大数据技术之Hadoop(YARN的搭建)与SHELL脚本(集群分发脚本xsync)
大数据技术之Hadoop(YARN的搭建)与SHELL脚本(集群分发脚本xsync)
1.YARN的搭建
1.1集群部署规划
 1.2配置YARN
1.2配置YARN
1.在配置的hadoop集群中选择hadoop112:进入hadoop目录
cd /usr/local/hadoop/hadoop-2.9.2/etc/hadoop/
2.配置文件yarn-env.sh
vim yarn-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_211
3.配置文件yarn-site.xml(注意resourcemanager的选择)
vim yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop112</value>
</property>
4.将配置文件发送给另外两台
4.1下载rsync:yum -y install rsync
4.2进行发送:
cd /usr/local/hadoop/hadoop-2.9.2/etc
rsync -rvl hadoop/ hadoop111:/usr/local/hadoop/hadoop-2.9.2/etc/hadoop/
rsync -rvl hadoop/ hadoop113:/usr/local/hadoop/hadoop-2.9.2/etc/hadoop/
5.启动YARN
start-yarn.sh



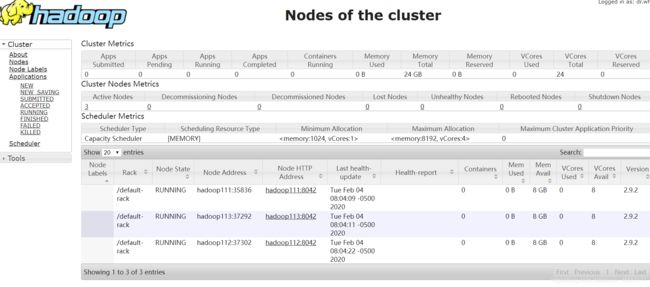
6.谷歌访问:http://192.168.222.112:8088/cluster
2.Shell脚本
详细链接:https://www.runoob.com/linux/linux-shell.html
2.1 Shell 脚本
Shell 脚本(shell script),是一种为 shell 编写的脚本程序。
业界所说的 shell 通常都是指 shell 脚本,但读者朋友要知道,shell 和 shell script 是两个不同的概念。
由于习惯的原因,简洁起见,本文出现的 “shell编程” 都是指 shell 脚本编程,不是指开发 shell 自身。
2.2 Shell 环境
Shell 编程跟 JavaScript、php 编程一样,只要有一个能编写代码的文本编辑器和一个能解释执行的脚本解释器就可以了。
Linux 的 Shell 种类众多,常见的有:
Bourne Shell(/usr/bin/sh或/bin/sh)
Bourne Again Shell(/bin/bash)
C Shell(/usr/bin/csh)
K Shell(/usr/bin/ksh)
Shell for Root(/sbin/sh)
……
本教程关注的是 Bash,也就是 Bourne Again Shell,由于易用和免费,Bash 在日常工作中被广泛使用。同时,Bash 也是大多数Linux 系统默认的 Shell。
在一般情况下,人们并不区分 Bourne Shell 和 Bourne Again Shell,所以,像 #!/bin/sh,它同样也可以改为 #!/bin/bash。
#! 告诉系统其后路径所指定的程序即是解释此脚本文件的 Shell 程序。
2.3 第一个shell脚本
打开文本编辑器(可以使用 vi/vim 命令来创建文件),新建一个文件 test.sh,扩展名为 sh(sh代表shell),扩展名并不影响脚本执行,见名知意就好,如果你用 php 写 shell 脚本,扩展名就用 php 好了。
输入一些代码,第一行一般是这样:
#!/bin/bash
echo "Hello World !"
#! 是一个约定的标记,它告诉系统这个脚本需要什么解释器来执行,即使用哪一种 Shell。
echo 命令用于向窗口输出文本。
2.4运行 Shell 脚本有两种方法:
1、作为可执行程序
将上面的代码保存为 test.sh,并 cd 到相应目录:
chmod +x ./test.sh #使脚本具有执行权限
./test.sh #执行脚本
注意,一定要写成 ./test.sh,而不是 test.sh,运行其它二进制的程序也一样,直接写 test.sh,linux 系统会去 PATH 里寻找有没有叫 test.sh 的,而只有 /bin, /sbin, /usr/bin,/usr/sbin 等在 PATH 里,你的当前目录通常不在 PATH 里,所以写成 test.sh 是会找不到命令的,要用 ./test.sh 告诉系统说,就在当前目录找。
2、作为解释器参数
这种运行方式是,直接运行解释器,其参数就是 shell 脚本的文件名,如:
/bin/sh test.sh
/bin/php test.php
这种方式运行的脚本,不需要在第一行指定解释器信息,写了也没用。
3.编写集群分发脚本xsync
3.1. scp(secure copy)安全拷贝
(1)scp定义:
scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
(2)基本语法
scp -r $pdir/$fname $user@hadoop$host:$pdir/$fname
命令 递归 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
(3)案例实操
(a)在hadoop111上,将hadoop111中/opt/module目录下的软件拷贝到hadoop112上。
scp -r /opt/module root@hadoop112:/opt/module
3.2 rsync 远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
(1)基本语法
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
选项参数说明
 (2)案例实操
(2)案例实操
(a)把hadoop111机器上的/opt/software目录同步到hadoop112服务器的root用户下的/opt/目录
rsync -rvl /opt/software/ root@hadoop112:/opt/software
3.3xsync集群分发脚本
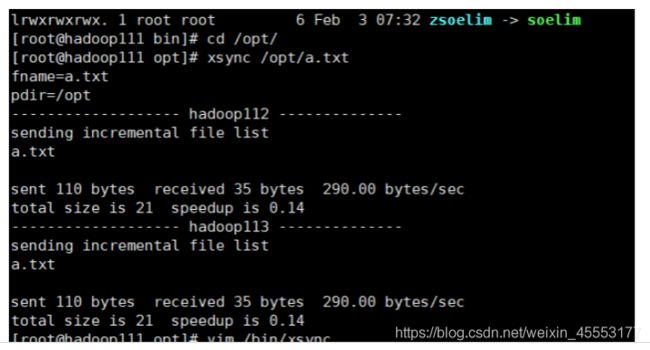
1.在 /bin/目录下创建xsync( rsync版)
vim /bin/xsync
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=112; host<114; host++)); do
echo ------------------- hadoop$host --------------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
2.在 /bin/目录下创建xsync( scp版)
vim /bin/xsync
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=112; host<114; host++)); do
echo ------------------- hadoop$host --------------
scp -r $pdir/$fname $user@hadoop$host:$pdir/$fname
done
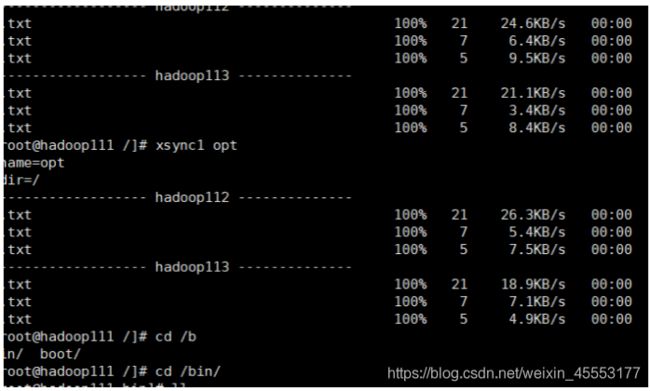
3.脚本的实现
(1)修改脚本 xsync 具有执行权限
chmod 777 xsync
chmod +x xsync
(2)调用脚本形式:xsync 文件名称
xsync a.txt