笔试总结(六)
1、什么是同步逻辑?什么是异步逻辑?
同步逻辑是时钟之间有固定的因果关系。异步逻辑是各时钟之间没有固定的因果关系。
同步时序逻辑的特点:各触发器的时钟端全部连接在一起,并接在系统时钟端,只有当时钟脉冲到来时,电路的状态才能改变。改变后的状态将一直保持到下一个时钟脉冲的到来,此时无论外部输入有无变化,状态表中的每个状态都是稳定的。
异步时序逻辑的特点:电路中除可以使用带时钟的触发器外,还可以使用使用不带时钟的触发器和延迟元件作为存储元件,电路中没有统一的时钟,电路状态的改变由外部输入的变化直接引起。
2、同步电路和异步电路的区别?
同步电路:存储电路中所有触发器的时钟输入端都连接在同一个时钟脉冲源,因而所有触发器的状态的变化与所加时钟脉冲信号同步。
异步电路:电路没有统一的时钟,有些触发器的时钟输入端与时钟脉冲源相连,只有这些触发器的状态变化与时钟脉冲同步,而其他的触发器的状态变化不与时钟脉冲同步。
3、时序设计的实质?
时序设计的实质就是满足每一个触发器的建立/保持时间。
4、建立时间与保持时间的概念?
建立时间:触发器在时钟上升沿到来之前,其数据输入端的数据必须保持不变的最小时间。
保持时间:触发器在时钟上升沿到来之后,其数据输入端的数据必须保持不变的最小时间。
5、为什么触发器要满足建立时间和保持时间?
因为触发器内部数据的形成是需要一定的时间,如果不满足建立时间和保持时间,触发器将进入亚稳态,进入亚稳态后触发器的输出将不稳定,在0和1之间变化,这时需要经过一个恢复时间,其输出才能稳定,但稳定后的值不一定是输入的值。这就是为什么要用两级触发器来同步异步输入信号。这样做可以防止由于异步输入信号对于本级时钟可能不满足建立时间而使本级触发器产生的亚稳态传输到后面的逻辑中,导致亚稳态传播。
或者说:需要建立时间是因为触发器的D端像一个锁存器在接收数据,为了稳定的设置前级门的状态需要一段稳定时间;需要保持时间是因为在时钟沿到来之后,触发器要通过反馈来锁存状态,从后级门到前级门需要时间。
6、什么是亚稳态?为什么两级触发器可以防止亚稳态传播?
亚稳态是指触发器无法在某个规定的时间段内到达一个可以确认的状态。使用两级触发器来使异步电路同步化的电路其实叫做“一位同步器”。他只能用来对一位异步信号进行同步。两级触发器可以防止亚稳态传播的原理:假设第一级触发器的输入不满足其建立保持时间,它在第一个脉冲沿到来后输出的数据就为亚稳态,那么在下一个脉冲沿到来之前,其输出的亚稳态数据在一段恢复时间之后必须稳定下来,而且稳定的数据必须满足第二级触发器的建立时间,如果都满足了,在下一个脉冲沿到来时,第二级触发器将不会出现亚稳态,因为其输入端的数据满足其建立保持时间。同步器有效的条件:第一级触发器进入亚稳态后的恢复时间 + 第二级触发器的建立时间 < = 时钟周期。
更确切地说,输入脉冲宽度必须大于同步时钟周期与第一级触发器所需的保持时间之和。最保险的脉冲宽度是两倍同步时钟周期。所以,这样的同步电路对于从较慢的时钟域来的异步信号进入较快的时钟域比较有效,对于进入一个较慢的时钟域,则没有作用 。
7、对于多位的异步信号如何进行同步?
对以一位的异步信号可以使用“一位同步器进行同步”(使用两级触发器),而对于多位的异步信号,可以采用如下方法:1:可以采用保持寄存器加握手信号的方法(多数据,控制,地址);2:特殊的具体应用电路结构,根据应用的不同而不同;3:异步FIFO。(最常用的缓存单元是DPRAM)
8、锁存器(latch)和触发器(flip-flop)区别?
电平敏感的存储器件称为锁存器。可分为高电平锁存器和低电平锁存器,用于不同时钟之间的信号同步。
有交叉耦合的门构成的双稳态的存储原件称为触发器。分为上升沿触发和下降沿触发。可以认为是两个不同电平敏感的锁存器串连而成。前一个锁存器决定了触发器的建立时间,后一个锁存器则决定了保持时间。
9、什么是时钟抖动?
