人工智能数学基础之概率论
概率论
基础概率
随机试验
试验是指为了观察某事的结果或某物的性能而从事的某种活动。在概率论中,一个试验如果具有以下3个特点:
- 可重复性:在相同条件下可以重复进行
- 可观察性:每次实现的可能结果不止一个,并且能事先明确实验的所有可能结果
- 不确定性:一次试验之前,不能预知会出现哪一个结果
这样的试验是一个随机试验,简称为试验
样本点和样本空间
每次试验的每一个结果成为基本事件,也称作样本点,记作 w 1 , w 2 , ⋯ w_1,w_2,\cdots w1,w2,⋯, 全部样本点的集合成为样本空间,记作 Ω \Omega Ω,则 Ω = { w 1 , w 2 , ⋯ } \Omega=\{w_1,w_2,\cdots\} Ω={w1,w2,⋯}
假设掷一颗均匀骰子,观察出现的点数。这是一个随机试验,样本空间 Ω = { 1 , 2 , 3 , 4 , 5 , 6 } \Omega=\{1,2,3,4,5,6\} Ω={1,2,3,4,5,6}
随机事件
基本事件是不可再分解的、最基本的事件,其他事件均可由它们复合而成,由基本事件复合而成的事件称为随机事件或简称为事件。
常用大写字母 A , B , C A,B,C A,B,C等表示事件。不如 A = { 出 现 的 点 数 为 偶 数 } = { 2 , 4 , 6 } A=\{出现的点数为偶数\}=\{2,4,6\} A={出现的点数为偶数}={2,4,6}
随机事件的概率
概率是用来描述随机事件发生的可能性大小。比如抛硬币的试验,抛得次数越多,出现正面的 次数与投掷次数之间的比例愈加趋于 0.5 0.5 0.5。它的数学定义为:
在多次重复试验中,若事件 A A A发生的频率稳定在常数 p p p附近摆动,且随着试验次数的增加,这种摆动的幅度是很微小的。则称确定常数 p p p为事件 A A A发生的概率,记作 P ( A ) = p P(A)=p P(A)=p
例子
设一年有365天,求下列事件 A , B A,B A,B的概率:
A = { n 个 人 中 没 有 2 人 同 一 天 生 日 } B = { n 个 人 中 有 2 人 同 一 天 生 日 } A = \{n个人中没有2人同一天生日\} B = \{n个人中有2人同一天生日\} A={n个人中没有2人同一天生日}B={n个人中有2人同一天生日}
解
显然事件 A , B A,B A,B是对立事件,有 P ( B ) = 1 − P ( A ) P(B)=1 - P(A) P(B)=1−P(A)
由于每人的生日可能是365天的任意一天,因此, n n n个人的生日有 36 5 n 365^n 365n种可能结果,而且每种结果是等可能的,因而是古典概型,事件 A A A的发生必须是 n n n个不同的生日,因而 A A A的样本点数为从 365 365 365中取 n n n个的排列数 P 365 n P^n_{365} P365n,于是
P ( A ) = P 365 n 36 5 n P ( B ) = 1 − P ( A ) = 1 − P 365 n 36 5 n P(A) = \frac{P^n_{365}}{365^n} \\ P(B) = 1 - P(A) = 1 - \frac{P^n_{365}}{365^n} P(A)=365nP365nP(B)=1−P(A)=1−365nP365n
