第12期DataWhale组队学习作业
第12期DataWhale组队学习作业
一、2002-2018上海机动车拍照拍卖
import pandas as pd
#问题1 哪一次拍卖的中标率首次小于5%
df['中标率']=df['Total number of license issued']/df['Total number of applicants']
df_auction_rate=df[df['中标率']<0.05]
df_auction_rate.head(1)

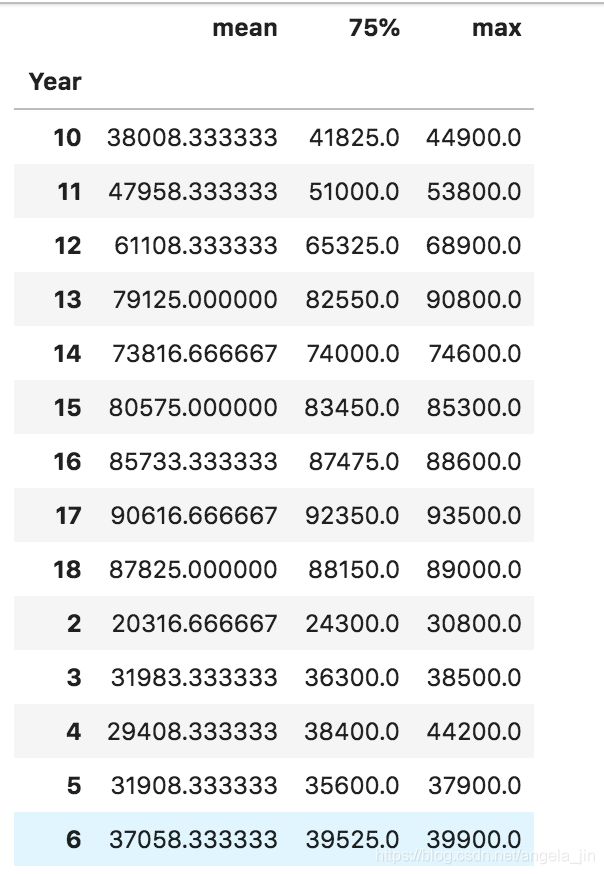
#问题2 按年统计拍卖的最低价的统计量:最大值,均值,0.75分位数,要求显示在同一张表上
df['Year']=''
for i in range(len(df['Date'])):
df["Year"][i]=df["Date"][i][:-4]
a=df.groupby('Year')['lowest price '].describe(percentiles=[.75])
a.drop(columns=['std','min','count','50%'])
#a.agg({'lowest price ':['max','mean','quantile']})
部分输出结果,年份未排序
#问题3 将第一列拆成两列,年份和月份。添加到到一二列
#加入月份列
df['Month']=''
for i in range(len(df['Date'])):
df['Month'][i]=df['Date'][i][-3:]
#加入年份列
y=[]
for item in df['Year']:
item=int(item)+2000
y.append(item)
c={"year" : y}
data=pd.DataFrame(c)
df1=pd.concat([df,data],axis=1) #将年份列加入表格
df1.drop(columns=['中标率','Date','Year'])
df2=df1[['year','Month','Total number of license issued','lowest price ','avg price','Total number of applicants']]
df2

#问题4 多级索引,外层年份,内层为原表格2到5列变量名,列索引为12个月份
#df3=pd.DataFrame(df2, index=['year','Total number of license issued','lowest price ','avg price','Total number of applicants'], columns='Month')
df3=df2.set_index(['year','Total number of license issued','lowest price ','avg price','Total number of applicants'])
df3

#问题5 某月最低价与上月最低价,月均值与上月均值,不满足相同正负号的拍卖时间
df2['delta_lowest']=df2['avg price']-df2['avg price'].shift(1)
df2['delta_avg']=df2['lowest price ']-df2['lowest price '].shift(1)
for i in range(len(df2)):
if df2.loc[i]['delta_lowest']*df2.loc[i]['delta_avg']<0:
print(df2.loc[i]['year'],df2.loc[i]['Month'])
输出结果

#问题6 发行增量:牌照发行量与前两月发行量均值的差额,最初两月为0,求发行增益极值时间
df2['delta_issued']=df2['Total number of license issued']-(df2['Total number of license issued'].shift(1)+df2['Total number of license issued'].shift(2))/2
df2.loc[df2['delta_issued'].idxmax(),['year','Month']]
输出结果

二、2007-2019俄罗斯货运航班运载量
import pandas as pd
df=pd.read_csv('2007年-2019年俄罗斯货运航班运载量.csv')
#问题1 求每年货运航班总运量
df.groupby('Year')['Whole year'].sum()

#问题2 每年记录的机场都是相同的吗
df.groupby('Year')['Airport name'].value_counts()
部分输出结果,可以看出每年机场记录的对应数量,从而确认是不相同的

#问题3 按年计算2010-2015全年货运量为0的机场航班比例
df1=df[(df['Year']>=2010)&(df['Year']<=2015)]
df2=df1.groupby('Year')
for name,group in df2:
print(name)
group[group['Whole year']==0]['Airport name'].count()/group['Airport name'].count()
部分输出结果