时钟抖动是指芯片的某一个给定点上时钟周期发生暂时性变化,也就是说时钟周期在不同的周期上可能加长或缩短。它是一个平均值为0的平均变量。
10、寄生效应在IC设计中怎样加以克服和利用(这是我的理解,原题好像是说,IC设计过程中将寄生效应的怎样反馈影响设计师的设计方案)?
所谓寄生效应就是那些溜进你的PCB并在电路中大施破坏、令人头痛、原因不明的小故障。它们就是渗入高速电路中隐藏的寄生电容和寄生电感。其中包括由封装引脚和印制线过长形成的寄生电感;焊盘到地、焊盘到电源平面和焊盘到印制线之间形成的寄生电容;通孔之间的相互影响,以及许多其它可能的寄生效应。
理想状态下,导线是没有电阻,电容和电感的。而在实际中,导线用到了金属铜,它有一定的电阻率,如果导线足够长,积累的电阻也相当可观。两条平行的导线,如果互相之间有电压差异,就相当于形成了一个平行板电容器(你想象一下)。通电的导线周围会形成磁场(特别是电流变化时),磁场会产生感生电场,会对电子的移动产生影响,可以说每条实际的导线包括元器件的管脚都会产生感生电动势,这也就是寄生电感。
在直流或者低频情况下,这种寄生效应看不太出来。而在交流特别是高频交流条件下,影响就非常巨大了。根据复阻抗公式,电容、电感会在交流情况下会对电流的移动产生巨大阻碍,也就可以折算成阻抗。这种寄生效应很难克服,也难摸到。只能通过优化线路,尽量使用管脚短的SMT元器件来减少其影响,要完全消除是不可能的。
11、什么是竞争与冒险现象?怎样判断?如何消除?
在组合电路中,某一输入变量经过不同途径传输后,到达电路中某一汇合点的时间有先有后,这种现象称竞争;由于竞争而使电路输出发生瞬时错误的现象叫做冒险。(也就是由于竞争产生的毛刺叫做冒险)。
判断方法:
代数法(如果布尔式中有相反的信号则可能产生竞争和冒险现象);卡诺图:有两个相切的卡诺圈并且相切处没有被其他卡诺圈包围,就有可能出现竞争冒险;实验法:示波器观测;
解决方法:
1:加滤波电容,消除毛刺的影响;2:加选通信号,避开毛刺;3:增加冗余项消除逻辑冒险。
门电路两个输入信号同时向相反的逻辑电平跳变称为竞争;
由于竞争而在电路的输出端可能产生尖峰脉冲的现象称为竞争冒险。
如果逻辑函数在一定条件下可以化简成Y=A+A’或Y=AA’则可以判断存在竞争冒险现象(只是一个变量变化的情况)。
消除方法,接入滤波电容,引入选通脉冲,增加冗余逻辑
12、你知道那些常用逻辑电平?TTL与COMS电平可以直接互连吗?
常用逻辑电平:TTL、CMOS、LVTTL、LVCMOS、ECL(Emitter Coupled Logic)、PECL(Pseudo/Positive Emitter Coupled Logic)、LVDS(Low Voltage Differential Signaling)、GTL(Gunning Transceiver Logic)、BTL(Backplane Transceiver Logic)、ETL(enhanced transceiver logic)、GTLP(Gunning Transceiver Logic Plus);RS232、RS422、RS485(12V,5V,3.3V);
也有一种答案是:常用逻辑电平:12V,5V,3.3V。
TTL和CMOS不可以直接互连,由于TTL是在0.3-3.6V之间,而CMOS则是有在12V的有在5V的。CMOS输出接到TTL是可以直接互连。TTL接到 CMOS需要在输出端口加一上拉电阻接到5V或者12V。
用CMOS可直接驱动TTL;加上拉电阻后,TTL可驱动CMOS.
