NULL函数
NULL 是一种数据类型,表示 SQL 中没有数据。它们经常在聚合函数中被忽略了,在下个部分学习使用 COUNT 时你将首次接触到这一现象。
注意,NULL 与零不同,它们表示不存在数据的单元格。
在以下两种常见情况下,你可能会遇到 NULL:
在执行 LEFT JOIN 或 RIGHT JOIN 时,NULL 经常会发生。你在上节课见到了,左侧表格中的某些行在做连接时与右侧表格中的行如果不匹配,这些行在结果集中就会包含一些 NULL 值。
NULL 也可能是因为数据库中缺失数据。
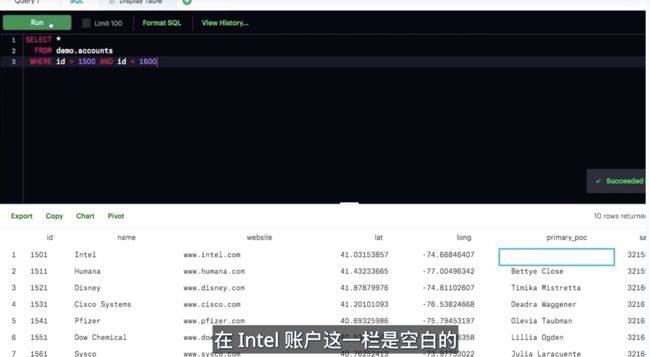
提示
在 WHERE 条件中表示 NULL 时,我们写成 IS NULL 或 IS NOT NULL。我们不使用 =,因为 NULL 在 SQL 中不属于值。但是它是数据的一个属性。

第一个聚合函数
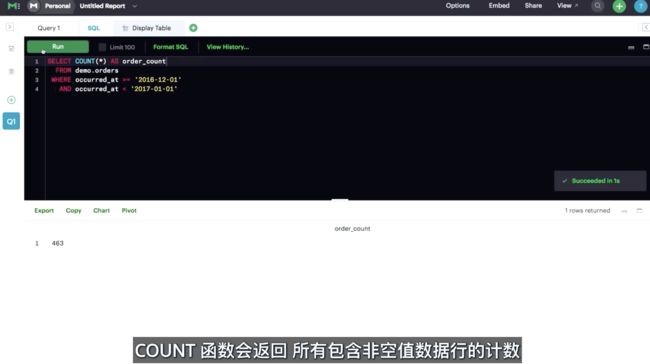
计算表格中的行数
试着手动数数每个表格的行数。以下是计算 accounts 表格中的行数示例:
SELECT COUNT(*)
FROM accounts;
我们也可以轻松地选择一列来放置聚合函数:
SELECT COUNT(accounts.id)
FROM accounts;
SUM
与 COUNT 不同,你只能针对数字列使用 SUM。但是,SUM 将忽略 NULL 值,把它当0来计算,其他聚合函数也是这样。
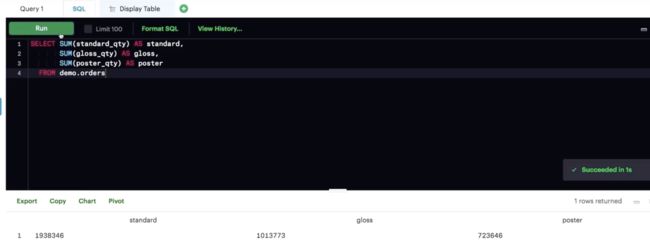
聚合函数
重要注意事项:聚合函数只能垂直聚合,即聚合列的值。如果你想对行进行计算,可以使用简单算术表达式。

答案
SUM 解决方案
算出 orders 表格中的 poster_qty 纸张总订单量。
SELECT SUM(poster_qty) AS total_poster_sales
FROM orders;
算出 orders 表格中 standard_qty 纸张的总订单量。
SELECT SUM(standard_qty) AS total_standard_sales
FROM orders;
根据 orders 表格中的 total_amt_usd 得出总销售额。
SELECT SUM(total_amt_usd) AS total_dollar_sales
FROM orders;
算出 orders 表格中每个订单在 standard 和 gloss 纸张上消费的数额。结果应该是表格中每个订单的金额。
注意,此解决方案没有使用聚合函数。
SELECT standard_qty + gloss_qty AS total_standard_gloss
FROM orders;
每个订单的 price/standard_qty 纸张各不相同。我想得出 orders 表格中每个销售机会的这一比例。
注意,此解决方案使用了聚合函数和数学运算符
SELECT SUM(standard_amt_usd)/SUM(standard_qty) AS standard_price_per_unit
FROM orders;
MIN MAX
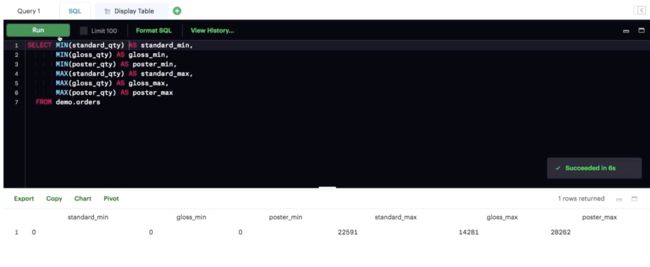
此处我们同时获得了每个纸张类型的 MIN 和 MAX 订单量。但是,你也可以单独计算每个类型的订单量。
注意,MIN 和 MAX 聚合函数也会忽略 NULL 值。请参阅以下专家提示,了解关于 MAX 与 MIN 的实用技巧。
提示
从功能上来说,MIN 和 MAX 与 COUNT 相似,它们都可以用在非数字列上。MIN 将返回最小的数字、最早的日期或按字母表排序的最之前的非数字值,具体取决于列类型。MAX 则正好相反,返回的是最大的数字、最近的日期,或与“Z”最接近(按字母表顺序排列)的非数字值。
AVG
与其他软件类似,AVG 返回的是数据的平均值,即列中所有的值之和除以列中值的数量。该聚合函数同样会忽略分子和分母中的 NULL 值。
如果你想将 NULL 当做零,则需要使用 SUM 和 COUNT。但是,如果 NULL 值真的只是代表单元格的未知值,那么这么做可能不太合适。
MEDIAN - 提示
注意,中值可能是更好的衡量方式,但是仅使用 SQL 非常棘手,以至于有时候在面试中就会提到关于中值方面的问题。
练习与答案
解决方案:MIN、MAX 与 AVERAGE
根据以下 SQL 表格信息回答以下问题。如果你遇到问题或想要对比检查你的答案,可以在下一部分的页面中找到我的答案。
- 最早的订单下于何时?
