数据结构课程设计:基于不同策略的英文单词的词频统计和检索系统
北京林业大学2019年数据结构课程设计
目录
实验要求
代码展示
界面展示
函数列表
实验报告及总结
问题与解决方法
尚存在的问题
总结
核心代码
各种数据结构的对比
收获和体会
实验要求
实习题目: 基于不同策略的英文单词的词频统计和检索系统
实习环境:
实习内容:
一篇英文文章存储在一个文本文件中,然后分别基于线性表、二叉排序树和哈希表不同的存储结构,完成单词词频的统计和单词的检索功能。同时计算不同检索策略下的平均查找长度ASL,通过比较ASL的大小,对不同检索策略的时间性能做出相应的比较分析(比较分析要写在实习报告中的“收获和体会”中)。
实习要求
1. 读取一篇包括标点符号的英文文章(InFile.txt),假设文件中单词的个数最多不超过5000个。从文件中读取单词,过滤掉所有的标点。
2. 分别利用线性表(包括基于顺序表的顺序查找、基于链表的顺序查找、折半查找)、二叉排序树和哈希表(包括基于开放地址法的哈希查找、基于链地址法的哈希查找)总计6种不同的检索策略构建单词的存储结构。
3. 不论采取哪种检索策略,完成功能均相同。
(1)词频统计
当读取一个单词后,若该单词还未出现,则在适当的位置上添加该单词,将其词频计为1;若该单词已经出现过,则将其词频增加1。统计结束后,将所有单词及其频率按照词典顺序写入文本文件中。其中,不同的检索策略分别写入6个不同的文件。
基于顺序表的顺序查找--- OutFile1.txt
基于链表的顺序查找--- OutFile2.txt
折半查找--- OutFile3.txt
基于二叉排序树的查找--- OutFile4.txt
基于开放地址法的哈希查找--- OutFile5.txt
基于链地址法的哈希查找--- OutFile6.txt
注:如果实现方法正确,6个文件的内容应该是一致的。
(2)单词检索
输入一个单词,如果查找成功,则输出该单词对应的频率,同时输出查找成功的平均查找长度ASL和输出查找所花费的时间。如果查找失败,则输出“查找失败”的提示。
实习提示
不同的检索策略所采取的数据结构不一样,算法实现的过程不一样,但查找结果是一样的。
下面给出系统运行的部分参考截图。
主页面结果如图1所示。
图1
对于图1,选择1后进入“基于线性表的查找”,结果如图2所示。
图2
对于图2,选择1后进入“顺序查找”,结果如图3所示。
图3
对于图3,选择1后进入“基于顺序表的顺序查找”,结果如图4所示。
图4
对于图4,选择1后进入“词频统计”,完成词频统计功能。要求统计出所有单词的总数和每个单词的词频。统计结果全部输出到对应的文件OutFile1.txt中,该文件中的数据总计n+1行 ,第一行n为所有单词的总数,后面n行为每个单词及其出现的频率(单词和频率用空格分隔)。
文件OutFile1.txt的示例如图5所示。
图5
对于图4,选择2后进入“单词查找”,输入待查找的单词后,如果查找成功,结果如图6所示。首先显示此单词的词频,之后分别给出查找该单词所花的时间(单位为毫秒或微秒或纳秒,可以利用高精度的时间函数做计算来实现)和平均查找长度。如果查找失败,结果如图7所示。
图6
图7
对于其他5种检索策略,查找结果同图6或图7所示,只是在查找成功时所花的时间和平均查找长度不同而已。
选做内容:
1. 用窗体版界面取代控制台界面。
2. 程序中所用的到排序算法选用先进的排序算法(快速排序或归并排序或堆排序)。
3. 实现低频词过滤功能,要求将出现频率(词频/单词总数)低于10%的单词删除,可以选择不同的存储结构分别实现。
(1)顺序表
(2)链表
(3)二叉排序树
(4)基于开放地址法的哈希表
(5)基于链地址法的哈希表
实习任务阶段性安排
周一:
- 明确实习任务和要求,理解相关算法实现方案
- 实现主要的界面及界面之间的跳转(力求满足界面友好性)
- 实现基于顺序表的顺序查找(即完成图1--7的所有功能)
周二:
- 实现线性表、二叉排序树的所有功能
周三:
- 实现哈希表的所有功能
周四:
- 完善系统
- 对整个系统功能进行测试
- 改进程序(力求程序满足正确性、可读性、健壮性、高效性)
代码展示
#include
#include
#include
#include
#include
#include
#include //要用到格式控制符
#define MAXSIZE 5000
#define m 5000 //哈希表的表长
#define NULLKEY " " //单元为空的标记
using namespace std;
int t;//单词总数
int factnum;//去重后单词数
string str[MAXSIZE];//存放单词
int fre[MAXSIZE];//存放词频
int flag[MAXSIZE];//标记第一次出现的位置
double rate[MAXSIZE];
int setrate=100;//万分之100以下的单词过滤
int setrate2;
typedef struct{
string key;
int Time;
}Word;
typedef struct{
Word *R;
int length;
}SSTable;
typedef struct LNode
{
Word data;
struct LNode *next;
}LNode,*LinkList;
typedef struct BSTNode
{
Word data;
struct BSTNode *lchild,*rchild;
}BSTNode,*BSTree;
BSTree T1;//
struct HashTable{
string key;
int Time;
};
typedef struct WordNode//单词结点
{
Word data;
struct WordNode *nextarc;
}WordNode;
typedef struct LetterNode//首字母表头结点
{
int letter_no;//ch
WordNode *firstarc;
}LetterNode,AdjList[38];//?
