TYD深度学习入门 第一章
目录
- 章节1 深度学习必备基础知识
- 课时1 深度学习要解决的问题
- 课时2 深度学习应用领域
- 课时3 计算机视觉任务
- 1.图像在计算机中长什么样
- 2.计算机视觉面临的挑战
- 课时4 视觉任务中遇到的问题
- 1.机器学习常规套路
- 2.数据库样例CIFAR-10
- 3.使用K近邻进行图像分类
- 课时5 得分函数,线性函数
- 课时6 损失函数
- 1.max()损失函数,用的不是特别多了解即可
- 课时7 前向传播流程
章节1 深度学习必备基础知识
课时1 深度学习要解决的问题
人工智能包含了机器学习,机器学习里又包含了深度学习

机器学习流程:数据获取,特征工程,建立模型,评估与应用
不同视角看待神经网络:不应将其看作是算法,而是一种特征提取的方法
数据特征决定了模型的上限,预处理和特征提取是最核心的。算法与参数选择只是决定了如何逼近这个上限。
深度学习就是一个黑盒子,一个数据进到黑盒子里会对其进行自动的数据特征提取,自动学习哪些特征是最好的
课时2 深度学习应用领域
深度学习应用:百分之八九十都是用在计算机视觉和自然语言处理上的 CV(computer vision) 和 NLP
无人驾驶、人脸识别、医学应用:细胞检测、换脸。。。。
ImageNet :公开的图像学习资料库,22000左右的类别,140万的图像

在较小规模的数据集上传统机器学习算法跟深度学习算法效果差不多,但传统算法运行更快,深度学习更适合大量数据规模。
课时3 计算机视觉任务
1.图像在计算机中长什么样
图片分类:比如说有一个数据集里面有很多图片,包含了猫、狗、马、车。。等类别,要将一个猫的图片准确分类成猫

一张图片被表示成三维数组的形式,每个像素的值从0-255
例如: 300 x 100 x 3(300行,100列总共3w个像素点,每个像素点有三种颜色通道RGB)
2.计算机视觉面临的挑战
- 视觉角度地不同
- 形状改变
- 部分被遮蔽
- 物体与背景混合在一起



课时4 视觉任务中遇到的问题
1.机器学习常规套路
1.收集数据并给定标签
2.训练一个分类器
3.测试、评估
2.数据库样例CIFAR-10
10类标签、5w个训练数据,1w个测试数据,图片大小32*32
3.使用K近邻进行图像分类
1.计算已知类别数据集中其他样本到当前样本的距离
2.按照距离依次排序
3.选取与当前点距离最小的K个点
4.确定前K个点所在类别出现概率
5.返回前K个点出现频率最高的类别作为当前点预测分类
在图像识别中,K近邻是通过,将样本测试图片的像素数据 减去 训练图片对应的像素数据 得到像素点间的距离,最后再相加

但是训练效果不好,因为没有告诉算法,哪些是主体,哪些是背景。那样K近邻会将背景相似的图片归到一起。

课时5 得分函数,线性函数
该函数可以算出每个类别的得分值。比如说在一个10分类问题中(猫狗车船…马),一个猫的样本进入这个函数中,这个函数就会算出各个分类的得分
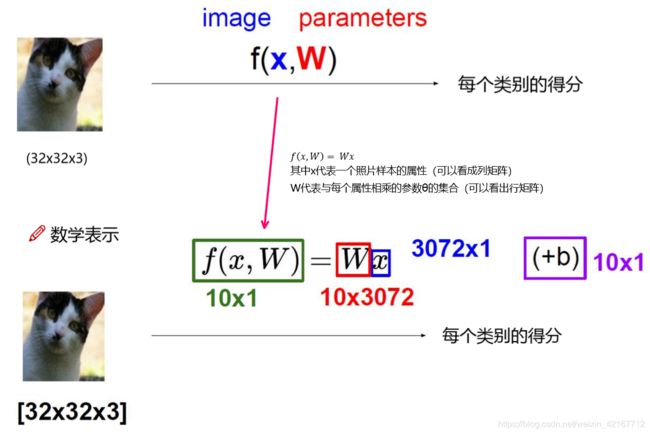
其中b被称作偏置项


W权重参数中值越大,(比如2.1)代表所对应的像素点对结果越有促进作用,值为负数或越小就对分类结果起到抑制作用。
一开始的参数W矩阵的数值都是随机生成的,要不断地进行反向传播和迭代来更改W,那么如何判定哪种W参数矩阵是最好的呢?换句话说:设置为某种W参数后,分类结果是最好的呢?这就需要下面介绍的损失函数,来衡量W参数的好坏
课时6 损失函数
损失函数:衡量分类的结果,要知道一个模型训练出来有多好或有多差
1.max()损失函数,用的不是特别多了解即可
公式中的s是得分score的意思,是由上面的线性函数f算出来的

L = 2.9+0+10 = 12.9(损失越小越好)
小结:衡量一个模型(参数W)的好坏,就需要引入一个损失函数,损失函数包含了数据的损失和正则化惩罚项。我们总是希望模型不要太复杂,过拟合的模型不好
课时7 前向传播流程
 如上,模型A和B得到的损失值都是1,但不意味着他们的模型效果一样。模型A只考虑第一个属性,模型B能叫均匀的考虑到其他属性值。所以就需要考虑加入正则化惩罚项
如上,模型A和B得到的损失值都是1,但不意味着他们的模型效果一样。模型A只考虑第一个属性,模型B能叫均匀的考虑到其他属性值。所以就需要考虑加入正则化惩罚项
有一种正则化惩罚项:

例:一个模型有10个W参数,那么就会有 如下:

捋一捋:有了得分函数,损失函数和正则化惩罚性,算出一个模型的损失函数值来判断这个模型的好坏

- W 和 x 通过线性 f 计算各个分类的得分值
- 利用算出来的得分值来计算其他分类得分跟真实值之间的误差,也就是数据损失(其他分类的得分如果比真实分类的得分要低很多,那么损失就是0)
- 加上正则化惩罚项,看模型参数是不是太复杂
- 结合数据损失+正则化惩罚项 得到损失函数值,来衡量W,也就是所构建的模型的好坏
我们能算得出每个样本的分类值:一个猫的图片样本,算出得分值:马(213),猫(91),车(21)…
我们要想办法将其转换成概率值!!比如说sigmoid函数

神经网络中,使用Softmax分类器,来将score转换成概率值。通过e的x次幂来映射放大score结果,再归一化,就得到概率,再通过log对数函数来算损失函数值

各个分类的得分差异并不大,通过e的x次幂(exp)将其放大,然后通过归一化得到各个分类的概率
然后通过对数函数log计算损失

cat = np.array([3.2,5.1,-1.7])
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c) #防止溢出
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
softmax(cat)
计算损失函数值:
-np.log10(softmax(cat))!![]()
小结:通过softmax分类器计算样本的各个分类的概率,然后计算损失函数