很多人都时曾相识?):
1、熟练地打开eclipse,新建dynamic web项目
2、从struts官网下载最新的jar包(好多好多个jar文件啊)
3、不管三七二十一,刷的一下,把所有jar包放到WEB-INF/lib
4、开始写代码
5、右击项目,导出war包,拷贝到tomcat的webapp下
这个过程看似没有问题,直到后来实习的时候被项目经理狠批。这个过程中我根本就不知道我所需要的什么jar包,不管有用的没用的,全部放到lib下。这种做法不但会导致lib臃肿难以维护,而且根本无法保证所有开发人员的第三方依赖包版本一致。最关键的是,因为每一次的打包动作,都需要开发人员从eclipse中右击导出war包。想象一种情况:我们的项目中有一个依赖的jar包是另外一个开发小组所写,如果我们需要进行最新的项目测试,我们首先得先让另外一个开发小组将他们最新的代码导出为jar包, 然后将他们最新的jar包导 入我们项目的classpath(这个过程,是不是离开了eclipse大家就不会了?),然后继续,右击导出war包。如果我们依赖的多个jar包都是我们不同的团队所写,这个过程所耗费的时间将成集几何的增长。
题外话:eclipse导出war包的原理:
我们每次通过eclipse创建dynamic web项目的时候, eclipse会自动帮我们创建一个src文件夹,WebContent文件夹,.project配置文件(其实根据插件的选用,隐藏配置文件会有很多个)。同时引入了一些列classpath:src、 WebContent/WEB-INF/lib、jvm核心依赖包、tomcat中的一些servlet依赖包、其他。。。当我们导出war包的时候,eclipse 首先根据.project中的配置,导入classpath中的依赖包(这也是为什么我们在初学阶段,总是将需要用到的这些jar包放到WebContent/WEB-INF/lib中去),将src下的所有.java文件编译(这也是为什么我们的源代码总是要写在src下才能被编译),将生成的.class文件拷贝到 WebContent/WEB-INF/classes中。最后将WebContent打成war包输出(war包的名字为:项目名.war)。
回来继续:
因为这个过程绝对不可能由人来做(耗费时间太长而且没有意义),于是后来我们就开始学习Ant来进行刚才的操作。Ant的原理就是:指定好我们需要编译的源代码路径(不管一个公司有多少项目,这些项目最新的源代码路径总是有的)、依赖的jar包位置(Ant会帮我们把这些依赖包引入到classpath中)、打包的方式(jar还是war等等之类)、以及打包的顺序(就像最开始所说的那样,可能某一个模块的编译需要依赖另外一个模块,被依赖的源代码会首先被编译)。然后Ant就会帮我们编译这些源代码了,那些被依赖的jar会首先被编译打包(会根据依赖树进行打包顺序),然后放到某个文件夹下,然后这些被依赖的jar包会被引入classpath,然后继续编译,最后,所有的源代码编译结束,将依赖的jar包们拷贝到WEB-INF/lib中,web层的.class们拷贝到WEB-INF/classes中。 删除被打出来放到临时目录 的jar包们。将最后的war包拷贝到指定目录,整个过程就结束了。
需要说明一下的是:平时我们在eclipse中,eclipse已经帮我们指定了servlet容器位置,所以我们不觉得有什么不对劲,但是一旦自己手动打包的时候,我们必须手动指定servlet相关jar包的路径并引入到classpath中!
在刚刚的过程中,我们发现,我们可以做到只需要一个命令:Ant自动帮我们根据顺序依次打包最新的代码,然后将最新的代码进行打包,并且可以将生成的war包拷贝到指定目录下,于是我们可以引入一些系统脚本,测试只需要执行一下某个脚本文件,就可以自动的将新鲜出炉的war包放入tomcat/jboss/jetty中,并启动容器。之后什么都不需要做,直接打开浏览器就可以测试啦!