typedef struct
{
AdjList Letter;//Letter
}ALGraph;//邻接表
int Hash_int(int a)
{
int p;
p=str[a][0];
p=p-96;
return p;
}
void InitTree(BSTree &T)
{
T=new BSTNode;
T=NULL;
return;
}
void Insert(BSTree &T,Word e)
{
if(!T)
{
//建立一个根节点指针S并开辟存储空间
BSTree S;
S=new BSTNode;
//为新结点S赋值
S->data=e;
//初始化孩子左右结点为空
S->lchild=S->rchild=NULL;
T=S; //S赋值给T
}
else if(e.keydata.key)//如果待插入元素小于根节点,插入左边
Insert(T->lchild,e);
else if(e.key>T->data.key)//大于,右边
Insert(T->rchild,e);
}
int Input3(BSTree &T,string key){
int n=0;
if(T==NULL)return -1;
while(T!=NULL&&key!=T->data.key)//非递归遍历
{
n++;
if (keydata.key)
T=T->lchild;
else
T=T->rchild;
}
if(T==NULL)return -1;
if(key==T->data.key)
{
T->data.Time++;
return n;
}
}
int Search5(BSTree &T,string key){
int n=0;
if(T==NULL)return -1;
while(T!=NULL&&key!=T->data.key)
{
n++;
if (keydata.key)
T=T->lchild;
else
T=T->rchild;
}
if(T==NULL)return -1;
if(key==T->data.key)
{
return n;
}
}
void InputTree(BSTree &T)
{
int i=1;
//建立一颗空树
T=NULL;
//建立一个word结点,先赋值,便于录入
Word e;
e.key=str[1];
e.Time=1;
while(idata.Time++;//不行
//下一次的输入
i++;
e.key=str[i];
e.Time=1;//初次输入,词频都为1
}
}
int TraverseOut(BSTree T)
{
fstream out;
out.open("OutFile3.txt",ios::app);
if(T)
{
TraverseOut(T->lchild);
//cout<data.key<<" "<data.Time<data.key<<" "<data.Time<rchild);
}
return 0;
}
int TraverseOut2(BSTree T)
{
if(T)
{
TraverseOut2(T->lchild);
cout<data.key<<" "<data.Time<rchild);
}
return 0;
}
void Output3(BSTree T)
{
int i;
fstream out;
out.open("OutFile3.txt",fstream::out | ios_base::trunc);
out<<"单词 词频"<>ch;
BSTree temp;
InitTree(temp);
temp=T;
LARGE_INTEGER fr;
LARGE_INTEGER st;
LARGE_INTEGER ed;
double time;
QueryPerformanceFrequency(&fr);
QueryPerformanceCounter(&st);
int res=Search5(temp,ch);
QueryPerformanceCounter(&ed);
time = (double)(ed.QuadPart - st.QuadPart) / (double)fr.QuadPart;
if(res!=-1)
{
cout<<"此单词的词频为:"<data.Time<data.Time<'9'&&!CheckSqList(L,str[i])))//不重复录入
{
L.length++;
L.R[L.length].key=str[i];
L.R[L.length].Time=1;//不能++
//标记位置
flag[i]=1;
}
else if((str[i][0]<'0'&&CheckSqList(L,str[i]))||(str[i][0]>'9'&&CheckSqList(L,str[i])))//重复就只统计
{
L.R[CheckSqList(L,str[i])].Time++;//词频统计
}
i++;
}
}
void Rate1(SSTable L)
{
fstream out;
out.open("OutFile1.txt",fstream::out | ios_base::trunc);
int i=0;
cout<<"单词"<<" "<<"频次"<<" "<<"概率(万分之一)"<setrate)//&&rate[i]<100000
{
out<next){//遍历单链表
i++;
p=p->next;
if(p->data.key==a)
{
p->data.Time++;//有重复,频率加1
// cout<<"有重复,位置为"<next=NULL;
r=L;
for(i=1;i<=t;i++)