条件概率
设 A , B A,B A,B是两个事件,且 P ( A ) > 0 P(A)>0 P(A)>0,则称
P ( B ∣ A ) = P ( A B ) P ( A ) P(B|A) = \frac{P(AB)}{P(A)} P(B∣A)=P(A)P(AB)
为在事件 A A A发生的条件下,事件 B B B的条件概率
P ( A B ) P(AB) P(AB)表示 A , B A,B A,B这两个事件同时发生的概率。
例子
某种原件用满 6000 h 6000h 6000h未坏的概率是 3 / 4 3/4 3/4,用满 10000 h 10000h 10000h未坏的概率是 1 / 2 1/2 1/2,现有一个此种元件,已经用过 6000 h 6000h 6000h未坏,试求它能用到 10000 h 10000h 10000h的概率。
解
设 A A A表示 { 满 10000 h 未 坏 } \{满10000h未坏\} {满10000h未坏}, B B B表示 { 满 6000 小 时 未 坏 } \{满6000小时未坏\} {满6000小时未坏},则
P ( B ) = 3 / 4 , P ( A ) = 1 / 2 P(B)=3/4,P(A)=1/2 P(B)=3/4,P(A)=1/2
由于 B ⊃ A , A B = A B \supset A,AB=A B⊃A,AB=A,因而 P ( A B ) = 1 / 2 P(AB)=1/2 P(AB)=1/2,因此,
P ( A ∣ B ) = P ( A B ) P ( B ) = 1 2 3 4 = 2 3 P(A|B)=\frac{P(AB)}{P(B)} = \frac{\frac{1}{2}}{\frac{3}{4}}=\frac{2}{3} P(A∣B)=P(B)P(AB)=4321=32
解释一下,这里由于事件 A A A包括事件 B B B的。
事件的独立性
如果事件 B B B发生的可能性不受事件 A A A发生与否的影响,即
P ( B ∣ A ) = P ( B ) P(B|A)=P(B) P(B∣A)=P(B)
则称事件 B B B对于事件 A A A独立,显然,若 B B B对 A A A对立,则 A A A对 B B B也一定独立,称事件 A A A与事件 B B B相互独立。
例子
口袋里装有5个黑球与3个白球,从中有放回地取2次,每次取一个,设事件 A A A表示第一次取到黑球,事件 B B B表示第二次取到黑球,则有
P ( A ) = 5 8 , P ( B ) = 5 8 , P ( A B ) = 5 8 × 5 8 = 25 64 P(A)=\frac{5}{8},P(B)=\frac{5}{8},P(AB)=\frac{5}{8} \times \frac{5}{8} = \frac{25}{64} P(A)=85,P(B)=85,P(AB)=85×85=6425
因而
P ( B ∣ A ) = P ( A B ) P ( A ) = 5 8 P(B|A) = \frac{P(AB)}{P(A)} = \frac{5}{8} P(B∣A)=P(A)P(AB)=85