SELECT MIN(occurred_at)
FROM orders;
- 尝试执行和第一个问题一样的查询,但是不使用聚合函数。
SELECT occurred_at
FROM orders
ORDER BY occurred_at
LIMIT 1;
- 最近的 web_event 发生在什么时候?
SELECT MAX(occurred_at)
FROM web_events;
- 尝试以另一种方式执行上个问题的查询,不使用聚合函数。
SELECT occurred_at
FROM web_events
ORDER BY occurred_at DESC
LIMIT 1;
- 算出每个订单在每种纸张上消费的平均 (AVERAGE) 金额,以及每个订单针对每种纸张购买的平均数量。最终答案应该有 6 个值,每个纸张类型平均销量对应一个值,以及平均数量对应一个值。
SELECT AVG(standard_qty) mean_standard, AVG(gloss_qty) mean_gloss,
AVG(poster_qty) mean_poster, AVG(standard_amt_usd) mean_standard_usd,
AVG(gloss_amt_usd) mean_gloss_usd, AVG(poster_amt_usd) mean_poster_usd
FROM orders;
你可能对如何计算中位数感兴趣。虽然这已经超出了目前我们所学的范围,但请尝试探索这个问题:对于所有订单(orders)数据,其total_usd字段的中位数是多少?请注意,构建一个此问题的通用解决方案已经超出了目前所学的课程范围,但我们可以硬写出以下这段代码:
SELECT *
FROM (SELECT total_amt_usd
FROM orders
ORDER BY total_amt_usd
LIMIT 3457) AS Table1
ORDER BY total_amt_usd DESC
LIMIT 2;
因为订单一共有6912个,因此我们需要第3456和第3457个订单(按total_amt_usd排序)的total_amt_usd字段的平均值。这样就能得出中位数结果,为2482.855。这显然不是一个好办法。如果我们有了新订单,再次计算时就必须修改LIMIT。SQL实际上并不会为我们计算中位数。以上代码使用了一个子查询(SUBQUERY),但你可以使用任何方法找到需要的两个值,然后再求平均即可得到中位数。
GROUP BY
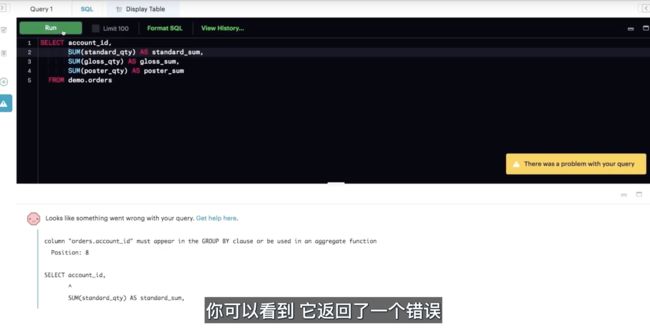
使用GROUP BY语句对数据进行聚合,这样加起来的和就是按照ACCOUNT了进行排列的了,但是需要加上WHERE

- GROUP BY 可以用来在数据子集中聚合数据。例如,不同客户、不同区域或不同销售代表分组。
- SELECT 语句中的任何一列如果不在聚合函数中,则必须在 GROUP BY 条件中。
- GROUP BY 始终在 WHERE 和 ORDER BY 之间。
- ORDER BY 有点像电子表格软件中的 SORT。
提示
在深入了解如何使用 GROUP BY 语句聚合函数之前,需要注意的是,SQL 在 LIMIT 条件之前评估聚合函数。如果不按任何列分组,则结果是 1 行,没有问题。如果按照某列分组,该列中存在大量的唯一值,超出了 LIMIT 上限,则系统会照常计算聚合结果,但是结果中会忽略某些行。
这实际上是比较不错的方式,因为你知道你将获得正确的聚合结果。如果 SQL 将表格裁剪到 100 行,然后进行聚合,结果将完全不同。上述查询的结果超过了 100 行,因此是个很好的示例。在下一部分,使用该 SQL 表格并尝试删掉 LIMIT,然后再次运行查询,看看有哪些变化。
练习
问题:GROUP BY
根据以下 SQL 表格信息回答以下问题。
难点是,何时使用某个聚合函数或其他 SQL 功能最简单。请尝试回答以下问题,看看你能否找到最简单的解决方案。
哪个客户(按照名称)下的订单最早?你的答案应该包含订单的客户名称和日期。
算出每个客户的总销售额(单位是美元)。答案应该包括两列:每个公司的订单总销售额(单位是美元)以及公司名称。
最近的 web_event 是通过哪个渠道发生的,与此 web_event 相关的客户是哪个?你的查询应该仅返回三个值:日期、渠道和客户名称。
算出 web_events 中每种渠道的次数。最终表格应该有两列:渠道和渠道的使用次数。
与最早的 web_event 相关的主要联系人是谁?
