python爬虫之MongoDB——MongoDB的基本使用
MongoDB的基本使用
- 1 数据库命名规范
- 2 MongoDB的增删改查
- 2.1 MongoDB插入数据
- 2.2 MongoDB的保存
- 2.3 MongoDB查询数据
- 2.4 MongoDB修改数据
- 2.5 MongDB删除数据
- 3 MongoDB聚合
- 3.1 常用的管道
- 3.2 表达式
- 3.2.1 $group
- 3.2.2 $match
- 4 MongDB索引操作
1 数据库命名规范
1.不能是空字符串
2.不得含有特殊字符
3.应全部小写
4.最多64个字节
5.数据库名不能与现有系统保留库同名,如admin,local
2 MongoDB的增删改查
mongoDB中一张表称为一个集合
use student # 转到student数据库
2.1 MongoDB插入数据
db.集合名.insert({}) 数据格式为json,id不能重复,支持多条插入数据库
单条插入数据db.juran_collection.insert({x:1})
多条插入数据for(i=3;i<10;i++)db.juran_collection.insert({x:i})
2.2 MongoDB的保存
命令:db.集合名称.save(document)
db.juran_collection.save({_id:ObjectId("5f169b37d74866264ed9a7db"), name:'gj', gender:2})
db.juran_collection.save({name:'gj', gender:2})
db.juran_collection.find()

2.3 MongoDB查询数据
测试数据如下(输入系统)
db.stu.insert([{"name" : "张三", "hometown" : "长沙", "age" : 20, "gender" : true }, {"name" : "老李", "hometown" : "广州", "age" : 18, "gender" : false }, {"name" : "王麻子", "hometown" : "北京", "age" : 18, "gender" : false }, {"name" : "刘六", "hometown" : "深圳", "age" : 40, "gender" : true }, {"name" : "居然", "hometown" : "哈尔滨", "age" : 16, "gender" : true }, {"name" : "小永", "hometown" : "广州", "age" : 45, "gender" : true },{"name" : "老amy", "hometown" : "衡阳", "age" : 18, "gender" : true }])
(1)查询所有数据
db.stu.find({条件⽂档})
(2)方法pretty():将结果格式化
db.集合名称.find({条件⽂档}).pretty()
(3)查询单条数据
db.stu.findOne({条件⽂档})
(4)带有条件的查询
查询x等于100的数据
db.stu.find({x:100})
查询x等于100,y等于99的
db.stu.find({x:100,y:99})
(5) 比较运算符
等于:默认是等于判断,没有运算符
小于:$lt
小于等于:$lte
大于:$gt
大于等于:$gte
查询y大于等于18的数据
db.stu.find({y:{$gte:18}})
(6) 范围运算符
使用$in,$nin判断是否在某个范围内查询年龄为18、28的学生
db.stu.find({age:{$in:[18,28]}})
(7) 逻辑运算符
or:使用$or,值为数组,数组中每个元素为json
db.juran_collection.find({$or:[{age:{$gt:18}},{gender:false}]})
(8) 自定义查询
mongo shell 是一个js的执行环境
使用$where 写一个函数, 返回满足条件的数据
查询年龄大于30的学生
db.stu.find({
$where:function() {
return this.age>30;}
})
(9) 查询结果操作
查出的数据求总数 db.juran_collection.find().count()
limit和skip
limit用于读取指定数量的文档
db.juran_collection.find().limit(2)
skip用于跳过指定数量的文档
db.juran_collection.find().skip(2)
limit和skip同时使用
db.juran_collection.find().skip(2).limit(2)
映射:指定返回的字段,如果为1则返回改字段,如果为0则除了改字段外所有字段返回。id如果没写会默认返回
db.stu.find({},{_id:1})
排序
按照年龄升序排序
db.stu().find().sort({age:1})
按照年龄降序排序
db.stu().find().sort({age:-1})
2.4 MongoDB修改数据
命令
db.集合名称.update({query}, {update}, {multi: boolean})
参数query:查询条件
参数update:更新操作符
参数multi:可选,默认是false,表示只更新找到的第一条数据,值为true表示把满足条件的数据全部更新
db.stu.insert({x:100,y:100,z:100})
{ "_id" : ObjectId("59b297dd8fa0c171faae5bc8"), "x" : 100, "y" : 100, "z" : 100 }
db.stu.update({x:100},{y:99})
修改后数据变为
{ "_id" : ObjectId("59b297dd8fa0c171faae5bc8"), "y" : 99 }
部分更新
db.stu.update({x:100},{$set:{y:99}})
如果y:100数据不存在,就插入y:101这条数据,第三个参数为true
