topics 与 logs
对每个 topic , kafka 集群操作一下如下的分区日志
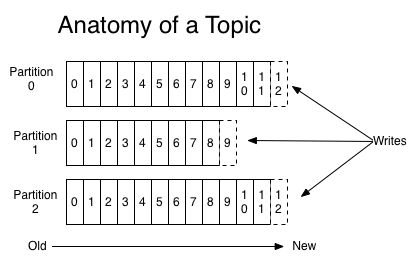
每个 partition 都是一个有序的,不变的信息不断追加的序列——即commit log. partition 中的每条消息都有唯一的有序的偏移量,唯一标识一条信息.
kafka 保存所有发送的消息,保留时间是可配置的,超过保留时间将被删除. kafka 性能稳定,足以保存大量数据.
唯一保存的消费者元数据就是消费者的消费位置偏移量,一般该偏移量将会随着消费者数据的读取线性增加,该偏移量可以由消费者配置,并且可以重置以重复消费.
消费者的增减不会影响集群和其他消费者,可以使用命令行工具查看任何topic的内容,而不改变已存在的消费者状态.
partition在日志服务中的两个作用
- 扩展性: 一个 topic 可以有多个 partition ,可以扩展超过一个单机的容量
- 并行化: 每个分区都是一个平行的单元
分布式
partition 的 log 分布在kafka集群的服务器上,每个服务器处理数据与接收请求的 partition 共享,每个分区可以配置复制的数量进行容错复制.
每个 partition 都有一个 leader 和0个或多个的 follower. leader处理所有的读写请求,而 follower 被动地复制 leader. 如果 leader 挂了, 将有一个 follower 自动变成新的 leader.
producer
producer 发送数据到选择的 topic, producer 负责分配每条消息发往哪个 partition, 可以使用诸如 round-robin 之类的负载均衡算法.
consumer
消息队列有两种模型,分别是队列(queuing)模型和发布订阅(publish-subscribe)模型.队列模型中,消息将会被所有的消费者中的一个消费,而发布订阅模型中,消息广播给所有的消费者. kafka 提供了单一的消费者抽象 consumer group.
消费者使用 consumer group 标记自身,topic中的每条消息被递送给所有订阅了该topic的 consumer group,消费者实例可以是分布在一个机器上的多个进程,或多台机器上.
如果所有的消费者实例都有相同的 consumer group 名, 那他们工作起来就像传统的负载均衡的队列模型.
如果所有的消费者实例都有不同的 consumer group 名, 那他们工作起来就是发布订阅模型,所有的消息将广播给所有的消费者.
通常,每个 topic 都有少量的consumer group, 每个 consumer group 由多个消费实例组成,以提供扩展性与容错性,订阅者是消费者集群而不是单个的进程.
kafka 相对于传统的消息系统有跟前的有序性保证.
传统的队列将消息有序地保存在服务器上.如果多个消费者从队列中消费,服务器按照存储的有序的处理.尽管服务器有序的处理,消息被异步地递送给了消费者,所以他们到达用户时不一定有序.平行消费的情况下,消息顺序性丢失.可以只有一个进程消费,然而这失去了并行性.
kafka 在有序性上做得更好,在 topic 中的每个 partition, kafka 能够提供有序保证与所有消费者进程的负载均衡.这是通过将 topic 中每个 partition 被 consumer group 中的唯一的一个消费者消费.这样能够确保这个消费者是该 partition 的唯一消费者并保证消费有序.由于有多个 partition ,仍然能够在消费者间负载均衡.
注意: 一个consumer group 中不能有多于订阅的 topic 的 partition 数的消费者
kafka 仅仅在 partition 级别提供有序保证,而在一个 topic 中的不同 partition 中无法提供.如果需要在topic级别保证消息有序,可以创建一个只有一个 partition 的 topic,这将意味着只有一个消费者线程.
保证
kafka提供以下保证:
- 消息被生产者发送给特定 topic 下面的 partition,消息会按照发送的顺序有序添加.先到先存.
- 消费者实例将有序地访问存储在 log 里的消息.
- 如果一个topic的复制因子是N,能够允许N-1个服务失效.