每个客户所下的最小订单是什么(以总金额(美元)为准)。答案只需两列:客户名称和总金额(美元)。从最小金额到最大金额排序。
算出每个区域的销售代表人数。最早表格应该包含两列:区域和 sales_reps 数量。从最少到最多的代表人数排序。
答案
- 哪个客户(按照名称)下的订单最早?你的答案应该包含订单的客户名称和日期。
SELECT a.name, o.occurred_at
FROM accounts a
JOIN orders o
ON a.id = o.account_id
ORDER BY occurred_at
LIMIT 1;
- 算出每个客户的总销售额(单位是美元)。答案应该包括两列:每个公司的订单总销售额(单位是美元)以及公司名称。
SELECT a.name, SUM(total_amt_usd) total_sales
FROM orders o
JOIN accounts a
ON a.id = o.account_id
GROUP BY a.name;
- 最近的 web_event 是通过哪个渠道发生的,与此 web_event 相关的客户是哪个?你的查询应该仅返回三个值:日期、渠道和客户名称。
SELECT w.occurred_at, w.channel, a.name
FROM web_events w
JOIN accounts a
ON w.account_id = a.id
ORDER BY w.occurred_at DESC
LIMIT 1;
- 算出 web_events 中每种渠道的次数。最终表格应该有两列:渠道和渠道的使用次数。
SELECT w.channel, COUNT(*)
FROM web_events w
JOIN accounts a
ON a.id = w.account_id
GROUP BY w.channel
- 与最早的 web_event 相关的主要联系人是谁?
SELECT a.primary_poc
FROM web_events w
JOIN accounts a
ON a.id = w.account_id
ORDER BY w.occurred_at
LIMIT 1;
- 每个客户所下的最小订单是什么(以总金额(美元)为准)。答案只需两列:客户名称和总金额(美元)。从最小金额到最大金额排序。
SELECT a.name, MIN(total_amt_usd) smallest_order
FROM accounts a
JOIN orders o
ON a.id = o.account_id
GROUP BY a.name
ORDER BY smallest_order;
奇怪的是,很多订单没有美元金额。我们可能需要检查下这些订单。
算出每个区域的销售代表人数。最终表格应该包含两列:区域和 sales_reps 数量。从最少到最多的代表人数排序。
SELECT r.name, COUNT(*) num_reps
FROM region r
JOIN sales_reps s
ON r.id = s.region_id
GROUP BY r.name
ORDER BY num_reps;
GROUP BY 实现多个分组
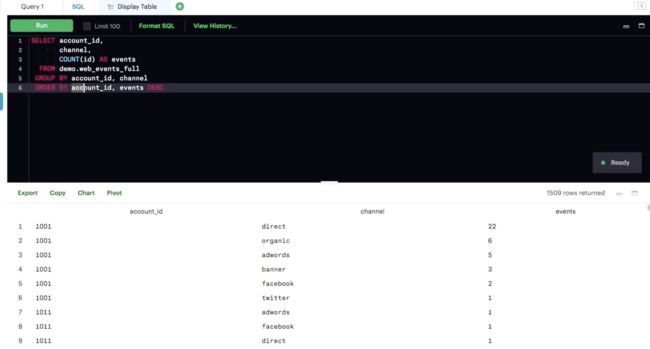
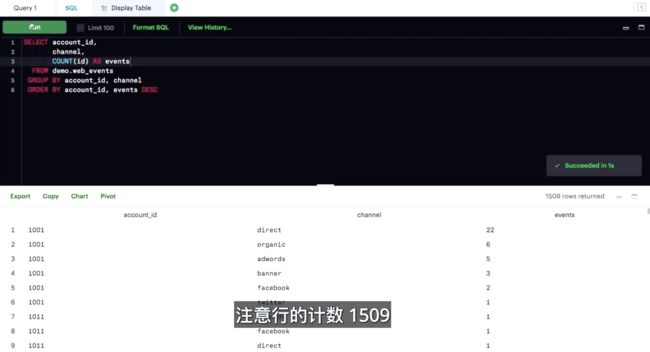
可以同时按照多列分组,正如此处所显示的那样。这样经常可以在大量不同的细分中更好地获得聚合结果。
ORDER BY 条件中列出的列顺序有区别。你是从左到右让列排序。
提示
GROUP BY 条件中的列名称顺序并不重要,结果还是一样的。如果运行相同的查询并颠倒 GROUP BY 条件中列名称的顺序,可以看到结果是一样的。
和 ORDER BY 一样,你可以在 GROUP BY 条件中用数字替换列名称。仅当你对大量的列分组时,或者其他原因导致 GROUP BY 条件中的文字过长时,才建议这么做。
提醒下,任何不在聚合函数中的列必须显示 GROUP BY 语句。如果忘记了,可能会遇到错误。但是,即使查询可行,你也可能不会喜欢最后的结果!