上拉电阻用途:
a、当TTL电路驱动COMS电路时,如果TTL电路输出的高电平低于COMS电路的最低高电平(一般为3.5V),这时就需要在TTL的输出端接上拉电阻,以提高输出高电平的值。
b、OC门电路必须加上拉电阻,以提高输出的高电平值。
c、为加大输出引脚的驱动能力,有的单片机管脚上也常使用上拉电阻。
d、在COMS芯片上,为了防止静电造成损坏,不用的管脚不能悬空,一般接上拉电阻产生降低输入阻抗,提供泄荷通路。
e、芯片的管脚加上拉电阻来提高输出电平,从而提高芯片输入信号的噪声容限增强抗干扰能力。
f、提高总线的抗电磁干扰能力。管脚悬空就比较容易接受外界的电磁干扰。
g、长线传输中电阻不匹配容易引起反射波干扰,加上下拉电阻是电阻匹配,有效的抑制反射波干扰。
上拉电阻阻值的选择原则包括:
a、从节约功耗及芯片的灌电流能力考虑应当足够大;电阻大,电流小。
b、从确保足够的驱动电流考虑应当足够小;电阻小,电流大。
c、对于高速电路,过大的上拉电阻可能边沿变平缓。综合考虑以上三点,通常在1k到10k之间选取。对下拉电阻也有类似道理。
OC门电路必须加上拉电阻,以提高输出的高电平值。
OC门电路要输出“1”时才需要加上拉电阻不加根本就没有高电平
在有时我们用OC门作驱动(例如控制一个 LED)灌电流工作时就可以不加上拉电阻
总之加上拉电阻能够提高驱动能力。
14、说说静态、动态时序模拟的优缺点?
静态时序分析是采用穷尽分析方法来提取出整个电路存在的所有时序路径,计算信号在这些路径上的传播延时,检查信号的建立和保持时间是否满足时序要求,通过对最大路径延时和最小路径延时的分析,找出违背时序约束的错误。它不需要输入向量就能穷尽所有的路径,且运行速度很快、占用内存较少,不仅可以对芯片设计进行全面的时序功能检查,而且还可利用时序分析的结果来优化设计,因此静态时序分析已经越来越多地被用到数字集成电路设计的验证中。
动态时序模拟就是通常的仿真,因为不可能产生完备的测试向量,覆盖门级网表中的每一条路径。因此在动态时序分析中,无法暴露一些路径上可能存在的时序
15、给出一个门级的图,又给了各个门的传输延时,问关键路径是什么,还问给出输入, 使得输出依赖于关键路径?
关键路径就是输入到输出延时最大的路径,找到了关键路径便能求得最大时钟频率。
16、基尔霍夫定理的内容
基尔霍夫定律包括电流定律和电压定律:
电流定律:在集总电路中,在任一瞬时,流向某一结点的电流之和恒等于由该结点流出的电流之和。
电压定律:在集总电路中,在任一瞬间,沿电路中的任一回路绕行一周,在该回路上电动势之和恒等于各电阻上的电压降之和。
17、Xilinx FPGA底层资源
芯片的主要资源分为以下几个方面:
(1)slice资源
(2)slice-logic distribution
(3)register寄存器
(4)Memory存储器
(5)DSP资源
(6)IO和GT
(7)clocking时钟
(8)primitive原语
(9)black boxes黑盒子
(10)Instantiated Netlists实例化网络
FPGA内部详细结构细分为以下六大模块:
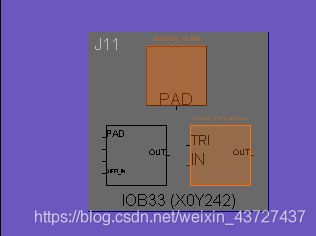
(1)可编程输入输出单元(IOB)(input output block)
为了便于管理和适应多种电气标准,FPGA的IOB被划分为若干个组(Bank),每个bank的接口标准由其接口电压vcco决定,一个bank只能有一种vcco,但不同的bank的vcco可以不同,只有相同电气标准和物理特性的端口才能连接在一起,vcco电压相同是接口标准的基本条件。
(2)可配置逻辑块(CLB)(configurable logic Block)
FPGA的基本逻辑单元是CLB,而一个CLB是由查找表、数据选择器、进位链、寄存器组成的。查找表和多路选择器完成组合逻辑功能,寄存器(可配置成触发器或锁存器),完成时序逻辑功能。在赛灵思公司的FPGA器件中,一个CLB由多个(一般为4个或2个)相同的slice和附加逻辑构成。
slice又分为SLICEL(logic)和SLICEM(Memory),SLICEL和SLICEM内部都各自包含4个6输出查找表(LUT6)、3个数据选择器(Mux)、一个进位链(Carry Chain)和8个触发器(Flip-Flop)。