因此, P ( B ∣ A ) = P ( B ) P(B|A) = P(B) P(B∣A)=P(B),这表明无论 A A A是否发生,都对 B B B发生的概率无影响。事件 A , B A,B A,B相互独立
性质
事件 A A A和事件 B B B相互独立的充分必要条件是
P ( A B ) = P ( A ) P ( B ) P(AB)=P(A)P(B) P(AB)=P(A)P(B)
全概率公式
如果事件 A 1 , A 2 , ⋯ , A n A_1,A_2,\cdots,A_n A1,A2,⋯,An是一个完备事件组(一个事件发生的所有可能性都在这里面),并且都有正概率,则有
P ( B ) = P ( A 1 ) P ( B ∣ A 1 ) + P ( A 2 ) P ( B ∣ A 2 ) + ⋯ + P ( A n ) P ( B ∣ A n ) = ∑ i = 1 n P ( A i ) P ( B ∣ A i ) P(B)=P(A_1)P(B|A_1)+P(A_2)P(B|A_2)+\cdots+P(A_n)P(B|A_n) = \sum_{i=1}^nP(A_i)P(B|A_i) P(B)=P(A1)P(B∣A1)+P(A2)P(B∣A2)+⋯+P(An)P(B∣An)=i=1∑nP(Ai)P(B∣Ai)
对于任何事件 B B B,事件 A A ‾ A\overline{A} AA构成最简单的完备事件组,根据全概率公式得
P ( B ) = P ( A B + A ‾ B ) = P ( A B ) + P ( A ‾ B ) = P ( A ) P ( B ∣ A ) + P ( A ‾ ) P ( B ∣ A ‾ ) P(B)=P(AB+\overline{A}B)=P(AB)+P(\overline{A}B)=P(A)P(B|A)+P(\overline{A})P(B|\overline{A}) P(B)=P(AB+AB)=P(AB)+P(AB)=P(A)P(B∣A)+P(A)P(B∣A)
贝叶斯公式
设事件 A 1 , A 2 , ⋯ , A n A_1,A_2,\cdots,A_n A1,A2,⋯,An是一个完备事件组,则对任一事件 B B B, P ( B ) > 0 P(B)>0 P(B)>0,有
P ( A i ∣ B ) = P ( A i B ) P ( B ) = P ( A i ) P ( B ∣ A i ) ∑ i = 1 n P ( A i ) P ( B ∣ A i ) P(A_i|B)=\frac{P(A_iB)}{P(B)}=\frac{P(A_i)P(B|A_i)}{\sum^n_{i=1}P(A_i)P(B|A_i)} P(Ai∣B)=P(B)P(AiB)=∑i=1nP(Ai)P(B∣Ai)P(Ai)P(B∣Ai)
以上公式就叫贝叶斯公式,可由条件概率的定义及全概率公式证明。
例子
市场上供应的某种商品由甲、乙、丙3个厂商生存,甲厂占45%,乙厂占35%,丙厂占20%。如果各厂的次品率依次为4%,2%,5%。现从市场上购买1件这种商品,发现是次品,试判断它是由甲厂生产的概率。
解
设事件 A 1 , A 2 , A 3 A_1,A_2,A_3 A1,A2,A3,分别表示商品由甲、乙、丙厂生产的,事件 B B B表示商品为次品,得概率