练习
- 对于每个客户,确定他们在订单中购买的每种纸张的平均数额。结果应该有四列:客户名称一列,每种纸张类型的平均数额一列。
SELECT a.name, AVG(o.standard_qty) avg_stand, AVG(gloss_qty) avg_gloss, AVG(poster_qty) avg_post
FROM accounts a
JOIN orders o
ON a.id = o.account_id
GROUP BY a.name;
- 对于每个客户,确定在每个订单中针对每个纸张类型的平均消费数额。结果应该有四列:客户名称一列,每种纸张类型的平均消费数额一列。
SELECT a.name, AVG(o.standard_amt_usd) avg_stand, AVG(gloss_amt_usd) avg_gloss, AVG(poster_amt_usd) avg_post
FROM accounts a
JOIN orders o
ON a.id = o.account_id
GROUP BY a.name;
- 确定在 web_events 表格中每个销售代表使用特定渠道的次数。最终表格应该有三列:销售代表的名称、渠道和发生次数。按照最高的发生次数在最上面对表格排序。
SELECT s.name, w.channel, COUNT(*) num_events
FROM accounts a
JOIN web_events w
ON a.id = w.account_id
JOIN sales_reps s
ON s.id = a.sales_rep_id
GROUP BY s.name, w.channel
ORDER BY num_events DESC;
- 确定在 web_events 表格中针对每个地区特定渠道的使用次数。最终表格应该有三列:区域名称、渠道和发生次数。按照最高的发生次数在最上面对表格排序。
SELECT r.name, w.channel, COUNT(*) num_events
FROM accounts a
JOIN web_events w
ON a.id = w.account_id
JOIN sales_reps s
ON s.id = a.sales_rep_id
JOIN region r
ON r.id = s.region_id
GROUP BY r.name, w.channel
ORDER BY num_events DESC;
DISTINCT
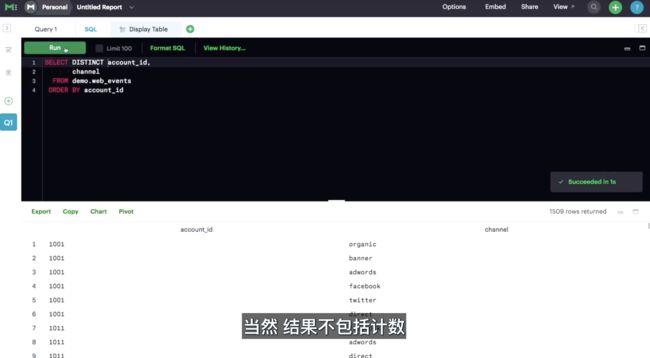
你可以将 DISTINCT 看做仅返回特定列的唯一值的函数。
提示
需要注意的是,在使用 DISTINCT 时,尤其是在聚合函数中使用时,会让查询速度有所减慢。
DISTINCT的用法的补充说明
HAVING
HAVING 是过滤被聚合的查询的 the “整洁”方式,但是通常采用子查询的方式来实现。本质上,只要你想对通过聚合创建的查询中的元素执行 WHERE 条件,就需要使用 HAVING。
HAVING总是要与一个聚合函数一起使用的,这个只有在一个或者多个列分组的时候才有用。如果你聚合的是整个数据集,那么输出只有一行,所以就没有必要进行过滤了。
练习

- 有多少位销售代表需要管理超过 5 个客户?
SELECT s.id, s.name, COUNT(*) num_accounts
FROM accounts a
JOIN sales_reps s
ON s.id = a.sales_rep_id
GROUP BY s.id, s.name
HAVING COUNT(*) > 5
ORDER BY num_accounts;
- 实际上,我们可以使用 SUBQUERY 获得这一结果,如下所示。其他查询也可以使用这一逻辑,下面就不显示了。
SELECT COUNT(*) num_reps_above5
FROM(SELECT s.id, s.name, COUNT(*) num_accounts
FROM accounts a
JOIN sales_reps s
ON s.id = a.sales_rep_id
GROUP BY s.id, s.name
HAVING COUNT(*) > 5
ORDER BY num_accounts) AS Table1;
- 有多少个客户具有超过 20 个订单?