{
if(Locate(L,str[i])==0)
{
//未重复的部分,也就是第一次录入的部分
p=new LNode;
p->data.Time=1; //结点初始化频次为1
p->data.key=str[i];
p->next=NULL;
r->next=p;
r=p;
}
}
return;
}
void Rate2(LinkList L)
{
fstream out;
out.open("OutFile1.txt",fstream::out | ios_base::trunc);
LinkList p=L->next;
//利用顺序表计算单词概率
int i=1;
cout<<"单词"<<" "<<"频次"<<" "<<"概率"<data.Time;
rate[i]=(double)fre[i]/t;
rate[i]=rate[i]*10000;
if(rate[i]>setrate)
{
out<data.key<<" "<data.key<<" "<next) p=p->next;
else break;
}
i++;
}
}
int InitList(LinkList &L)
{
LinkList p=L;
while(p->next){
p=p->next;
p->data.Time=1;
}
return 0;
}
int ListLength(LinkList L)
{
LinkList p;
p=L->next; //p指向第一个结点
int i=0;
while(p){//遍历单链表,统计结点数
i++;
p=p->next;
}
return i;
}
void Sort2(LinkList &L)
{
int n=ListLength(L);
int i; //用i记录已经比好,置于末尾的元素
int j;//用j记录已比较的轮次
LinkList p;
for(i=0;inext;
j=0;//比较完一轮后,j归零
while(p&&jdata.key > p->next->data.key)
{
Word t=p->data;
p->data=p->next->data;
p->next->data=t;
}
p=p->next;
j++;
}
}
return;
}
void Output2(LinkList &L)
{
int i;
fstream out;
out.open("OutFile2.txt",fstream::out | ios_base::trunc);
out<<"单词 词频"<next;
while(p)
{
out<data.key<<" "<data.Time<next;
}
return;
}
void Search2(LinkList L)
{
Output2(L);
cout<<"基于链式存储结构,请输入你要查找的单词:" <>ch;
LARGE_INTEGER fr;
LARGE_INTEGER st;
LARGE_INTEGER ed;
double time;
QueryPerformanceFrequency(&fr);
QueryPerformanceCounter(&st);
LinkList p;
p=L;
int i=0;
while(p->next)
{
p=p->next;
if(p->data.key==ch)
{
QueryPerformanceCounter(&ed);
time = (double)(ed.QuadPart - st.QuadPart) / (double)fr.QuadPart;
cout<<"此单词的词频为:"<data.Time<next)
{
p=p->next;
if(p->data.key==ch)
{
QueryPerformanceCounter(&ed);
time = (double)(ed.QuadPart - st.QuadPart) / (double)fr.QuadPart;
cout<<"此单词的词频为:"<data.Time<>str[i];
int j=str[i].length();//单词字母数
//首字母大写转为小写
for(int n=0;n='A'&&str[i][n]<='Z')
str[i][n]=str[i][n]+32;
}
//非字母字符标记统计
int num=0;
for(int n=0;n'z')
{
//cout<<"非字母:"<800)cout<<"注意:当前单词数量过多,可能导致程序崩溃"<800)cout<<"注意:当前单词数量过多,可能导致程序崩溃"<800)cout<<"注意:当前单词数量过多,可能导致程序崩溃"<= x.key) // 从右向左找第一个小于x的数
j--;
if(i < j)
L.R[i++] = L.R[j];
while(i < j && L.R[i].key < x.key) // 从左向右找第一个大于等于x的数
i++;
if(i < j)
L.R[j--] = L.R[i];
}
L.R[i] = x;
QuickSort1(L, l, i - 1); // 递归调用
QuickSort1(L, i + 1, r);
}
}
void Sort1(SSTable &L)
{
int i=0,j=0;//外i内j
for(i=1;i<=L.length;i++)//外层循环n-1
for(j=1;j<=L.length-i;j++)//内层循环n-1-i
{
if(L.R[j].key>L.R[j+1].key)
{
Word temp;
temp=L.R[j];
L.R[j]=L.R[j+1];
L.R[j+1]=temp;
}
}
}