P ( A 1 ) = 0.45 , P ( A 2 ) = 0.35 , P ( A 3 ) = 0.20 P ( B ∣ A 1 ) = 0.04 , P ( B ∣ A 2 ) = 0.02 , P ( B ∣ A 3 ) = 0.05 P(A_1)=0.45,P(A_2)=0.35,P(A_3)=0.20 \\ P(B|A_1) = 0.04,P(B|A_2)=0.02,P(B|A_3)=0.05 P(A1)=0.45,P(A2)=0.35,P(A3)=0.20P(B∣A1)=0.04,P(B∣A2)=0.02,P(B∣A3)=0.05
根据贝叶斯公式,可得:
P ( A 1 ∣ B ) = P ( A 1 B ) P ( B ) = P ( A 1 ) P ( B ∣ A 1 ) P ( A 1 ) P ( B ∣ A 1 ) + P ( A 2 ) P ( B ∣ A 2 ) + P ( A 3 ) P ( B ∣ A 3 ) = 0.45 × 0.04 0.45 × 0.04 + 0.35 × 0.02 + 0.2 × 0.05 ≈ 0.514 P(A_1|B)=\frac{P(A_1B)}{P(B)} = \frac{P(A_1)P(B|A_1)}{P(A_1)P(B|A_1)+P(A_2)P(B|A_2) + P(A_3)P(B|A_3)} \\ = \frac{0.45\times 0.04}{0.45 \times 0.04 + 0.35\times 0.02 + 0.2 \times 0.05} \approx 0.514 P(A1∣B)=P(B)P(A1B)=P(A1)P(B∣A1)+P(A2)P(B∣A2)+P(A3)P(B∣A3)P(A1)P(B∣A1)=0.45×0.04+0.35×0.02+0.2×0.050.45×0.04≈0.514
在购买一件商品这个试验中, P ( A i ) P(A_i) P(Ai)是在试验以前就已经知道的概率,所以习惯地称为先验概率。试验结果出现了次品,这时条件概率 P ( A i ∣ B ) P(A_i|B) P(Ai∣B)反映了在试验以后对 B B B发生的来源(次品的来源)的各种可能性的大小,称为后验概率。
随机变量
把试验的结果与实数对应起来,随试验结果的不同而变化的量就是随机变量,包含离散型随机变量和连续性随机变量。
概率分布
设离散型随机变量 X X X的所有可能取值为 x 1 , x 2 , ⋯ , x n x_1,x_2,\cdots,x_n x1,x2,⋯,xn,称
P { X = x k } = p k ( k = 1 , 2 , ⋯ ) P\{X=x_k\} = p_k (k=1,2,\cdots) P{X=xk}=pk(k=1,2,⋯)
为 X X X的概率分布。
离散型随机变量 X X X的分布律具有下列基本性质:
1. p k ≥ 0 , K = 1 , 2 , ⋯ ; p_k \geq 0,K=1,2,\cdots; pk≥0,K=1,2,⋯;
2. ∑ i = 1 + ∞ p k = 1 \sum_{i=1}^{+\infty}p_k=1 ∑i=1+∞pk=1
下面看一下常见的离散型概率分布。
二项分布