#问题4 某机场存在5年或以上,月运量记录为0,将其所有年份记录从表中删除
df_11=df[df['Whole year']==0]
df_22=df_11.groupby('Airport name')['Whole year'].value_counts()
b=list(df_22[df_22.values>=5].index)
c=[]
d=[]
for i in range(len(b)):
c.append(b[i][0]) #将要删除的机场名字放在一个列表中
for i in c: #删除c中的换行符
d.append(i.strip(' '))
df.set_index('Airport name')
df_33=df.drop(index=d)
df_33
#问题5不会,这是问题6
df_rank=df[df['Year']==2016]
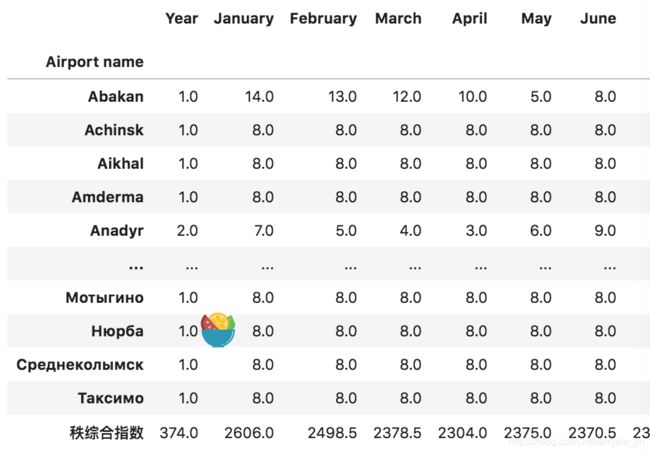
df_rank1=df_rank.groupby(['Airport name']).sum() #显示每个机场每月的货运量综合
df_rank2=df_rank1.rank(axis=1,ascending=False) #对每列进行排名,好像有问题
df_rank2.loc['秩综合指数']=df_rank2.apply(lambda x: x.sum())
df_rank2
部分输出结果,看最后一行,其实感觉计算有点问题,但是逻辑上没毛病,也找不出来哪问题
三、2007-2009俄罗斯机场货运航班运载量
#问题1
df_a=pd.read_csv('美国确证数.csv')
df_b=pd.read_csv('美国死亡数.csv')
df_b['2020/4/26'].corr(df_b['Population'])
df_a.index

#问题2 截至4.1,统计每个州零感染县比例
#新增一列统计感染数量
df_a['感染总数4.1']=df_a.iloc[:,11:81].apply(lambda x: x.sum(), axis=1)
a=df_a.groupby('Province_State')
for name,group in a: #计算比例
print(name)
group[group['感染总数4.1']==0]['Admin2'].count()/group['Admin2'].count()

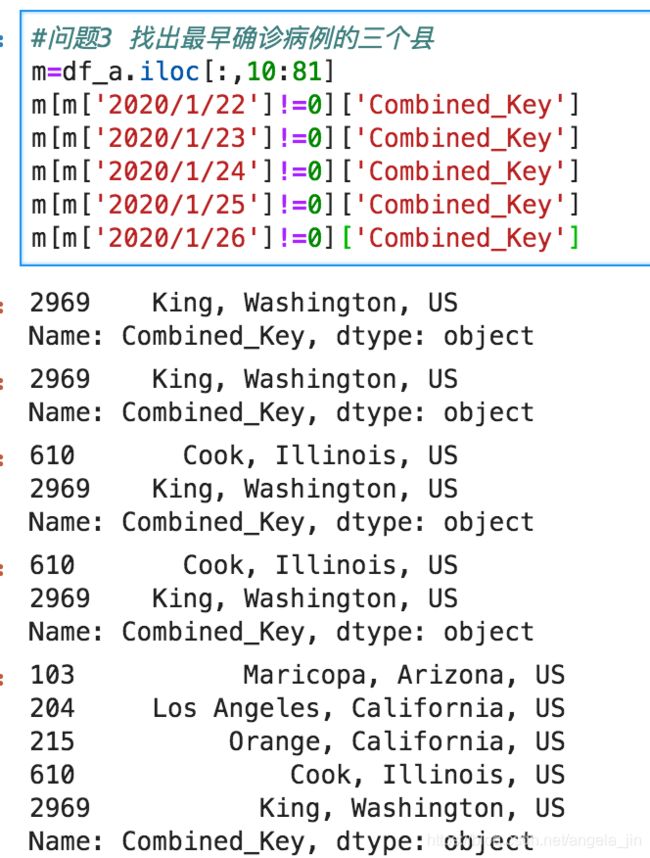
#问题3 找出最早确诊病例的三个县
m=df_a.iloc[:,10:81]
m[m['2020/1/22']!=0]['Combined_Key']
m[m['2020/1/23']!=0]['Combined_Key']
m[m['2020/1/24']!=0]['Combined_Key']
m[m['2020/1/25']!=0]['Combined_Key']
m[m['2020/1/26']!=0]['Combined_Key']
输出结果,可以看到每天有确诊病例的城市
#问题4 按州统计单日死亡增加数,哪个州在哪一天确诊数增加最大
death=df_b.groupby('Province_State')
m=[]
for name,group in death:
group.loc['sum']=group.apply(lambda x: x.sum()) #计算每州每日死亡人数
for i in range(12,len(group.columns)):
#计算每州单日死亡增加数
group.iloc['delta_sum']=group.iloc[-2:-1,i+1]-group.iloc[:-1,i]
group[-2:-1].max() #计算每州单日死亡增加数最大值
问题4只写出一部分,问题5和6不会