void Del1(SSTable &L,int no)
{
no=no+1;
int i;
if(no>L.length||no<1)
{
cout<<"Sorry,the position to be deleted is invalid!"<ListLength(L)||no<1)
{
cout<<"Sorry,the position to be deleted is invalid!"<next;
j++;
}
q=p->next;
p->next=q->next;
delete q;
return;
}
void DelLowRate2(LinkList &L)
{
cout<<"删除前表长:"<next)
{
i++;
p=p->next;
if(10000*(double)p->data.Time/t<100)
{
Del2(L,i);
i--;//key
}
}
cout<<"删除后表长:"<next)
{
p=p->next;
if(10000*(double)p->data.Time/t)
{
cout<<"剩余"<data.key<<" "<data.Time<<" "<<10000*(double)p->data.Time/t<rchild==NULL)
{
q = p; p = p->lchild; free(q);cout<<"删除完成1"<lchild==NULL)
{
q = p; p = p->rchild; free(q);cout<<"删除完成2"<lchild;
while (s->rchild)
{
q = s; s = s->rchild;
}
p->data = s->data;
if (q != p)
q->rchild = s->lchild;
else
q->lchild = s->lchild;
free(s);
cout<<"删除完成3"<data.key)
{
return Delete(T);
}
else if (keydata.key)
{
return DeleteBST(T->lchild,key);
}
else
{
return DeleteBST(T->rchild,key);
}
}
}
void DeleteBST2(BSTree &T,string key) {
//从二叉排序树T中删除关键字等于key的结点
BSTree p=T;BSTree f=NULL; //初始化
BSTree q;
BSTree s;
while(p)
{
if (p->data.key == key)
{
break;
}
f=p;
if (p->data.key> key)
{
p=p->lchild;
}
else
{
p=p->rchild;
}
}
if(!p)
{
return;
}
if ((p->lchild)&& (p->rchild))
{
q = p;
s = p->lchild;
while (s->rchild)
{q = s; s = s->rchild;}
p->data = s->data;
if(q!=p)
{
q->rchild = s->lchild;
}
else q->lchild = s->lchild;
delete s;
}//if
else
{
if(!p->rchild)
{
q = p;
p = p->lchild;
}//else if
else if(!p->lchild)
{
q = p; p = p->rchild;
}//else if
if(!f)
{
T=p;
}
else
{
if (q==f->lchild)
{
f->lchild = p;
}
else
{
f->rchild = p;
}
}
delete q;
}
}//DeleteBST
int DelLowRate3(BSTree &T)
{
if(T)
{
DelLowRate3(T->lchild);
if(10000*T->data.Time/t>100)
{
string key1=T->data.key;
//DeleteBST(T,key1);
Insert(T1,T->data);//Word e
factnum++;
}
else
{
// cout<<"保留:"<data.key<<" "<<10000*(double)T->data.Time/t<rchild);
}
return 0;
}
void MenuLinearList(SSTable &L)
{
//菜单
system("cls");
PrintMenu1();
char ch;
cin>>ch;
//Sort1(L);
QuickSort1(L,1,L.length);
Output1(L);//输出
string sk;
switch(ch)
{
case '1': cout<<"顺序查找,输入你要查找的单词:"<>sk;
Search1_Order(L,sk);system("pause");system("cls");break;
case '2': cout<<"折半查找,输入你要查找的单词:"<>sk;
Search1_Half(L,sk);system("pause");system("cls");
break;
case '3': DelLowRate1(L);system("pause");system("cls");break;
case '4': return;
}
}
int Hash(string key)
{
int n;
n=key[0]-'a';//用ASCII码作差,计算首字母的序号
int result=100*n;//每一个字母分配100个数组空间,a序号就是0,空间为0-100.