SELECT a.id, a.name, COUNT(*) num_orders
FROM accounts a
JOIN orders o
ON a.id = o.account_id
GROUP BY a.id, a.name
HAVING COUNT(*) > 20
ORDER BY num_orders;
- 哪个客户的订单最多?
SELECT a.id, a.name, COUNT(*) num_orders
FROM accounts a
JOIN orders o
ON a.id = o.account_id
GROUP BY a.id, a.name
ORDER BY num_orders DESC
LIMIT 1;
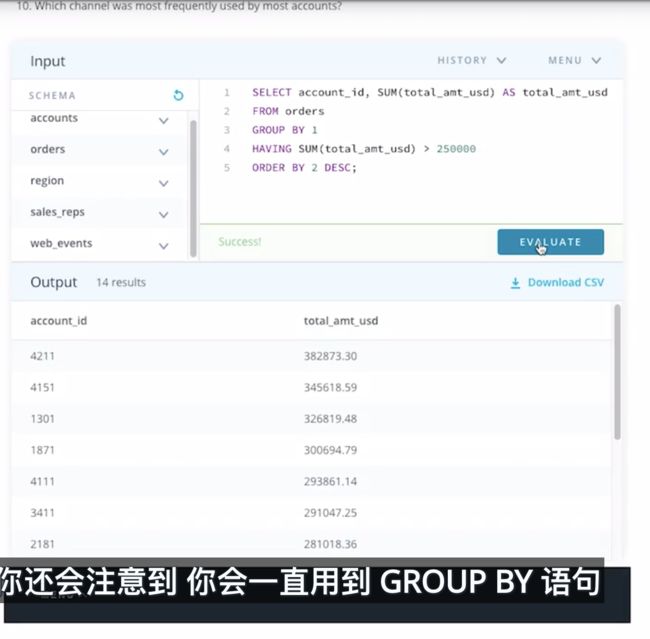
- 有多少个客户在所有订单上消费的总额超过了 30,000 美元?
SELECT a.id, a.name, SUM(o.total_amt_usd) total_spent
FROM accounts a
JOIN orders o
ON a.id = o.account_id
GROUP BY a.id, a.name
HAVING SUM(o.total_amt_usd) > 30000
ORDER BY total_spent;
- 有多少个客户在所有订单上消费的总额不到 1,000 美元?
SELECT a.id, a.name, SUM(o.total_amt_usd) total_spent
FROM accounts a
JOIN orders o
ON a.id = o.account_id
GROUP BY a.id, a.name
HAVING SUM(o.total_amt_usd) < 1000
ORDER BY total_spent;
- 哪个客户消费的最多?
SELECT a.id, a.name, SUM(o.total_amt_usd) total_spent
FROM accounts a
JOIN orders o
ON a.id = o.account_id
GROUP BY a.id, a.name
ORDER BY total_spent DESC
LIMIT 1;
- 哪个客户消费的最少?
SELECT a.id, a.name, SUM(o.total_amt_usd) total_spent
FROM accounts a
JOIN orders o
ON a.id = o.account_id
GROUP BY a.id, a.name
ORDER BY total_spent
LIMIT 1;
- 哪个客户使用 facebook 作为与消费者沟通的渠道超过 6 次?
SELECT a.id, a.name, w.channel, COUNT(*) use_of_channel
FROM accounts a
JOIN web_events w
ON a.id = w.account_id
GROUP BY a.id, a.name, w.channel
HAVING COUNT(*) > 6 AND w.channel = 'facebook'
ORDER BY use_of_channel;
- 哪个客户使用 facebook 作为沟通渠道的次数最多?
SELECT a.id, a.name, w.channel, COUNT(*) use_of_channel
FROM accounts a
JOIN web_events w
ON a.id = w.account_id
WHERE w.channel = 'facebook'
GROUP BY a.id, a.name, w.channel
ORDER BY use_of_channel DESC
LIMIT 1;
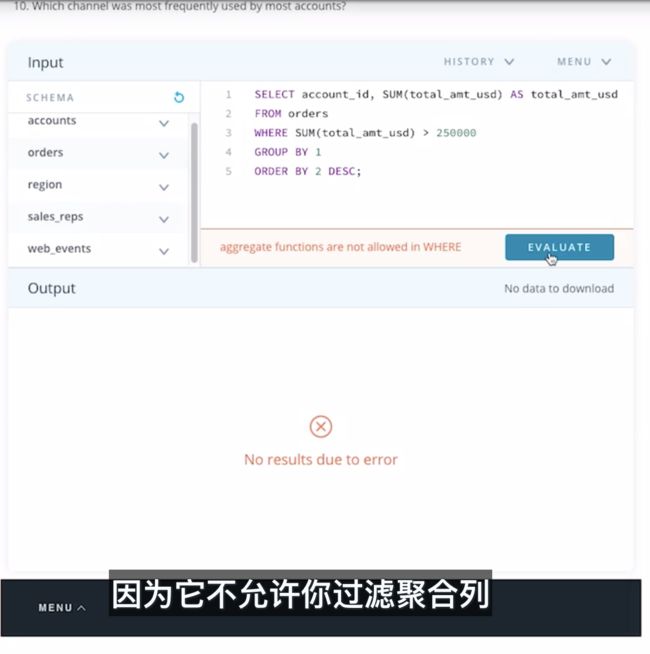
- 哪个渠道是客户最常用的渠道?