查找表:6输入查找表类似一个容量为64bit的ROM(工艺上是珍贵的SRAM资源),6表示地址输入位宽为6bits,存储的内容作为输入对应的输出结果的逻辑运算,并在FPGA配置时载入。
对于查找表:目前主流FPGA都采用了基于SRAM工艺的查找表(LUT)(Look Up Table)结构。LUT实质上就是一个RAM。当用户通过原理图或HDL语言描述了一个逻辑电路以后,FPGA开发软件会自动计算逻辑电路的所有可能结果。列成一个真值表的形式,并把真值表(即输入对应的输出逻辑)事先写入RAM,这样每输入一个信号进行逻辑运算就等于输入一个地址进行查表,找出地址对应的内容,然后输出即可。目前FPGA多使用4输入的LUT,所以每一个LUT可以看成是一个有4位地址线的RAM。
数据选择器:数据选择器一般在FPGA配置后固定下来
进位链:超前进位加法器,方便加法器的实现,加快复杂加法的运算。
寄存器:可以配置成多种工作方式,比如FF或Latch,同步复位或异步复位、复位高有效或低有效等等。
SLICEM的结构和SLICEL的结构类似,最大的区别是使用了一个新的单元替代了SLICE中查找表。这个新的单元可以配置为LUT、RAM、ROM或移位寄存器(SRL16或SRL32),从而实现LUT的逻辑功能,也能做存储单元(多个单元组合起来可以提供更大的容量)和移位寄存器(提供延迟等功能)
(3)嵌入式块RAM(BRAM)(Block RAM)
块 RAM 可被配置为 ROM、RAM 以及 FIFO 等常用的存储模块。区别于分布式 RAM(Distributed RAM)(主要由 LUT 组成的,不占用 BRAM 的资源)。分布式 RAM 也可以被配置为 ROM、RAM 以及 FIFO 等常用的存储模块,但是性能不如 BRAM,毕竟 BRAM 才是专用的,一般是 BRAM 资源不够用的情况下才使用分布式 RAM。反之,BRAM 由一定数量固定大小的存储块构成的,使用 BRAM 资源不占用额外的逻辑资源,并且速度快,不过使用的时候消耗的 BRAM 资源只能是其块大小的整数倍,就算你只存了 1 bit 也要占用一个 BRAM。
一个 BRAM 的大小为 36K Bits,并且分成两个小的 BRAM 各自为 18K Bits,排列成又分为上下两块,上半部分为 RAMB18 下半部分为 RAMBFIFO36。在 FIFO 例化的时候可以将 BRAM 设置为 FIFO 时,不会使用额外的 CLB 资源,并且这部分 RAM 是真双口 RAM。
FPGA所采用的逻辑单元阵列LCA(Logic Cell Array)内部所包括的可配置逻辑模块 CLB(Configurable Logic Block)、 输出输入模块 IOB(Input Output Block)和内部互连线(Interconnect)三个部分。
(4)互连线资源(Interconnect)
布线资源连通FPGA内部的所有单元,而连线的长度和工艺决定着信号在连线上的驱动能力和传输速度。FPGA芯片内部有着丰富的布线资源,根据工艺、长度、宽度和分布位置的不同而分为4类不同的类别:第一类是全局布线资源,用于芯片内部全局时钟和全局复位/置位的布线。第二类是长线资源,用于完成芯片Bank间的高速信号和第二全局时钟信号的布线;第三类是短线资源,用于完成基本逻辑单元之间的逻辑互连和布线;第四类是分布式布线资源,用于专用时钟、复位等控制信号线。
(5)底层内嵌功能单元
内嵌功能模块主要指 DLL(Delay Locked Loop)、PLL(Phase Locked Loop)、DSP(Digital System Processing)(数字信号处理)、DCM(Digital Clock Manager)(提供数字时钟管理和相位环路锁定)、和 CPU(Central Processing Unit)等等软处理核(比如 MicroBlaze 的软核)。现在越来越丰富的内嵌功能单元,使得单片 FPGA 成为了系统级的设计工具,使其具备了软硬件联合设计的能力,逐步向 SoC 平台过渡。
关于 DCM:DCM 是 FPGA 内部处理时钟的重要器件,他的作用主要有三个:消除时钟偏斜(Clock De-Skew)、频率合成(Frequency Synthesis)和相位调整(Phase Shifting)。