二项分布是一种离散型的概率分布。二项代表它有两种可能的结果:成功或不成功。每次试验必须相互独立,重复n次,并且每次试验成功的概率是相同的,为 p p p:失败的概率也相同,为 1 − p 1-p 1−p
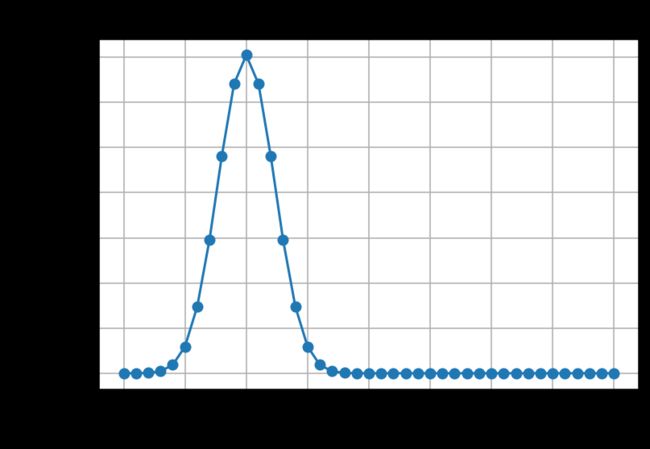
抛硬币就是一个典型的二项分布。当我们要计算抛硬币 n n n次,恰好有 x x x次正面朝上的概率,可以使用二项分布的公式:
P { X = k } = C n k p k ( 1 − p ) n − k P\{X=k\}=C_n^kp^k(1-p)^{n-k} P{X=k}=Cnkpk(1−p)n−k
泊松分布
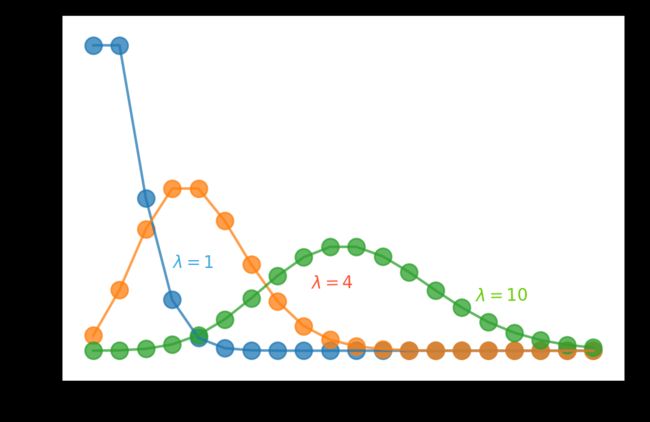
如果随机变量 X X X的概率分布为
P { X = k } = λ k k ! e − λ , k = 0 , 1 , 2 , ⋯ P\{X=k\} = \frac{\lambda ^k}{k!} e^{-\lambda},k=0,1,2,\cdots P{X=k}=k!λke−λ,k=0,1,2,⋯
式中, λ > 0 \lambda>0 λ>0为常数,则称随机变量 X X X服从参数为 λ \lambda λ的泊松分布,记为 X ∼ P ( λ ) X\sim P(\lambda) X∼P(λ)
概率密度函数
若存在非负函数 f ( x ) f(x) f(x),使一个连续型随机变量 X X X取值于任一区间 ( a , b ] (a,b] (a,b]的概率可以表示为
P { a < X ≤ b } = ∫ a b f ( x ) d x P\{a
则称 f ( x ) f(x) f(x)为随机变量 X X X的概率密度函数,简称概率密度或密度函数。
正态分布
又常称为高斯分布,其概率密度函数为
f ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 f(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}} f(x)=2πσ1e−2σ2(x−μ)2
具有两个参数 μ \mu μ和 σ 2 \sigma^2 σ2, μ \mu μ代表服从正态分布的随机变量的均值, σ 2 \sigma^2 σ2是此随机变量的方差。如果一个随机变量服从均值 μ \mu μ,标准差为 σ \sigma σ的正太分布,记作
X ∼ N ( μ , σ 2 ) X\sim N(\mu,\sigma^2) X∼N(μ,σ2)
我们通常称均值为 0 0 0,标准差为 1 1 1的正态分布为标准正态分布。
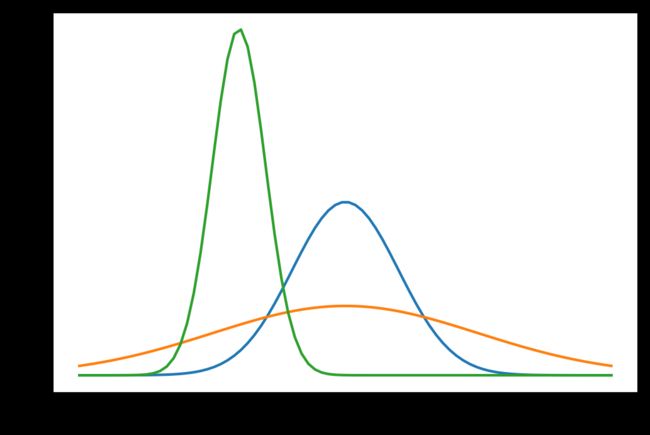
上图中蓝线就是标准正态分布
随机变量的期望
对于一个随机变量,经常要考虑它平均取什么,期望就是概率论中的平均值,对随机变量中心位置的一种度量。
例子
经过长期观察积累,某射手在每次射击命中的环数 X X X服从分布:
| X X X | 0 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|
| P i P_i Pi | 0 | 0.05 | 0.05 | 0.1 | 0.1 | 0.2 | 0.5 |
求这个射手平均命中的环数是多少?