SELECT a.id, a.name, w.channel, COUNT(*) use_of_channel
FROM accounts a
JOIN web_events w
ON a.id = w.account_id
GROUP BY a.id, a.name, w.channel
ORDER BY use_of_channel DESC
LIMIT 10;
上面的所有 10 列都是 direct。
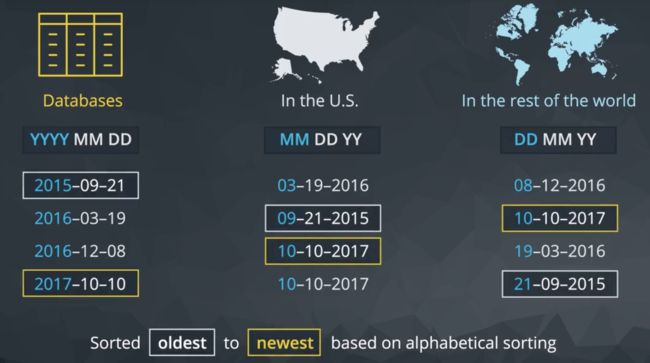
DATE
在 SQL 中,按照日期列分组通常不太实用,因为这些列可能包含小到一秒的交易数据。按照如此详细的级别保存信息即有好处,又存在不足之处,因为提供了非常准确的信息(好处),但是也让信息分组变得很难(不足之处),几乎所有订单的时间戳都是唯一的。
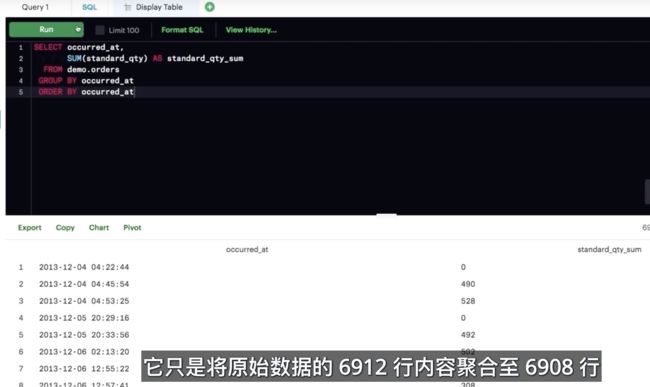
幸运的是,有很多 SQL 内置函数可以帮助我们改善日期处理体验。
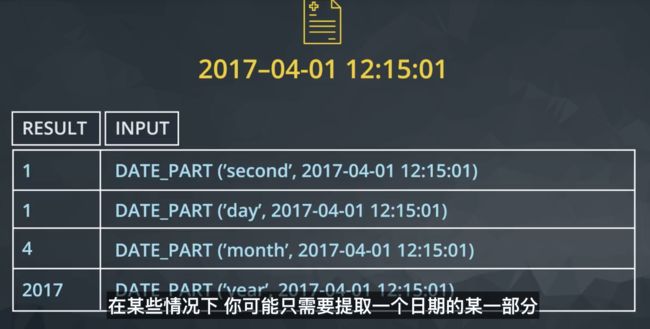
这里,我们看到日期存储为年、月、日、小时、分钟、秒,可以帮助我们截取信息。在下个部分,你将看到在 SQL 中我们可以使用大量函数来利用这一功能。
日期函数 DATE_TRUNC
DATE_TRUNC 使你能够将日期截取到日期时间列的特定部分。常见的截取依据包括日期、月份 和 年份。这是一篇 MODE 发表的精彩博文,介绍了关于此函数的强大功能。

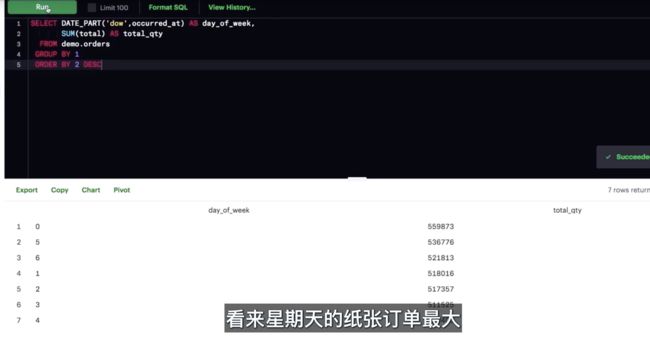
DATE_PART 可以用来获取日期的特定部分,但是注意获取 month 或 dow (day of week,会返回0~6的值,0代表周日、6代表周六)意味着无法让年份按顺序排列。而是按照特定的部分分组,无论它们属于哪个年份。
要了解其他日期函数,请参阅这篇文档,但是上面介绍的函数绝对够你入门了!

练习
处理日期
- Parch & Posey 在哪一年的总销售额最高?数据集中的所有年份保持均匀分布吗?