return result;
}
int Search4(HashTable HT[],string key){
//在哈希表中查找,若查找成功,返回序号,否则返回-1
int H0=Hash(key); //计算哈希地址
int Hi;
if (HT[H0].key==NULLKEY) return -1; //若单元H0为空,则所查元素不存在
else if (HT[H0].key==key) return H0; //若单元H0中元素的关键字为key,则查找成功
else{
for(int i=1;i= x.key) // 从右向左找第一个小于x的数
j--;
if(i < j)
HT[i++] = HT[j];
while(i < j && HT[i].key < x.key) // 从左向右找第一个大于等于x的数
i++;
if(i < j)
HT[j--] = HT[i];
}
HT[i] = x;
QuickSort(HT, l, i - 1); // 递归调用
QuickSort(HT, i + 1, r);
}
}
void Sort4(HashTable HT[])
{
int i=0;int j;int res=0;
for(i=0;i<=26;i++)
{
for(j=i*100+1;j<(i+1)*100;j++)
{
if (HT[j].key=="\0")
{
res=j;
break;
}
}
QuickSort(HT,i*100+1,res);//不能为(i+1)*100,因为后面都是空,只能到res
}
return;
}
void Output4(HashTable HT[])
{
int i;
fstream out;
out.open("OutFile4.txt",fstream::out | ios_base::trunc);
out<<"单词 词频"<>sk;
LARGE_INTEGER fr;
LARGE_INTEGER st;
LARGE_INTEGER ed;
double time;
QueryPerformanceFrequency(&fr);
QueryPerformanceCounter(&st);
int result=Search4(HT,sk);
QueryPerformanceCounter(&ed);
time = (double)(ed.QuadPart - st.QuadPart) / (double)fr.QuadPart;
if(result!=-1)
{
cout<<"此单词的词频为:"<data.key<<" "<data.Time<nextarc;
}
}
out.close();
return;
}
void Sort5(ALGraph &G)
{
int i;
for(i=1;i<=26;i++)
{
WordNode *p,*q;
Word t;
for (p=G.Letter[i].firstarc; p!=NULL; p=p->nextarc)
{
for(q=p->nextarc; q!=NULL; q=q->nextarc)
{
if(p->data.key>q->data.key)
{
t=q->data;
q->data=p->data;
p->data=t;
}
}
}
}
return;
}
void HashChainAddress(ALGraph G,string sk)
{
cout<<"基于链地址法:"<data.key==sk)
{
flag=j;
r=h->data.Time;
}
h=h->nextarc;
}
QueryPerformanceCounter(&ed);
time = (double)(ed.QuadPart - st.QuadPart) / (double)fr.QuadPart;
if(flag>0)
{
cout<<"此单词的词频为:"<data.key=str[i];
p->data.Time=fre[i];
p->nextarc=NULL;
G.Letter[k].firstarc=p;
num++;
}
else
{
int flag=0;
while(h!=NULL)
{
r=h;
if(h->data.key==str[i])//遍历一个首字母的链表,如果相同,频次自加
{
h->data.Time++;
flag=1;
}
h=h->nextarc;//
}
if(flag==0)//如果没有相同的,就录入
{
p=new WordNode;
p->data.key=str[i];
p->data.Time=fre[i];
p->nextarc=NULL;
r->nextarc=p;
num++;
}
}
}
factnum=num;//有效单词数
return;
}
void MenuHash(HashTable HT[],ALGraph G)
{
//菜单
system("cls");
PrintMenu4();
char ch;
cin>>ch;
string sk;
switch(ch)
{
case '1': HashOpenAddress(HT);system("pause");system("cls");break;
case '2': cout<<"链地址法,输入你要查找的单词:"<>sk;
HashChainAddress(G,sk);system("pause");system("cls");
break;
case '3': return;
}
}
void PrintMenu7()
{
cout<<"基于不同策略的英文单词的词频统计和检索系统"<800)cout<<"注意:当前单词数量过多,可能导致程序崩溃"<lchild,i);