db.stu.update({y:100},{y:101},true)
更新多条
db.stu.update({y:99},{$set:{y:101}},{multi:true})
2.5 MongDB删除数据
删除集合数据
db.stu.remove({条件},{justOne:true}) mongoDB为了防止误删除,条件必须写
db.stu.remove() 删除所有数据,索引不会删除
db.stu.remove({x:100})
删除表数据
db.stu.drop() # 删除stu表
3 MongoDB聚合
聚合是基于数据处理的聚合管道,每个文档通过一个由多个阶段组成的管道,可以对每个阶段的管道进行分组、过滤等功能,然后经过一系列的处理,输出相应的结果
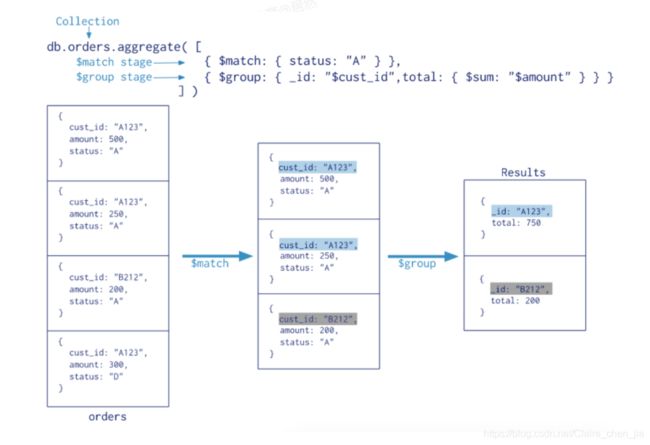
3.1 常用的管道
$group:将集合中的文档分组,可用于统计结果
$match:过滤数据,只输出符合条件的文档
$project:修改输入文档的结构
$sort:将输入文档排序后输出
$limit:限制聚合管道返回的文档书
$skip:跳过指定数量的文档,并返回余下的文档
3.2 表达式
测试数据如下
db.stu.insert({name:"a", hometown: '东北', age: 20, gender: true})
db.stu.insert({name:"b", hometown: '长沙', age: 18, gender: false})
db.stu.insert({name:"c", hometown: '武汉', age: 18, gender: false})
db.stu.insert({name:"d", hometown: '华山', age: 40, gender: true})
db.stu.insert({name:"e", hometown: '山东', age: 16, gender: true})
db.stu.insert({name:"f", hometown: '江苏', age: 45, gender: true})
db.stu.insert({name:"g", hometown: '大理', age: 18, gender: true})
常用表达式:
$sum: 计算总和, $sum:1 表示以⼀倍计数
$avg: 计算平均值
$min: 获取最⼩值
$max: 获取最⼤值
$push: 在结果⽂档中插⼊值到⼀个数组中
$first: 根据资源⽂档的排序获取第⼀个⽂档数据
$last: 根据资源⽂档的排序获取最后⼀个⽂档数据
3.2.1 $group
将集合中的文档分组,课用于统计结果
• _id表示分组的依据,使用某个字段的格式为 ‘$字段’
按照gender分组
db.stu.aggregate(
{$group:{_id:'$gender',count:{$sum:1}}}
)
按照gender分组,获取不同组的平均年龄
db.stu.aggregate(
{$group:{_id:'$gender',count:{$sum:1},avg_age:{$avg:"$age"}}}
)
3.2.2 $match
match是管道命令,能将结果交给后一个管道
查询年龄大于20的学生
db.stu.aggregate(
{$match:{age:{$gt:20}}}
)
查询年龄大于20的男生,女生人数:
db.stu.aggregate(
{$match:{age:{$gt:20}}},
{$group:{_id:'$gender',count:{$sum:1}}}
)
4 MongDB索引操作
(1)用途
• 加快查询速度
• 进行数据的去重
(2)创建简单的索引方法/语法
db.集合名.ensureIndex({属性:1})
1表示升序, -1表示降序
(3)创建索引前后查询速度对比
测试:插入10万条数据到数据库
for(i=0;i<100000;i++){db.test.insert({name:'test'+i,age:i})}
创建索引前
db.test.find({name:'test9999'})
db.test.find({name:'test9999'}).explain('executionStats') # 显示查询操作的详细信息
创建索引
db.test.ensureIndex({name:1})
创建索引后
db.test.find({name:'test9999'}).explain('executionStats')
(4)索引的查看
默认情况下_id是集合的索引
查看方式:db.集合名.getIndexes()
(5)删除索引
语法:db.集合名.dropIndex({'索引名称':1})
db.test.dropIndex({name:1})
db.test.getIndexes()
(6)mongodb创建唯一索引
在默认情况下mongdb的索引域的值是可以相同的,创建唯一索引之后,数据库会在插入数据的时候检查创建索引域的值是否存在,如果存在则不会插入该条数据,但是创建索引仅仅能够提高查询速度,同时降低数据库的插入速度。
- 添加唯一索引的语法
db.集合名.ensureIndex({"字段名":1}, {"unique":true})
- 利用唯一索引进行数据去重
db.t1.ensureIndex({"name":1}, {"unique":true})
db.t1.insert({name: 'test10000'})
(7)建立复合索引
在进行数据去重的时候,可能用一个域来保证数据的唯一性,这个时候可以考虑建立复合索引来实现。
例如:抓全贴吧信息,如果把帖子的名字作为唯一索引对数据进行去重是不可取的,因为可能有很多帖子名字相同
建立复合索引的语法:
db.collection_name.ensureIndex({字段1:1,字段2:1})
(8)建立索引注意点
根据需要选择是否需要建立唯一索引
索引字段是升序还是降序在单个索引的情况下不影响查询效率,但是带复合索引的条件下会有影响
数据量巨大并且数据库的读出操作非常频繁的时候才需要创建索引,如果写入操作非常频繁,创建索引会影响写入速度