SELECT DATE_PART('year', occurred_at) ord_year, SUM(total_amt_usd) total_spent
FROM orders
GROUP BY 1
ORDER BY 2 DESC;
对于 2013 年和 2017 年来说,每一年只有一个月的销量(2013 年为 12,2017 年为 1)。 因此,二者都不是均匀分布。销量一年比一年高,2016 年是到目前为止最高的一年。按照这个速度,我们预计 2017 年可能是最高销量的一年。
- Parch & Posey 在哪一个月的总销售额最高?数据集中的所有月份保持均匀分布吗?
为了保持公平,我们应该删掉 2013 年和 2017 年的销量。原因如上。
SELECT DATE_PART('month', occurred_at) ord_month, SUM(total_amt_usd) total_spent
FROM orders
WHERE occurred_at BETWEEN '2014-01-01' AND '2017-01-01'
GROUP BY 1
ORDER BY 2 DESC;
12 月的销量最高。
Parch & Posey 在哪一年的总订单量最多?数据集中的所有年份保持均匀分布吗?
SELECT DATE_PART('year', occurred_at) ord_year, COUNT(*) total_sales
FROM orders
GROUP BY 1
ORDER BY 2 DESC;
同样,到目前为止,2016 年的订单量最多,但是与数据集中的其他年份相比,2013 年和 2017 年的分布不均匀。
- Parch & Posey 在哪一个月的总订单量最多?数据集中的所有年份保持均匀分布吗?
SELECT DATE_PART('month', occurred_at) ord_month, COUNT(*) total_sales
FROM orders
WHERE occurred_at BETWEEN '2014-01-01' AND '2017-01-01'
GROUP BY 1
ORDER BY 2 DESC;
12 月依然是销量最多的月份,但是有趣的是,11 月是销量第二多的月份。为了保持公平,删掉了 2017 年和 2013 年的数据。
- Walmart 在哪一年的哪一个月在铜版纸上的消费最多?
SELECT DATE_TRUNC('month', o.occurred_at) ord_date, SUM(o.gloss_amt_usd) tot_spent
FROM orders o
JOIN accounts a
ON a.id = o.account_id
WHERE a.name = 'Walmart'
GROUP BY 1
ORDER BY 2 DESC
LIMIT 1;
在 2016 年 5 月,Walmart 在铜版纸上的消费做多。
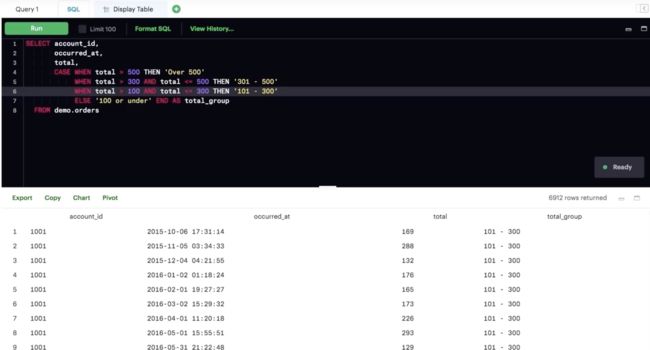
CASE
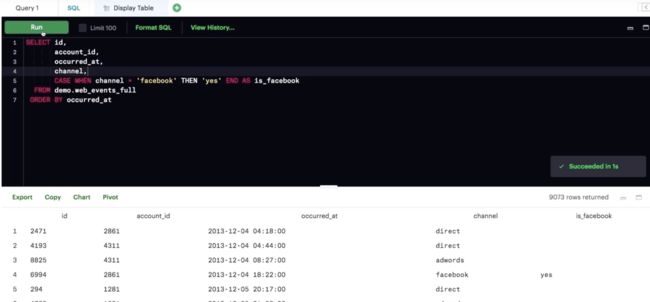

WHEN其实就相当于你想在WHERE语句中加入逻辑条件。

提示
CASE 语句始终位于 SELECT 条件中。
CASE 必须包含以下几个部分:WHEN、THEN 和 END。ELSE 是可选组成部分,用来包含不符合上述任一 CASE 条件的情况。
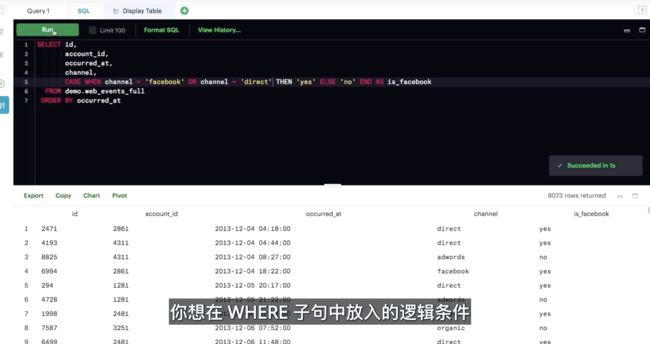
你可以在 WHEN 和 THEN 之间使用任何条件运算符编写任何条件语句(例如 WHERE),包括使用 AND 和 OR 连接多个条件语句。
你可以再次包含多个 WHEN 语句以及 ELSE 语句,以便处理任何未处理的条件。
示例
在第一节课的练习中,你看到了以下问题:
- 创建一列用于将
standard_amt_usd除以standard_qty,以便计算每个订单的标准纸张的单价,将结果限制到前 10 个订单,并包含id和account_id字段。注意 - 如果你的答案正确,系统将显示一个错误,这是因为你除以了 0。当你在下个部分学习 CASE 语句时,你将了解如何让此查询不会报错。
我们来看看如何使用 CASE 语句来避免这一错误。
SELECT id, account_id, standard_amt_usd/standard_qty AS unit_price
FROM orders
LIMIT 10;
现在我们使用一个 CASE 语句,这样的话,一旦 standard_qty 为 0,我们将返回 0,否则返回 unit_price。
SELECT account_id, CASE WHEN standard_qty = 0 OR standard_qty IS NULL THEN 0
