讲解ConcurrentHashMap,分段锁机制
ConcurrentHashMap简解(1.7)
继承关系:
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, Serializable {
private static final long serialVersionUID = 7249069246763182397L;
成员变量:
static final int DEFAULT_INITIAL_CAPACITY = 16;//初始容量为16
static final float DEFAULT_LOAD_FACTOR = 0.75f;//负载因子为0.75
static final int DEFAULT_CONCURRENCY_LEVEL = 16;//默认并发度为16(就是初始容量的大小,一旦指定了,就不能更改大小了),就是16个线程可以同时进行操作
static final int MAXIMUM_CAPACITY = 1 << 30;//Segment的最大容量
static final int MAX_SEGMENTS = 1 << 16;
static final int RETRIES_BEFORE_LOCK = 2;
final Segment<K,V>[] segments;//存储数据的容器
底层结构:
数组+数组+链表
如下图:
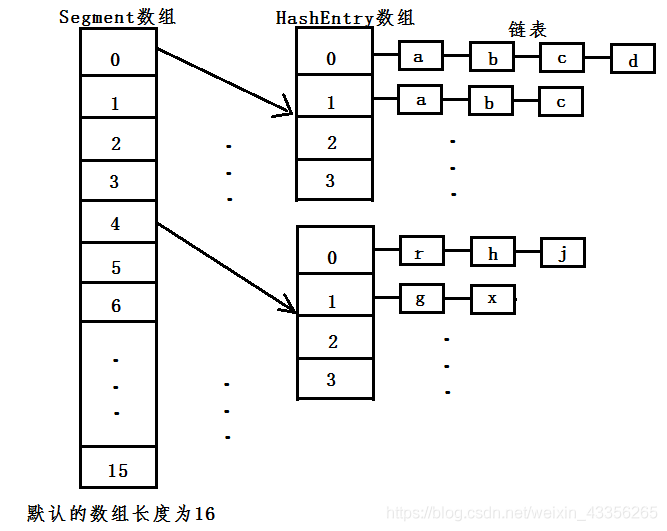
final Segment<K,V>[] segments;
transient Set<K> keySet;
transient Set<Map.Entry<K,V>> entrySet;
transient Collection<V> values;
构造方法:
public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {//带参数的构造函数:初始容量,负载因子,并发度
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
segmentShift = 32 - sshift;
segmentMask = ssize - 1;
this.segments = Segment.newArray(ssize);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = 1;
while (cap < c)
cap <<= 1;
for (int i = 0; i < this.segments.length; ++i)
this.segments[i] = new Segment<K,V>(cap, loadFactor);
}
public ConcurrentHashMap(int initialCapacity, float loadFactor) {//带有参数的构造函数,初始容量,负载因子
this(initialCapacity, loadFactor, DEFAULT_CONCURRENCY_LEVEL);
}
public ConcurrentHashMap(int initialCapacity) {//带有参数的构造函数,初始容量
this(initialCapacity, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
public ConcurrentHashMap() {//无参构造函数,使用默认值调用三参数的构造函数
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
基本操作:
读操作:
因为读操作不会改变数值的大小,所以它是不加锁的,而且HashEntry加了volatile关键字,也可以保证读取到的值是最新值
同时读操作可以多个线程进行操作,即至少可以有16个线程操作,至多无上限,只要在CPU的能力承受范围内即可。

V get(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
return null;
}
写操作:
它是具有锁机制的,可以同时让16(默认容量的)个线程进行操作,每个线程进入各自所需寻找的Segment数组中的HashEentry数组进行操作,大大的提高了操作效率。
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
ConcurrentHashMap的主要特点:
1.存储方面采用了数组加数组加链表的形式
2.在线程对每部分的Segment段读取数据时,可以多个线程访问,效率较高;在线程对每部分的Segment段写数据时,加锁机制启动,只许一个进入,线程安全
3.安全性方面采用了分段的锁机制机,即保证了多线程的安全性,又提高了访问的效率
HashMap、HashTable和ConcurrentHashMap的区别?
1.底层结构
HashMap是数组加链表
HashTable是数组加链表
ConcurrentHashMap是数组加数组加链表
2.扩容
HashMap是初始容量右移一位加一
HashTable是初始容量右移一位
ConcurrentHashMap是初始的Segment数组保持不变,只将HashEntry的数组进行扩容
3.继承关系
HashMap是继承于 extends AbstractMap
HashTable是继承于extends Dictionary
ConcurrentHashMap是继承于 extends AbstractMap
4.在线程安全方面:
HashMap在单线程下是安全的,多线程下不安全,
HashTable在多线程下是安全的,因为它在基本操作前面都加上了synchronized锁,即就是就算在多个线程操作的时候,只要有一个线程进入了基本方法内,其他的线程就必须等待。只有当第一个线程操作结束,释放了锁,其他的线程才可以进行操作。虽然说在多线程操作的时候线程是安全的但是效率比较低,毕竟那么多的线程就在等一把锁。 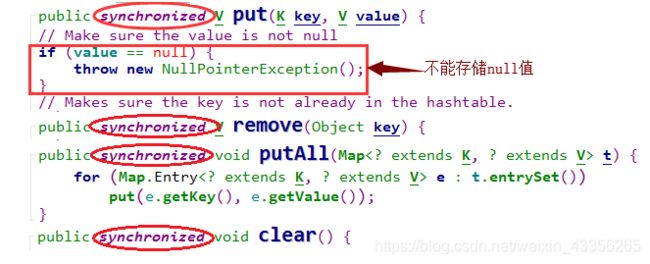
ConcurrentHashMap是安全的,理由上方可寻