解
假设该射手进行了100次射击,那么,约有5次命中5环,5次命中6环,10次命中7环,10次命中8环,20次命中9环,50次命中10环,从而在一次射击中,该射手平均命中的环数为:
1 100 ( 10 × 50 + 9 × 20 + 8 × 10 + 7 × 10 + 6 × 5 + 5 × 5 + 0 × 0 ) = 8.85 \frac{1}{100}(10\times 50 + 9 \times 20 + 8\times 10 + 7 \times10 +6 \times 5 + 5 \times 5 + 0 \times 0) = 8.85 1001(10×50+9×20+8×10+7×10+6×5+5×5+0×0)=8.85
我们可以看到离散型的随机变量的期望值可以用每种取值于概率相乘之和来得到:
E ( X ) = ∑ i = 1 + ∞ x i p k E(X)= \sum_{i=1}^{+\infty}x_ip_k E(X)=i=1∑+∞xipk
期望的性质
- E ( c ) = c E(c) = c E(c)=c
- E ( X + c ) = E ( X ) + c E(X+c) = E(X) +c E(X+c)=E(X)+c
- E ( k X ) = k E ( X ) E(kX) = kE(X) E(kX)=kE(X)
- E ( k X + c ) = k E ( X ) + c E(kX+c)=kE(X)+c E(kX+c)=kE(X)+c
- E ( X + Y ) = E ( X ) + E ( Y ) E(X+Y)=E(X)+E(Y) E(X+Y)=E(X)+E(Y)
随机变量的方差
方差表示随机变量的变异性,方差越大,随机变量的结果越不稳定。
设 X X X为一随机变量,若
E [ X − E ( X ) ] 2 E[X-E(X)]^2 E[X−E(X)]2
存在,则称其为 X X X的方差,记为 D ( X ) D(X) D(X),即
D ( X ) = E [ X − E ( X ) ] 2 D(X) = E[X-E(X)]^2 D(X)=E[X−E(X)]2
而称 D ( X ) \sqrt{D(X)} D(X)为 X X X的标准差或均方差
由方差的定义和数学期望的性质,可以推出方差的计算公式:
D ( X ) = E ( X 2 ) − [ E ( X ) ] 2 D(X)=E(X^2) - [E(X)]^2 D(X)=E(X2)−[E(X)]2
方差的性质
- D ( c ) = 0 D(c)=0 D(c)=0
- D ( X + c ) = D ( X ) D(X+c) = D(X) D(X+c)=D(X)
- D ( c X ) = c 2 D ( X ) D(cX) = c^2D(X) D(cX)=c2D(X)
例子
甲、乙两车间生产同一种产品,设1000件产品中的次品数量分别为随机变量 X , Y X,Y X,Y,已知他们的分布律如下:
| X X X | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| P i P_i Pi | 0.2 | 0.1 | 0.5 | 0.2 |
| Y Y Y | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| P i P_i Pi | 0.1 | 0.3 | 0.4 | 0.2 |
式讨论甲、乙两车间的产品质量。
解
先计算均值
E ( X ) = 0 × 0.2 + 1 × 0.1 + 2 × 0.5 + 3 × 0.2 = 1.7 E ( Y ) = 0 × 0.1 + 1 × 0.3 + 2 × 0.4 + 3 × 0.2 = 1.7 E(X)=0\times 0.2 + 1 \times 0.1 + 2 \times 0.5 + 3 \times 0.2 = 1.7 \\ E(Y)=0\times 0.1 + 1 \times 0.3 + 2 \times 0.4 + 3 \times 0.2 = 1.7 E(X)=0×0.2+1×0.1+2×0.5+3×0.2=1.7E(Y)=0×0.1+1×0.3+2×0.4+3×0.2=1.7
得到,甲、乙两车间次品数的均值相同。
再计算方差