ELSE standard_amt_usd/standard_qty END AS unit_price
FROM orders
LIMIT 10;
该语句的第一部分将捕获任何分母为 0 并导致错误的情况,其他部分将按照常规步骤相除。你将发现对于标准纸张,所有客户的单价是 4.99 美元。这样比较合理,不会波动,并且比在上节课中向分母上加 1 来暂时解决错误这一方法更准确。
你可以使用下面的数据自己尝试下。
CASE与聚合
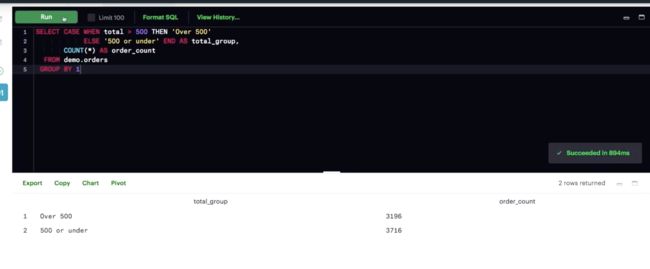
练习
CASE
- 我们想要根据相关的购买量了解三组不同的客户。最高的一组是终身价值(所有订单的总销售额)大于 200,000 美元的客户。第二组是在 200,000 到 100,000 美元之间的客户。最低的一组是低于 under 100,000 美元的客户。请提供一个表格,其中包含与每个客户相关的级别。你应该提供客户的名称、所有订单的总销售额和级别。消费最高的客户列在最上面。
SELECT a.name, SUM(total_amt_usd) total_spent,
CASE WHEN SUM(total_amt_usd) > 200000 THEN 'top'
WHEN SUM(total_amt_usd) > 100000 THEN 'middle'
ELSE 'low' END AS customer_level
FROM orders o
JOIN accounts a
ON o.account_id = a.id
GROUP BY a.name
ORDER BY 2 DESC;
- 现在我们想要执行和第一个问题相似的计算过程,但是我们想要获取在 2016 年和 2017 年客户的总消费数额。级别和上一个问题保持一样。消费最高的客户列在最上面。
SELECT a.name, SUM(total_amt_usd) total_spent,
CASE WHEN SUM(total_amt_usd) > 200000 THEN 'top'
WHEN SUM(total_amt_usd) > 100000 THEN 'middle'
ELSE 'low' END AS customer_level
FROM orders o
JOIN accounts a
ON o.account_id = a.id
WHERE occurred_at > '2015-12-31'
GROUP BY 1
ORDER BY 2 DESC;
- 我们想要找出绩效最高的销售代表,也就是有超过 200 个订单的销售代表。创建一个包含以下列的表格:销售代表名称、订单总量和标为 top 或 not 的列(取决于是否拥有超过 200 个订单)。销售量最高的销售代表列在最上面。
SELECT s.name, COUNT(*) num_ords,
CASE WHEN COUNT(*) > 200 THEN 'top'
ELSE 'not' END AS sales_rep_level
FROM orders o
JOIN accounts a
ON o.account_id = a.id
JOIN sales_reps s
ON s.id = a.sales_rep_id
GROUP BY s.name
ORDER BY 2 DESC;
值得注意的是,上述语句假定每个名称是唯一的,好几次都是这么假定的。否则需要根据名称和 ID 拆分表格。
- 之前的问题没有考虑中间水平的销售代表或销售额。管理层决定也要看看这些数据。我们想要找出绩效很高的销售代表,也就是有超过 200 个订单或总销售额超过 750000 美元的销售代表。中间级别是指有超过 150 个订单或销售额超过 500000 美元的销售代表。创建一个包含以下列的表格:销售代表名称、总订单量、所有订单的总销售额,以及标为 top、middle 或 low 的列(取决于上述条件)。在最终表格中将销售额最高的销售代表列在最上面。
SELECT s.name, COUNT(*), SUM(o.total_amt_usd) total_spent,
CASE WHEN COUNT(*) > 200 OR SUM(o.total_amt_usd) > 750000 THEN 'top'
WHEN COUNT(*) > 150 OR SUM(o.total_amt_usd) > 500000 THEN 'middle'
ELSE 'low' END AS sales_rep_level
FROM orders o
JOIN accounts a
ON o.account_id = a.id
JOIN sales_reps s
ON s.id = a.sales_rep_id
GROUP BY s.name
ORDER BY 3 DESC;