i++;
if(10000*(double)T->data.Time/tdata.key<<" "<data.Time<data.key<<" "<data.Time<<"/"<data.Time/t<rchild,i);
}
return 0;
}
void Rate3(BSTree T)
{
int i=0;
cout<<"单词"<<" "<<"频次"<<" "<<"概率(万分之一)"<setrate)
{
out<data.Time/t>setrate)
{
out<data.key<<" "<data.Time<data.key<<" "<data.Time<<"/"<data.Time/t<nextarc;
k++;
}
}
return;
}
void Rate6(SSTable L)
{
cout<<"请输入筛选的概率区间:"<>setrate>>setrate2;
int i=0;//fre[5]=1;
cout<<"单词"<<" "<<"频次"<<" "<<"概率(万分之一)"<setrate&&rate[i]>ch;
string sk;
switch(ch)
{
case '1': Rate1(L);system("pause");system("cls");break;
case '2': Rate2(L1);system("pause");system("cls");break;
case '3': Rate3(T);system("pause");system("cls");break;
case '4': Input4(HT);system("pause");system("cls");Sort4(HT);Rate4(HT);break;
case '5': Rate5(G);system("pause");system("cls");break;
case '6': Rate6(L);system("pause");system("cls");break;
}
}
void Compare(SSTable L,LinkList L1,BSTree T,HashTable HT[],ALGraph G)
{
cout<<"请输入您要查找的单词:"<>sk;
Sort1(L);
Sort2(L1);
Sort4(HT);
Sort5(G);
Search1_Order(L,sk);cout<>ch;
switch(ch)
{
case '1':MenuLinearList(L);break;
case '2':Search2(L1);system("pause");system("cls");break;break;
case '3':Search3(T);system("pause");system("cls");break;break;
case '4':MenuHash(HT,G);break;
case '5':cout<<"单词总数:"<
界面展示

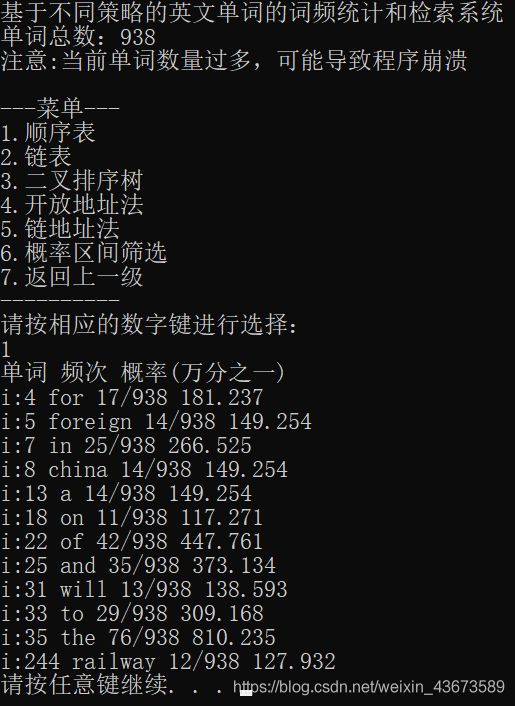

函数列表
实验报告及总结
问题与解决方法
- 递归函数中读文件,每递归一次就要建立一个流对象,能行吗?没关系。用ios::app,文件指针保留在上次读的位置,可以接着读。
- 为什么二叉树要初始化?不初始化会怎么样?什么是初始化?初始化,就是第一次赋值。任何一个变量在使用之前必须要先对它进行初始化。不初始化的话使用它就没有实际意义了。在实际编程中,习惯上在定义变量的时候就对它进行初始化,这是一个很好的编程习惯。
- 怎么对输入的字符进行处理?预处理环节先读文件,把单词读进一个(字符串)单词数组。同时对当前字符串进行处理,先把所有大写字母变为小写字母。再把标点符号,数字等不是小写字母的字符替换为#号,冒泡排序,依次把#号往后挪动,挪动至字符串末尾,这个过程中,记录#号个数,再通过字符串函数substr将其去除。
尚存在的问题
窗体还没写。每个句子之间必须隔开,有一个空格。
总结
- 函数的命名一定要规范,有的同学用拼音来命名,代码很难读。
- 写代码的时候,快速定位错误位置和原因很重要。不会调试,用cout这个笨办法可以逐步查错。
- 注意数组的开始位置,是1还是0。
- 注意比较大小的时候,到底有没有等号。
- 注意函数的传给参数到底是从1开始,还是从0开始,是位置序号,还是数组下标。
- 程序的逻辑至关重要
- 每种返回值代表的含义不要混淆用反,以保证后续的操作正确。
- 写程序之前,建议先写出这个函数的伪代码。
- 查重和搜索不能用同一个函数,查重函数肩负着统计频次的功能,而搜索函数不用。
- 二叉排序树的查重函数,运用递归思想,遍历树的同时,将不断的改变树的根节点,所以在使用这个函数的时候,要新建一个临时的树,初始化,保存当前树的数据,用这个临时的树进行搜索。
BSTree temp;
InitTree(temp);
temp=T;
int res=InputCheck3(temp,str[i]);- 在数组的数据结构中,要想对数据的进行修改,就必须知道数据的位置。比如,一个非数组结构的单词结点,比如链表,二叉树,再查重函数结束之后,将无法得知结点的位置,就算知道结点的位置,也不方便对该结点进行修改,因为要再次遍历。所以,在查重的时候,就应该顺便对结点的频次数据进行加1的修改。
- 录入多个单词并统计频率
Int 查重函数() { 如果重复,频率加1,返回一个标记值。 如果不重复,返回另一个标记值 } While(未录入完毕) { If(查重函数说没有重复) { 录入新单词; 设置单词频率为1; } } -