D ( X ) = ( 0 − 1.7 ) 2 × 0.2 + ( 1 − 1.7 ) 2 × 0.1 + ( 2 − 1.7 ) 2 × 0.1 + ( 2 − 1.7 ) 2 × 0.5 + ( 3 − 1.7 ) 2 × 0.2 = 1.01 D ( Y ) = ( 0 − 1.7 ) 2 × 0.1 + ( 1 − 1.7 ) 2 × 0.3 + ( 2 − 1.7 ) 2 × 0.4 + ( 2 − 1.7 ) 2 × 0.4 + ( 3 − 1.7 ) 2 × 0.2 = 0.81 D(X)=(0-1.7)^2 \times 0.2 +(1-1.7)^2 \times 0.1 + (2-1.7)^2 \times 0.1 + (2-1.7)^2 \times 0.5 + (3-1.7)^2 \times 0.2 = 1.01\\ D(Y)=(0-1.7)^2 \times 0.1 +(1-1.7)^2 \times 0.3 + (2-1.7)^2 \times 0.4 + (2-1.7)^2 \times 0.4 + (3-1.7)^2 \times 0.2 = 0.81 D(X)=(0−1.7)2×0.2+(1−1.7)2×0.1+(2−1.7)2×0.1+(2−1.7)2×0.5+(3−1.7)2×0.2=1.01D(Y)=(0−1.7)2×0.1+(1−1.7)2×0.3+(2−1.7)2×0.4+(2−1.7)2×0.4+(3−1.7)2×0.2=0.81
以上用到了公式 E ( X ) = ∑ i = 1 + ∞ x i p k E(X)= \sum_{i=1}^{+\infty}x_ip_k E(X)=∑i=1+∞xipk和 D ( X ) = E [ X − E ( X ) ] 2 D(X) = E[X-E(X)]^2 D(X)=E[X−E(X)]2
说明乙车间的产品质量比较稳定。
最大似然估计
概率vs统计
概率研究的问题是,已知一个模型和参数,怎么去预测这个模型产生的结果的特性(均值,方差等)。统计研究的问题则相反,它是有一堆数据,要利用这堆数据去预测模型和参数。简单来说,概率是已知模型和参数,推数据。统计是已知数据,推模型和参数。
最大似然估计
最大似然估计是一种用来推测参数的方法,属于统计领域的问题。
它利用已知的样本结果信息,反推使这个结果出现可能性最大的模型参数值,是一种概率意义下的参数估计。
例子
假设有一种特殊的硬币,抛这种硬币出现的正反面并不相等,求它正面出现的概率( θ \theta θ)是多少?
解
这是一个统计问题,解决统计问题需要数据。于是我们拿这枚硬币抛了10次,得到的数据 x 0 x_0 x0是:反正正正正反正正正反。我们相求的正面概率 θ \theta θ是模型参数,而抛硬币模型我们可以假设是二项分布。那么出现实验结果 x 0 x_0 x0的似然函数是多少呢?
f ( x 0 , θ ) = ( 1 − θ ) × θ × θ × θ × θ × ( 1 − θ ) × θ × θ × θ × ( 1 − θ ) = θ 7 ( 1 − θ ) 3 = f ( θ ) f(x_0,\theta)=(1-\theta)\times \theta \times \theta \times \theta \times \theta \times (1 - \theta ) \times \theta \times \theta \times \theta \times (1 - \theta ) = \theta^7(1-\theta)^3 = f(\theta) f(x0,θ)=(1−θ)×θ×θ×θ×θ×(1−θ)×θ×θ×θ×(1−θ)=θ7(1−θ)3=f(θ)
所谓最大似然估计,就是最大化这个关于 θ \theta θ的函数,于是,我们画出 f ( θ ) f(\theta) f(θ)的图像:
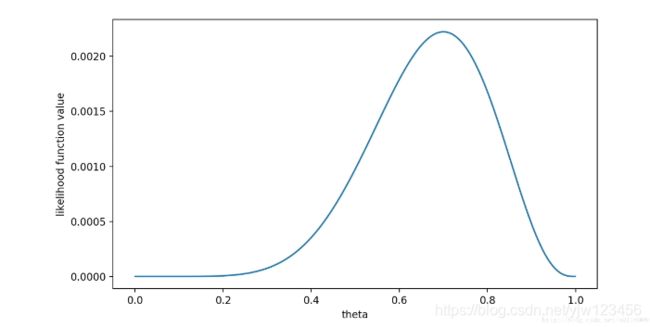
可以看出,在 θ = 0.7 \theta=0.7 θ=0.7时, f ( θ ) f(\theta) f(θ)取得最大值。
这样,我们已经完成了对 θ \theta θ的最大似然估计。即,抛10次硬币,发现7次硬币正面朝上,最大似然估计认为正面朝上的概率是0.7。
参考
- 微专业人工智能机器学习数学高等数学概率论统计学基础进阶课程(完整版)