这个过程之中的问题:
如果你写过Ant的build.xml,也就是Ant的配置文件,你一定会发现这是一个痛苦的过程。首先,我们得指定第三方依赖包的路径,虽然这样能保证所有人引用第三方依赖包的版本一致,但是如果依赖包过多的话,需要编写老长的一段说明。其次,我们需要指定项目源代码的路径,这样是很长的一段说明(同一个项目不一定在同一个地方啊。。。像我之前所说的那样,可能我们项目中的某个模块,是由另一个团队在别的路径下编写,最后我们只是引用他们所生成的jar包而已)。最后,也是最坑爹的事情,我们必须手动指定打包顺序:如果a模块依赖b模块和c模块(这三个模块都是我们自己开发),b模块依赖c模块,我们必须先打包c模块,然后再打包b模块(同时引用c模块打好的包),最后打包a模块(同时引用b模块和c模块打好的包)。这才是最简单的一种情况呀,随着项目的模块化,这种关系可能会变得更加复杂,打包顺序也需要考虑好一会,即使我们很聪明,这种树形顺序难不倒我们,编写xml也是一个很烦人的任务啊。
Maven的出现:
我们可以简单的认为,Maven也是为了完成上面的任务所诞生的,但是相比较于Ant,我们所需要编写的xml将会骤减不少。而且,在大多数的时候,打包顺序这种费脑经的事,Maven可以依据依赖关系自动帮我们完成。
同时,Maven不但可以完成了上述Ant所写的所有功能,还有额外的一些功能,帮助我们缩短开发时间:
我们不必再自己去各个第三方依赖包官网手动下载依赖包了,只要申明了我需要某个jar包的某个版本,Maven会自动帮我们下载下来并在编译、打包的时候引用。
Maven贯穿项目整个生命周期,从早期的依赖包下载到后期的打包部署,在编译过程中,找到测试代码,运行jUnit等工具进行测试并生成测试报告。
Maven比Ant更进一步,更像一个部署工具,依靠插件,可以在运行Maven命令之后,甚至连数据库初始化这个工作都可以帮我们做了,在编译之后,将项目拷贝至容器并启动容器,真正做到“开箱即测”。
Maven的使用:
自行百度吧。。。
Maven的出现实际上是为了适应我们项目越来越复杂,开发人员越来越多,依赖包越来越庞大,同时拆分为更多子项目,打包过程繁琐,自动化测试程度越来越高的发展需要。
我原本觉得下一章应该进入自动化测试的介绍了,但自动化测试绝对是一个无穷无尽的深坑。。。所以我就简单描述一下,在自动化测试中,所有的操作必须由代码来模拟,测试过程中不会有人的干预,所有用例均由代码控制。作为开发人员,我们提供出去的每一个方法都有相应的测试用例,最终会在编译过程中自动由Maven进行测试并生成报告。
进入最后一个应用场景
@考虑这样一个应用场景:有一天我们领导发现,单页面应用变得火爆起来,于是让我们将项目转为单页面应用
首先还是得解释一下什么是单页面应用。
传统的网站在页面上会有各种的超链接以及表单按钮,通过点击这些超链接或者表单按钮,我们会访问不同的网站,如果我们有当当购书的经验,就会知道,当我们点击了购买按钮时,我们会跳转到支付页面,当完成支付时,我们会跳转到购买成功的页面,我们不断地在跳转,也没有觉得有什么不对。
的确,事实上这没有什么不对。
还记得google maps吗?那个超炫的页面,我们在页面上滚动鼠标中论,就可以实现地图的放大和缩小,我们不断地像后台发送请求,后台也一直在反馈,可是至始至终,我们都没有进行过页面的跳转。
这就是ajax,它负责将用户的请求发送到服务端,然后将接收到的返回数据渲染到当前html中。在这过程中,一直都是在早已渲染好了的html中进行操作。
很自然而然的,因为没有页面的全局刷新,我们就像在操纵本地软件那样操作进行操作,正如single app一词,它就像一个app而不是一个网站。
在具体介绍之前,我们先老生常谈一个问题,如何实现MVC?
我去,这个问题在第一个场景中不就已经讲过了吗。
正如下面所见:
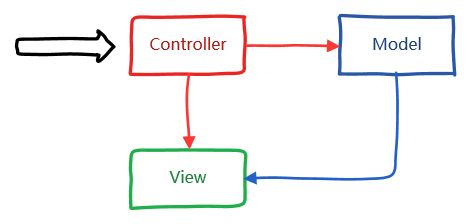 |
由Controller接收请求,将数据封装为 Model 的形式,并将其传入 View 中,毫无难度。
好吧,不是我侮辱大家智商,只是,很多事情并不是我们想当然的那样,正所谓,世事无绝对嘛。
我们来看这张图:
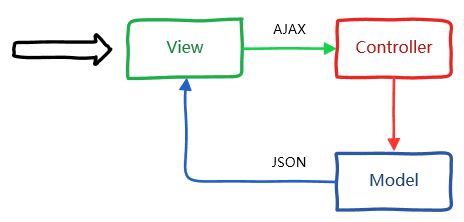 |
在上图的MVC模式中,我们直接在 HTML(也就是 View)中发送 AJAX 请求,该请求由 Action(也就是 Controller)接收,随后将数据模型转为 JSON 格式返回到 HTML 中。
早期前端都是比较简单,基本以页面为工作单元,内容以浏览型为主,也偶尔有简单的表单操作,这个时期每个界面上只有很少的JavaScript逻辑。
随着AJAX的出现,Web2.0的兴起,人们可以在页面上可以做比较复杂的事情了,js针对DOM的操作越来越频繁,于是出现了以简化DOM操作、屏蔽浏览器差异的js库jQuery。(jQuery仅仅是js库,不是框架。。。)
伴随着一些Web产品逐渐往应用方向发展,遇到了在C/S领域相同的问题:由于前端功能的增强、代码的膨胀,js代码变得越来越混乱。
于是我们想起了曾经在后台使用过的方法,各种基于MVC变种模式的前端框架应运而生。
后面真的写不下去了,就这样吧。。。
Aaron 2014.6.19