在对链表进行遍历操作的时候,建立一个临时的指针,让它等于待操作链表,防止对原链表进行修改。
-
对于自加的变量,一定要先进行初始化。p->data.Time++;
- 对于循环中的一个自加变量,一定要注意是否多加了一次,或者少加了一次。
自加变量统计的是循环中的某种操作的次数,可以放操作前面,也可以放操作后面,但是放的位置不对,就有可能导致统计的错误。这种错误很难发现,可能导致数据输入输出的完全错误,甚至导致程序崩溃。int i=1; while(i<=单词总数100) { 输出序号,输出单词; i++; } cout<<"除去数字外,本文一共"<
就比如这个循环,输出单词100个,i最终自加了100次,等于101;
- 循环的条件很重要,循环了多少次,循环内的自加变量就自加多少。
- 对于一个查找过程,可以设置一个标志变量flag
For/while(循环条件)
{
if(找到)
{
flag=1;
break;
}
}
if(flag==1)
{
输出查找成功;
}
else 输出查找失败;印象中,设置标志变量flag并break,可以避免某些查不出来的错误。
- 数组作为函数参数
- 函数声明:
函数类型 函数名(数组类型 数组名[]);
Void OpenAddressing(HashTable HT[]);- 函数调用部分:
函数名(数组名);
OpenAddressing(HT);- Switch的格式
Char ch;
Cin>>ch;
switch(ch)
{
case '1':MenuLinearList(L);break;
case '2':LinkListSearch(L1);break;
case '3':BinaryTreeSearch(T);break;
}Break不能少。
Case后面是单引号。
- 链地址法录入
void Input5(ALGraph &G)
{
int i;
//初始化顶点表
for(i=1;i<=26;i++)
{
G.Letter[i].letter_no=i;
G.Letter[i].firstarc=NULL;
}
int num=0;//单词计数
for(i=0;idata.key=str[i];
p->data.Time=fre[i];
p->nextarc=NULL;
G.Letter[k].firstarc=p;
num++;
}
else
{
int flag=0;
while(h!=NULL)
{
r=h;
if(h->data.key==str[i])//遍历一个首字母的链表,如果相同,频次自加
{
h->data.Time++;
flag=1;
}
h=h->nextarc;//
}
if(flag==0)//如果没有相同的,就录入
{
p=new WordNode;
p->data.key=str[i];
p->data.Time=fre[i];
p->nextarc=NULL;
r->nextarc=p;
num++;
}
}
}
factnum=num;//有效单词数
return;
} 核心代码
void Preprocessing()
{
//读入
fstream in;
in.open("InFile.txt",ios::in);
if(!in)
{
cout<<"Can not open the file!"<>str[i];
int j=str[i].length();//单词字母数
//首字母大写转为小写
for(int n=0;n='A'&&str[i][n]<='Z')
str[i][n]=str[i][n]+32;
}
//非字母字符标记统计
int num=0;
for(int n=0;n'z')
{
//cout<<"非字母:"<
- 单个函数内的非递归遍历,用一个while循环,不断改变根节点T的值
while(T!=NULL&&key!=T->data.key)//非递归遍历
{
n++;
if (keydata.key)
T=T->lchild;
else
T=T->rchild;
} - 常量设置
int t;//单词总数
int factnum;//去重后单词数
string str[MAXSIZE];//存放单词
int fre[MAXSIZE];//存放词频
int flag[MAXSIZE];//标记第一次出现的位置
double rate[MAXSIZE];
int setrate=100;//万分之100以下的单词过滤
int setrate2;- 结构体设置
typedef struct{
string key;
int Time;
}Word;
typedef struct{
Word *R;
int length;
}SSTable;
typedef struct LNode
{
Word data;
struct LNode *next;
}LNode,*LinkList;
typedef struct BSTNode
{
Word data;
struct BSTNode *lchild,*rchild;
}BSTNode,*BSTree;
struct HashTable{
string key;
int Time;
};
typedef struct WordNode//单词结点
{
Word data;
struct WordNode *nextarc;
}WordNode;
typedef struct LetterNode//首字母表头结点
{
int letter_no;
WordNode *firstarc;
}LetterNode,AdjList[5000];//??