DCM 的核心器件是数字锁相环(DLL,Delay Locked Loop)。它是由一串固定时延的延时器组成,每一个延时器的时延为 30 皮秒,也就是说,DCM 所进行的倍频、分频、调相的精度为 30 皮秒。
对于时钟,我们最好不要将两个时钟通过一个与门或者或门(逻辑操作),这样的话就很可能会产生毛刺,影响系统稳定性,如果要对时钟进行操作,例如切换时钟等,请使用 FPGA 内部的专用器件 “BUFG MUX”。
(6)内嵌专用硬核
内嵌专用硬核是相对底层嵌入的软核而言的,指 FPGA 处理能力强大的硬核(比如 ARM Cortex-A9 的硬核),等效于 ASIC 电路。为了提高 FPGA 性能,芯片生产商在芯片内部集成了一些专用的硬核。例如为了提高 FPGA 的乘法速度,主流的 FPGA 中都集成了专用乘法器,而为了适用通信总线与接口标准,很多高端的 FPGA 内部都集成了串并收发器(Serdes),可以达到数十 Gbps 的收发速度(比如 GTX)。
(7)DSP计算单元
FPGA中的DSP主要是用于乘法/除法的累加单元,一般的除法需要单独设计,因为FPGA中的除法需要好几个DSP搭起来才能构成一个除法器,非常消耗资源。而且在K7系列中都是DSP48,最大支持乘积的位宽是43bits(乘数因子1为25bits,乘数因子2为18bits),累加器单元为48bits。
18、二进制、格雷码、独热码的利弊。
二进制编码、格雷码编码使用最少的触发器,消耗较多的组合逻辑,而独热码反之。独热码编码最大的优势在于状态比较时仅仅需要比较一个位,从而一定程度上简化了译码逻辑。虽然在需要表示同样的状态数时,独热码占用较多的位,也就是消耗较多的触发器,但这些额外的触发器占用的面积可以与译码电路省下的面积相抵消。
为了进一步提高独热编码的速度,可以使用并行case语句“即在case(1‘b1’)后添加综合器可以辨认的并行case注释语句”。并行case只推荐在独热编码时使用,在二进制编码和格雷编码时使用有时反而会增大面积降低速度。
在CPLD中,由于器件拥有较多的地提供组合逻辑资源,所以CPLD多使用二进制编码或格雷码,而FPGA更多地提供触发器资源,所以在FPGA中多使用独热码编码。当然,这并不是说在FPGA中就非得用独热编码,在CPLD中不能用独热编码,一般的,对于小型设计(状态数小于4)使用二进制编码,当状态数处于4-24之间时,宜采用独热码编码,而大型状态机(状态数大于24)使用格雷码更高效。
有限状态机编码时采用格雷码和采用独热码的选择
格雷码:相邻之间只变1bit,编码密度高。
独热码:任何状态只有1bit为1,其余皆为0,编码密度低。
比如说,表示4个状态,那么状态机寄存器采用格雷码编码只需要2bit:00(S0),01(S1),11(S2),10(S3);
采用独热码需要4bit:0001(S0),0010(S1),0100(S2),1000(S3)。所以很明显采用格雷码可以省2bit寄存器。难理解的是,为什么独热码更节省组合逻辑:其实很简单。
例一:
假如我们要在代码中判断状态机是否处于某状态S1,对于格雷码的状态机来说,代码是这样的:assign S1 = (STATUS==2’b01);对于独热码来说,代码是这样的就行:assign S1=STATUS[1];所以独热码的译码非常简单。
例二:
考虑最简单的跳变,当A为1时,状态机会从S0跳到S1:。采用格雷码写:STATUS[1:0] <= (STATUS==2’h00) & A ? 2’h01 : 2’h00;采用独热码写:STATUS[1] <= STATUS[0] & A;
有人怀疑这里的逻辑,认为只check独热码的一个bit有问题。当然是没问题的,0110,0011等编码属于不care的编码,在卡诺图化简中,不care的编码可以与其余的有效编码合并化简。实际上综合器也会这么做,所以独热码非常容易化简。
假如说S0跳到S1条件为A;S1跳到S2条件为B;S2跳到S3条件为C;S3跳到S0条件为D;那么整个状态机化简之后代码就是:
STATUS[0] <= STATUS[3] & D;
STATUS[1] <= STATUS[0] & A;
STATUS[2] <= STATUS[1] & B;
STATUS[3] <= STATUS[2] & C;
独热码适合写条件复杂但是状态少的状态机;
格雷码适合写条件不复杂但是状态多的状态机。