typedef struct
{
AdjList Letter;//Letter
}ALGraph;//邻接表- 文件读入格式
fstream in;
in.open("InFile.txt",ios::in);
if(!in)
{
cout<<"Can not open the file!"<- 判断文件是否读取完毕
while(!in.eof())- 写入文件
fstream out;
out.open("OutFile1.txt",fstream::out | ios_base::trunc);- 时间函数
#include
LARGE_INTEGER fr;
LARGE_INTEGER st;
LARGE_INTEGER ed;
double time;
QueryPerformanceFrequency(&fr);
QueryPerformanceCounter(&st);
QueryPerformanceCounter(&ed);
time = (double)(ed.QuadPart - st.QuadPart) / (double)fr.QuadPart; - #include
格式控制符 - 过滤空格
if(str[i][0]=='\0')
{
i--;//如果当前接收的是一个空串,则接受下一个字符串
}
i++;- 数据的初始化
//频率数组初始化
for(i=1;i- 快速排序
void QuickSort1(SSTable &L, int l, int r)//l=1,r=L.length
{
if (l < r)
{
//Swap(s[l], s[(l + r) / 2]); //将中间的这个数和第一个数交换
int i=l, j=r;Word x = L.R[l];
while (i < j)
{
while(i < j && L.R[j].key>= x.key) // 从右向左找第一个小于x的数
j--;
if(i < j)
L.R[i++] = L.R[j];
while(i < j && L.R[i].key < x.key) // 从左向右找第一个大于等于x的数
i++;
if(i < j)
L.R[j--] = L.R[i];
}
L.R[i] = x;
QuickSort1(L, l, i - 1); // 递归调用
QuickSort1(L, i + 1, r);
}
}
- 从1开始的冒泡排序
int i=0,j=0;//外i内j
for(i=1;i<=L.length;i++)//外层循环n-1 +1
for(j=1;j<=L.length-i;j++)//内层循环n-1-i+1
- 较高精度的概率(单位 万分之一)
10000*(double)L.R[i].Time/t- 哈希函数
int Hash(string key)
{
int n;
n=key[0]-'a';//用ASCII码作差,计算首字母的序号
int result=100*n;//每一个字母分配100个数组空间,a序号就是0,空间为1-100.
return result;
}- 对哈希表排序
void Sort4(HashTable HT[])
{
int i=0;int j;int res=0;
for(i=0;i<=26;i++)
{
for(j=i*100+1;j<(i+1)*100;j++)
{
if (HT[j].key=="\0")
{
res=j;
//cout<<"i:"<- 文件流
头文件 include
定义文件流 fstream in
打开 in.open(“1.txt”,ios::in)
打开方式 ios::app 可以从上次读的地方接着读
while(!in.eof()) 没有读到文件的末尾,循环就会继续。 - String
#include
str[i].length();
//字符串可以直接比大小。
str[i][n]>='A'???
str[i][n]=str[i][n]+32;
str[i][n]=35;
//截取字符串的函数
str[i].substr(0,j-num); - 菜单命令
system("pause");
system("cls");- 树的初始化
T=new BSTNode;
T=NULL;
- 树的结构
typedef struct BSTNode
{
Word data;
struct BSTNode *lchild,*rchild;
}BSTNode,*BSTree;
//BSTree 指针
//开辟存储空间用BSTNode- 频次统计
首次录入设置频率为1。设为1是初始化,很重要。
再次录入时,查找数据结构,不录入,频率自加。
- Debug技巧
当程序崩溃时,在程序的不同位置,cout相应的标志。
以检查崩溃的原因。没有输出结果,有以下几种常见原因:
1.死循环
死循环的原因,有函数层层嵌套导致的逻辑错误。
函数A调用函数B,但是函数B里又要调用函数A。
2.未初始化
建立一个二叉树需要先初始化,先有init函数然后才能有create函数。
T=new BSTNode;
T=NULL;3.指针越界
While(p->next)各种数据结构的对比
对于多种数据结构,由2的图中数据可以分析出来,二叉排序树和顺序表的折半查找是最快的,平均查找长度也是最小的。
收获和体会
1672行代码!
一个星期没日没夜的编程,让我深刻地理解了“码农”。
我不算一个聪明和优秀的学生,写得相对慢一些。
一天敲代码17个小时,早上7点半到机房,凌晨回宿舍还在写。实际上大部分时间都在debug。
一个bug的出现,有可能是逻辑错误,也有可能是符号或者语句的错误。
编程的时候逻辑一定要清晰,最好能写出伪代码,这样能大大提高编程效率。
一定要细心细心再细心,任何一个微小的地方,都有可能导致整个程序的崩溃。
比如if语句中的等号(==),不能写成赋值符号(=),最好是把数字写在前面(-1==res)。
对于函数的命名,不要用相同的名字,最好按照菜单的序号,在具体的名字后加数字。用英文名,不要用拼音。
命名应该规范。比如Menu类函数,menu应该放前面。
对于编译器应该有更多的了解。
比如要用时钟函数,需要c++11。Devc++是可以支持c++11的,只需要在设置里改一下就行了。
在最后要特别感谢小双,这次课设是和小双一起在机房完成的。
不论是这次课设,还是平常的时候,她都一直支持、鼓励我坚持下去。
不然我早就转专业,不学计算机了哈哈,还好还好坚持下来了。